 |


Нормальные формы отношений
|
|
|
|
Характеристика реляционной модели данных
В основе реляционной модели лежит понятие теоретико-множественного отношения. Это подмножество декартова произведения доменов. Домен – это множество значений, которые может принимать атрибут (множество названий городов, фамилий, организаций и т.д.). Декартово произведение k доменов
(D1 Ä D2 Ä D3 Ä Dk) представляет собой множество всех кортежей вида (A1, A2, A3, …,Ak), где A1ÎD1, A2ÎD2, … AkÎDk.
Отношение (таблица) − подмножество декартова произведения одного или более доменов (рис. 1.20). Строки в отношении называются кортежами (выборками).
Реляционная база данных − это множество связанных между собой отношений, при этом связи между ними задаются с помощью вторичных ключей, т.е. атрибутов отношений (таблиц), которые в каких-то других отношениях являются первичными ключами. Список имен атрибутов называется схемой отношения. Каждое отношение имеет свое имя.
Рис. 1.20. Таблица реляционной базы данных

Отношения обладают следующими свойствами:
- нет одинаковых кортежей, т.е. все записи различаются по уникальному идентификатору – первичному ключу;
- кортежи не упорядочены сверху вниз;
- атрибуты не упорядочены слева направо; в операциях с отношением его строки и столбцы могут просматриваться в любом порядке и в любой последовательности безотносительно к их информационному содержанию и смыслу;
-  все значения атрибутов – скаляры, при этом элементы столбца имеют одинаковую природу (построены на одном домене).
все значения атрибутов – скаляры, при этом элементы столбца имеют одинаковую природу (построены на одном домене).
Такое отношение является нормализованным, т.е. находится в первой нормальной форме.
В отношении столбец или ряд столбцов, значения которых однозначно идентифицируют каждый кортеж, называются ключом. При этом может быть несколько ключей: один первичный, посредством которого осуществляется связывание отношений, а другие – альтернативные. Свойства ключа:
|
|
|
- уникальная идентификация выборки;
- неизбыточность (удаление любого атрибута из ключа лишает его свойства уникальности).
Наряду со смысловым ключом может использоваться инкрементный ключ (счетчик), состоящий из одного поля, которое автоматически наращивается в системе по мере включения новых записей. С точки зрения языка манипулирования данными SQL не имеет значения, применяется инкрементный ключ или смысловой.
Нормальные формы отношений
При проектировании БД стоит задача группировки атрибутов в отношения при условии, что набор возможных отношений заранее не фиксирован. Допускается большое количество различных вариантов, что приводит к проблеме выбора рационального варианта из множества альтернативных схем отношений.
Рациональные варианты группировки атрибутов в отношения должны отвечать следующим требованиям:
1) выбранные для отношений первичные ключи должны быть минимальными;
2)  выбранный состав отношений базы данных должен отличаться минимальной избыточностью атрибутов;
выбранный состав отношений базы данных должен отличаться минимальной избыточностью атрибутов;
3) при выполнении операций включения, удаления и модификации данных в базе не должно возникать трудностей (аномальных явлений);
4) перестройка набора отношений при введении новых типов данных должна быть минимальной;
5) разброс времени ответа на различные запросы должен быть незначительным.
Для оптимального проектирования структуры БД выполняется исследование функциональных зависимостей между атрибутами отношений. Исследование функциональных зависимостей между атрибутами является основой нормализации отношений, т.е. теоретического метода исключения избыточности и усиления целостности (точности и корректности в любой момент времени) реляционной БД.
|
|
|
Функциональная зависимость существует, когда один или более атрибутов уникально определяют другие один или более атрибутов:
X – множество определяющих атрибутов;
Y – множество определяемых атрибутов;
X -> Y.
Существует несколько нормальных форм отношений. Чем выше нормальная форма отношения, тем меньше аномальных явлений может иметь место при ведении базы. Процесс нормализации ведет к разукрупнению отношений.
Первая нормальная форма вытекает из самого определения отношения. Определение второй и третьей нормальных форм основано на исследовании транзитивных зависимостей между атрибутами.
