 |


Логический файл - поименованная совокупность всех экземпляров записей заданного типа.
|
|
|
|
Пример логического файла НАЧИСЛЕНИЕ:
| Иванов Иван Иванович |
| Петров Петр Петрович |
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
| Сидоров Сидор Сидорович |
Таким образом, с помощью введенных понятий можно описывать соответствующие данные. Для отображения этих понятий в современных языках программирования, предназначенных как для вычислительных задач, так и для задач обработки данных, введены новые виды данных.
В алгоритмическом языке Паскаль вводится такой вид данных, как запись (RECORD) – сложная переменная с несколькими компонентами, которые могут иметь разные типы. Кроме того, доступ к компонентам записи (полям) осуществляется не по индексу, а по имени. При программировании задачи 1 на языке Паскаль логическая запись НАЧИСЛЕНИЕ представляется видом данных RECORD, набор экземпляров логических записей сотрудников представляется (логический файл) представляется «физическим» файлом, формируемым средствами языка Паскаль и операционной системы..
Salary = RECORD
FIO: string;
O: real;
Ko: real;
S: real;
END;
Отметим важную специфику таких невычислительных задач. Для этих задач характерны большие объемы данных (большое количество сотрудников, большое количество производимых изделий и т. п.). Указанные данные, как правило, используются для решения задачи многократно (зарплата начисляется постоянно каждый месяц), поэтому данные должны достаточно долго храниться в памяти ЭВМ. Для длительного хранения всегда используется внешняя память.
В связи с этим решение задачи 1 состоит из двух этапов.
1. Ввод исходных данных и занесение их во внешнюю память.
type
Salary = RECORD
FIO: string;
|
|
|
O: real;
Ko: real;
S: real;
END;
FSalary = File of Salary;
var
F: FSalary;
…
{ Ввод исходных данных }
repeat
write(‘Введите количество сотрудников (не более’,
MaxN,’): ’);
readln(N);
until (N>0) AND (N<=MaxN);
For I:= 1 to N do
Begin
Write(‘Введите фамилию сотрудника с номером ’,I,‘: ’);
ReadLn(Sotr[i].FIO);
Write(‘Введите оклад сотрудника с номером ’, I, ‘: ’);
ReadLn(Sotr[i].O);
Write(‘Введите кол-во отработанных дней сотрудника с
номером ’, I, ‘: ’);
ReadLn(Sotr[i].Ko);
End;
{ Занесение данных во внешнюю память }
Assign(F, ‘MyFile.fsf’);
Rewrite(F);
For I:= 1 to N do
Write(F, Sotr[i]);
Close(F);
…
2. Чтение исходных данных из внешней памяти, расчет начисленных сумм и вывод на печать.
…
{ Чтение данных из внешней памяти }
Assign(F, ‘MyFile.fsf’);
Reset(F);
For I:= 1 to N do
Read(F, Sotr[i]);
Close(F);
{ Расчет и печать начисленных сумм }
For I:= 1 to N do
Begin
Sotr[i].S:= Sotr[i].O * Sotr[i].Ko / Kr;
WriteLn(Sotr[i].FIO, ‘: ’, Sotr[i].S);
End;
…
Представленные программы решают поставленную задачу при сделанных предположениях. Необходимые для этого данные хранятся в файле MyFile.fsf, предназначенном только для решения этой задачи. Отметим, что в этом случае описание данных включено в прикладную программу. При изменении формата записей файла необходимо изменение прикладной программы. Таким образом, программная система, решающая поставленную задачу, определяет свои собственные данные и управляет ими. Такие программные системы называются файловыми системами [2], [3].
Задача 2. Учет кадрового состава.
Здесь обрабатываются сведения о сотруднике, представленные в карточке СОТРУДНИК:
| Фамилия, имя, отчество FIO | Должность D | Год рождения G | Оклад O | Место жительства M |
Решение задачи состоит из следующих этапов:
Ввод исходных данных и занесение их во внешнюю память.
Чтение исходных данных из внешней памяти с целью удаления, корректировки или добавления записи.
