 |


WHAT IS ‘BIG DATA’AND HOW IS IT USED IN RESEARCH?
|
|
|
|
WHAT IS ‘BIG DATA’AND HOW IS IT USED IN RESEARCH?
Much has been written about the advent of ‘Big Data’ and how this new technol- ogy will transform how ‘we live, work and think’ (Mayer-Schö nberger and Cukier, 2013). The term Big Data can have a range of meanings, ranging from the volume, velocity and variety of data systems, through the analytic capability or value, or a marketing label, to a sociocultural phenomenon (see boyd and Crawford, 2012; Chan and Bennett Moses, 2017; Kitchin, 2014). The use of Big
Data in social science in general and in criminology in particular is a relatively new trend. As Chan and Bennett Moses (2016) observe, there are two main areas where Big Data has been used for researching crime and justice: first, the use of Big Data such as social media streams as data in criminological research (e. g. Procter et al., 2013; Traunmueller et al., 2014; Watters and Phair, 2012: Williams and Burnap, 2016; Williams et al., 2017); and, second, the use of Big Data for real-time monitoring or to make predictions that can be used for law enforce- ment or criminal justice purposes, such as increasing situational awareness, preventing crime and enhancing efficiency (e. g. Berk and Bleich, 2013; Williams et al., 2013). These categories obviously overlap, and research in the first cate- gory may be applied in the second.
USES OF DATA ANALYTICS IN CRIME PREDICTION
 Predictions about future crimes are considered useful primarily for making decisions about the deployment of police officers and resources, intelligence led policing (pre- dictive policing) and making decisions about whether a person who has been charged or convicted of an offence ought to be granted bail or parole (offender risk management).
Predictions about future crimes are considered useful primarily for making decisions about the deployment of police officers and resources, intelligence led policing (pre- dictive policing) and making decisions about whether a person who has been charged or convicted of an offence ought to be granted bail or parole (offender risk management).
Predictive policing
Predictive policing has been used in at least 48 jurisdictions in the USA as well as in the UK and Europe and some other jurisdictions including Delhi, India and Sao Paolo, Brazil. The term ‘predictive policing’ has been applied to a range of policing practices linked by their claimed ability to ‘forecast where and when the next crime or series of crimes will take place’ (Uchida, 2014: 3871), or which individuals are likely to become offenders or victims in order to ‘change outcomes’ (Beck and McCue, 2009). These predictions can be about ‘places and times with an increased risk of crime’, ‘individuals at risk of offending in the future’, creating ‘profiles that accurately match likely offenders with specific past crimes’ or identifying groups or individuals at risk of becoming victims of crime (Perry et al., 2013: 8–9). Most cur- rent predictive policing programs focus on places and times with an increased risk of crime rather than individuals. Predictive policing is a prediction-led business process consisting of a cycle of activities and decision points: data collection, analy- sis, police operations, criminal response and back to data collection (Perry et al., 2013: 128; see Figure 11. 1).
|
|
|
Predictive policing can involve a variety of tools and techniques, including basic
tools such as Excel, off-the-shelf software and adapted or tailored software, which vary in terms of complexity, comprehensibility and transparency. Prediction models

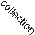










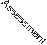
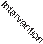


 FIgure 11. 1 The prediction-led policing business process. Copyright RAND included with permission
FIgure 11. 1 The prediction-led policing business process. Copyright RAND included with permission
Source: Perry et al. (2013, p. 128, Figure 5. 4)
might be based entirely or in part on qualitative rather than quantitative methods, including interviews with offenders (e. g. Johnson and Bowers, 2004). Tools usually incorporate geographic information systems so that patterns in the location of crimes over time, as well as relevant geographical features (including the location of licensed venues), can be recorded and tracked. Approaches can be based on classical statistical techniques, on simple methods such as checklists and indices, on complex applications involving Big Data, and/or on tailored methods and data visualization (Perry et al., 2013: 19). In some contexts, automated linguistic analysis of geo- located social media data is used in predictive models (e. g. Gerber, 2014). Commercial products include those provided by organizations such as Motorola, LexisNexis, Esri, Intrado, PredPol, IBM, Information Builders, Azavea, SPADAC, Accenture and Hitachi.
The model on which one product, PredPol, is based is described in Mohler et al. (2011), although the precise model used currently is not publicly available. Like an earthquake prediction model, PredPol assumes that crimes operate as a self-excited point process, with the probability of an event at a particular location being a com- bination of background risk and ‘near repeat’ aftershocks related to recent local events. The variables in the model are calculated through an iterative process.
Figure 11. 2 shows an example of a crime map that was used for predicting crime in Washington, DC.

FIgure 11. 2 Peter Borissov, Forecasting Crime in Washington DC, public domain image on Wikimedia Commons
 The focus on the locations of crime makes predictive policing similar to hot spot policing, the difference being the attempt to predict and account for how hot spots will change over short periods of time. There is extensive research supporting location-based approaches for some categories of crime, particularly burglary (e. g. Bowers et al., 2004). However, not all crime types follow location-based patterns or trends (Hart and Zandbergen, 2012: 58). Thus, a product such as PredPol, based on a ‘near repeat’ model, will be more accurate when predicting some types of crime (such as burglary) than others (such as kidnapping).
The focus on the locations of crime makes predictive policing similar to hot spot policing, the difference being the attempt to predict and account for how hot spots will change over short periods of time. There is extensive research supporting location-based approaches for some categories of crime, particularly burglary (e. g. Bowers et al., 2004). However, not all crime types follow location-based patterns or trends (Hart and Zandbergen, 2012: 58). Thus, a product such as PredPol, based on a ‘near repeat’ model, will be more accurate when predicting some types of crime (such as burglary) than others (such as kidnapping).
|
|
|