Вторая нормальная форма требует, чтобы в отношении не существовало зависимости каких-либо неключевых атрибутов от части первичного ключа:
K -> T -> A, где
K – ключ;
T – подмножество ключа;
A – неключевой атрибут.
Например: ГРУППА (курс, номер группы, специальность, количество студентов, староста);
номер группы -> специальность.
Имеет место функциональная зависимость неключевого атрибута (специальность) от части ключа (номер группы). В случае изменения номера специальности необходимо просмотреть всю таблицу с изменением соответствующих записей.
Вставить (команда INSERT) информацию по новой специальности нельзя, не вводя информацию по группе; при удалении (команда DELETE) информации по всей группе теряется информация о специальности; при изменении (команда UPDATE) информации по специальности необходимо изменить все соответствующие записи групп.
При нормализации из схемы отношения «ГРУППА» извлекается атрибут «специальность» и выводится в отдельное отношение. Получается отношение во второй нормальной форме:
ГРУППА (курс, номер группы, количество студентов, староста);
СПЕЦИАЛЬНОСТЬ_ГРУППА (номер группы, специальность).
Переход от первой нормальной формы ко второй нормальной форме осуществляется расщеплением исходного отношения по принципу: атрибуты, функционально зависящие от одного из ключевых атрибутов, образуют с ним отношение с единственным ключом, а остальные атрибуты, которые полностью зависят от ключа, остаются в исходном отношении. При этом целостность базы будет поддерживать легче, уменьшается вероятность аномальных явлений при ее модификации.
|
|
|
Третья нормальная форма требует, чтобы не существовало транзитивных связей между неключевыми атрибутами (каждый кортеж состоит из первичного ключа и взаимно независимых атрибутов, описывающих сущность):
K -> Y -> A, где
K – ключ;
Y, A – неключевые атрибуты.
Например: РАСПИСАНИЕ (курс, номер группы, день недели, пара, предмет, преподаватель, аудитория);
предмет -> аудитория.
Имеет место функциональная зависимость между неключевыми атрибутами «предмет» и «аудитория» (будем считать, что аудитория закреплена за определенным предметом).
Вставить (команда INSERT) информацию по новой аудитории нельзя, не вводя информацию о предмете; при удалении (команда DELETE) информации о предмете теряется информация об аудитории; при изменении (команда UPDATE) информации об аудитории необходимо просмотреть всю таблицу расписания.
Для исключения аномальных явлений при ведении БД следует исходное отношение разбить на два:
РАСПИСАНИЕ (курс, номер группы, день недели, пара, предмет, преподаватель);
ПРЕДМЕТ_АУДИТОРИЯ (предмет, аудитория).
Итак, чем выше нормальная форма отношения, тем легче поддерживать целостность БД. Существует два основных ограничения целостности у реляционной модели, которые позволяют назвать базу данных реляционно-полной.
Целостность объектов – в базе не допускается, чтобы какой-либо атрибут из первичного ключа отношения принимал неопределенное значение.
Ссылочная целостность – БД не должна содержать несогласованных значений внешних ключей. Если отношение R2 имеет среди своих атрибутов какой-то внешний ключ (FK), который соответствует первичному ключу (PK) отношения R1, то каждое значение FK должно быть равно значению PK.
СУБД поддерживают ссылочную целостность на операциях обновления и удаления записей.
Операция удаления (DELETE):
- при удалении первичного ключа (PK), на который есть ссылка во вторичных ключах (FK), для ограничения выполнения операции задается опция DELETE RESTRICTED;
- при удалении первичного ключа (PK), на который есть ссылка во вторичных ключах (FK), для удаления всех соответствующих записей задается опция DELETE CASCADE.
|
|
|
Операция обновления (UPDATE):
- при корректировке первичного ключа (PK), на который есть ссылки во вторичных ключах (FK), для ограничения выполнения операции задается опция UPDATE RESTRICTED;
- при корректировке первичного ключа (PK), на который есть ссылки во вторичных ключах (FK), для изменения всех соответствующих записей задается опция UPDATE CASCADE.
Алгебра отношений
Манипулирование данными в реляционной БД основано на алгебре отношений. При этом результатом ответа на любой запрос является отношение. Степень отношения – это число атрибутов, входящих в него. Мощность отношения – это число строк (кортежей) в отношении.