…
{ Чтение данных из внешней памяти }
Assign(F, ‘MyFile.fsf’);
Reset(F);
IsFound:= False;
For I:= 1 to N do
|
|
|
Begin
Read(F, Sotr);
If Sotr.FIO = KeyFio Then
Begin
IsFound:= True;
Sotr.D:= ‘Начальник отдела’;
Seek(F, FilePos(F)-1);
Write(F, Sotr);
Break;
End;
If IsFound Then
WriteLn(‘Корректировка успешно произведена’)
Else WriteLn(‘Сотрудника ’, KeyFio, ‘не обнаружено’);
Close(F);
…
В рассматриваемом случае задача 2 решается независимо от задачи 1.
Задача 3. Учет экономии фонда оплаты труда (ФОТ) в связи с болезнью сотрудников.
Обрабатываются сведения, представленные записями ЭКОНОМИЯ ФОТ:
| Фамилия, имя, отчество FIO | Оклад O | Количество дней на больничном листе K дв | Невыплаченная сумма SN |
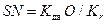 .
.
Программа решения задачи 3 аналогична программе решения задачи 1.
Рассмотрим типичный случай, когда все три вышеуказанные программные системы функционируют в одной организации. Отметим следующие принципиальные эксплуатационные недостатки:
Информация дублируется. В трех файлах присутствуют поля FIO, O, что приводит к существенному перерасходу памяти. При внесении изменений (например, изменении фамилии) приходится вносить одно и то же значение несколько раз в разные файлы, что приводит к увеличению затрат машинного времени. Существует потенциальная возможность противоречивости данных (в один файл изменения внесены, в другой – нет).
Устранить перечисленные недостатки можно, объединив соответствующие записи и создав единую информационную базу для всех вышеназванных задач. На первый взгляд наиболее естественно объединить все записи в одну, убрав дублирующие поля. Получаем возможный вариант объединения:
| FIO | D | O | G | Ko | M | Kдв | S | SN |
Дублирование информации полностью убрано. Расход памяти минимален. Недостатки устранены. Рассмотрим, как в этом случае изменится время решения задач 1–3. Время решения задачи прямо пропорционально объему считываемых из внешней памяти данных.
Обозначим Ti, li, Ni соответственно время решения, длину записи, число записей i -й задачи (i = 1, 2, 3) при использовании отдельных файлов для каждой задачи:
Ti» C* li * Ni,
где C – некоторый коэффициент пропорциональности.
Обозначим Ri, d, N соответственно время решения i -й задачи (i = 1, 2, 3) при использовании файла объединенных записей, длину записи, число записей:
Ri» C* d* N.
Заметим, что N 1 = N 2 = N, N 3 << N.
|
|
|
Тогда время решения i -й задачи (i = 1, 2) при использовании объединенного файла увеличится в Ri / Ti » d / li раз. Для нашего примера время решения задач в зависимости от выбранной длины полей может изменяться в 2–3 раза. Таким образом, платой за исключение дублирования информации является увеличение времени решаемых задач. Заметим, что такое увеличение, как правило, допустимо.
Время решения задачи 3 увеличится в R 3 /T 3 » d*N / l 3 *N 3 раз. Так как для данного примера N 3<< N, то R 3>> T 3. Время решения задачи 3 может увеличиться на несколько порядков, что совершенно недопустимо.
Рассмотрим другой вариант построения единой информационной базы. Объединим записи задач 1 и 2, запись задачи 3 оставим отдельно. Получим два типа записей:
| FIO | D | O | G | Ko | S | M |
| FIO | O | Kдв | SN |
В этом случае дублирование остается (дублируются поля FIO, O). Но так как N 3<< N, то общий объем дублирования незначителен. Время решения задачи 1 и 2 в этом случае незначительно возрастет по сравнению с вариантом отдельных файловых систем, время решения задачи 3 такое же, как и в начальном варианте отдельного файла. Такое объединение позволяет значительно уменьшить влияние недостатков и в то же время существенно увеличивает время решения всех задач. Все три задачи можно решать, используя общую информационную базу из двух типов записей. Отметим, что два приведенных типа записей связаны друг с другом по полю FIO (находятся в некотором отношении). Отметим, что приведенные варианты интеграции не исчерпывают все возможные способы интеграции данных для приведенных задач и к вопросу выбора наилучшего варианта вернемся в последующих лекциях.
Здесь очень важно, что в этом случае для решения вышеуказанных задач используется некоторый новый вид данных, формируемый на основе интеграции записей.
Для описания этого вида данных вводится новое понятие «База данных» [1].
|
|
|