Все множество операций можно разделить на два подмножества:
1) теоретико-множественные операции: пересечение, объединение, вычитание и декартово произведение;
2) специальные операции: проекция, ограничение, соединение, деление.
Операции реляционной алгебры и конструкции языка SQL приведены на модели тестовой базы данных по поставкам деталей (рис. 1.21, 1.22).
Рис.
 | 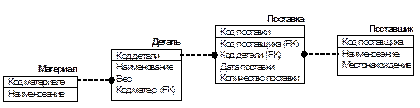 | ||
1.21. Концептуальная модель тестовой базы данных
Рис. 1.22. Физическая модель тестовой базы данных
Ниже приводится содержание таблиц тестовой базы данных.
DETAIL
| DETAIL_CODE | DETAIL_NAME | DETAIL_WEIGHT | MATERIAL_CODE |
| D1 | Болт | M2 | |
| D2 | Винт | M5 | |
| D3 | Муфта | M9 | |
| D4 | Гайка | M2 |
MATERIAL
| MATERIAL_CODE | MATERIAL_NAME |
| M2 | Сталь |
| M3 | Медь |
| M5 | Алюминий |
| M9 | Чугун |
SUPPLIER
| SUPPLIER_CODE | SUPPLIER_NAME | SUPPLIER_CITY |
| S1 | Иванов | Иваново |
| S2 | Петров | Москва |
| S3 | Сидоров | Москва |
| S4 | Серов | Киров |
ORDER
| ORDER-ID | SUPPLIER_CODE | DETAIL_CODE | ORDER_QUANTITY | ORDER_DATE |
| S1 | D1 | 01.01.04 | ||
| S1 | D2 | 01.01.04 | ||
| S1 | D3 | 01.02.04 | ||
| S1 | D4 | 01.02.04 | ||
| S1 | D1 | 01.02.04 | ||
| S1 | D2 | 01.02.04 | ||
| S2 | D1 | 01.01.04 | ||
| S2 | D2 | 01.03.04 | ||
| S3 | D2 | 01.04.04 | ||
| S4 | D1 | 01.05.04 |
Для рассмотрения теоретико-множественных операций введем еще одну таблицу:
DETAIL_1
| DETAIL_CODE | DETAIL_NAME | DETAIL_WEIGHT | MATERIAL_CODE |
| D2 | Винт | M5 | |
| D5 | Муфта | M3 |
Рассмотрим последовательно операции алгебры отношений. Начнем с теоретико-множественных операций.
1. Объединение UNION
DETAIL UNION DETAIL_1 = RESULT (DETAIL_CODE, DETAIL_NAME, DETAIL_WEIGHT, MATERIAL_CODE)
| D1 | болт | M2 | |
| D2 | винт | M5 | |
| D3 | муфта | M9 | |
| D4 | гайка | M2 | |
| D5 | муфта | M3 |
В результате объединения двух отношений получается новое отношение, степень которого равна степени исходных отношений, а мощность лежит в интервале
max(M1, M2) £ Mрез £ M1 + M2, где M1, M2 – мощности объединяемых отношений.
Пересечение INTERSECT
DETAIL INTERSECT DETAIL_1=RESULT(DETAIL_CODE, DETAIL_NAME, DETAIL_WEIGHT,MATERIAL_CODE)
| D2 | винт | M5 |
В результате пересечения двух отношений получается новое отношение, степень которого равна степени исходных отношений, а мощность лежит в интервале 0 £ Mрез £ min(M1, M2).
|
|
|
Вычитание MINUS
DETAIL MINUS DETAIL_1 = RESULT (DETAIL_CODE, DETAIL_NAME, DETAIL_WEIGHT, MATERIAL_CODE)
| D1 | болт | M2 | |
| D3 | муфта | M9 | |
| D4 | гайка | M2 |
В результате получается отношение, степень которого сохраняется, а мощность 0 £ Mрез £ M1.
Декартово произведение JOIN
DETAIL_1 JOIN MATERIAL =
RESULT(DETAIL_CODE,DETAIL_NAME,DETAIL_WEIGHT,MATERIAL_CODE,MATERIAL_CODE*,MATERIAL_NAME)
| D2 | винт | M5 | M2 | сталь | |
| D5 | муфта | M3 | M2 | сталь | |
| D2 | винт | M5 | M3 | медь | |
| D5 | муфта | M3 | M3 | медь | |
| D2 | винт | M5 | M5 | алюминий | |
| D5 | муфта | M3 | M5 | алюминий | |
| D2 | винт | M5 | M9 | чугун | |
| D5 | муфта | M3 | M9 | чугун |
Декартово произведение двух отношений – это множество всех сочетаний строк пересекаемых отношений. В результате получается отношение, степень которого равна сумме M1 + M2, а мощность – произведению M1 × M2.
Первые три теоретико-множественные операции возможны только в том случае, когда степени отношений идентичны, а соответствующие атрибуты определены на одних и тех же доменах (например, в случае работы с двумя таблицами деталей, полученными из разных источников). Четвертая операция (JOIN) является основой связывания таблиц при навигации по реляционной базе данных.
Рассмотрим специальные операции алгебры отношений.
1. Проекция – является унарной и предназначена для уменьшения степени отношения.
Пример: выбрать фамилии всех поставщиков из таблицы SUPPLIER. Результат: RESULT(SUPPLIER_NAME)
| Иванов |
| Петров |
| Сидоров |
| Серов |
При этом степень результирующего отношения определяется заказанным списком атрибутов проекции, мощность результирующего отношения остается прежней.
Ограничение – выборка строк отношения по заданному условию. Условие записывается в конъюнктивной нормальной форме (конъюнкция дизъюнктов):
(<терм>Ú(<терм>…) Λ (<терм>Ú(<терм>…);
<терм>= (Аi q ‘const’)/(Ai q Ak);
Аi, Ak – атрибуты отношения;
q = {<, >, =, <>, £, ³}.
Пример: выбрать поставщиков из города Москвы по условию (WHERE SUPPLIER_CITY='Москва').
Результат: RESULT(SUPPLIER_CODE, SUPPLIER_NAME, SUPPLIER_CITY)
| S2 | Петров | Москва |
| S3 | Сидоров | Москва |
Степень результирующего отношения остается прежней, а мощность 0 £ Mрез £ M1.
Пример: выбрать поставщиков из городов Москва или Иваново с фамилиями, начинающимися с буквы ‘С’, по условию WHERE (SUPPLIER_CITY='Москва' OR SUPPLIER_CITY='Иваново') AND (SUPPLIER_NAME=LIKE'C%').
Результат: RESULT(SUPPLIER_CODE, SUPPLIER_NAME, SUPPLIER_CITY)
| S3 | Сидоров | Москва |
Соединение – бинарная операция, реализующаяся на основе двух операций: декартова произведения и ограничения по заданному условию. Условие задается в виде
(АiqBk), где Аi – атрибут первого отношения; Bk – атрибут второго отношения; q = {<, >, =, <>, £, ³}. В качестве знака сравнения чаще всего используется знак «=». Такая операция называется эквисоединением.
Пример: соединить две таблицы по равенству ключа «код материала»
DETAIL_1 JOIN MATERIAL ON (DETAIL.MATERIAL_CODE = MATERIAL.MATERIAL_CODE).
Результат:
RESULT(DETAIL_CODE,DETAIL_NAME,DETAIL_WEIGHT,MATERIAL_CODE,MATERIAL_CODE*,MATERIAL_NAME)
| D2 | винт | M5 | M5 | алюминий | |
| D5 | муфта | M3 | M3 | медь |
Как правило, сравниваемыми атрибутами Аi и Bk являются первичный и вторичный ключи соединяемых отношений. В данном примере Аi – вторичный ключ таблицы DETAIL (FK), Bk– первичный ключ таблицы MATERIAL (PK).
СУБД, основанные на реляционной модели: Microsoft SQL Server, InterBase, MySQL, Informix, Sybase, Oracle, DB2.
Вопросы к разделу 1
1. Дать определение базы данных и СУБД.
2. В чем суть интеграции информации на основе трехуровневого представления информации?
3. В чем состоит суть методологии концептуального моделирования данных?
4. Дать определение модели данных.
5. Охарактеризовать иерархическую, сетевую и реляционную модели данных.
6. Охарактеризовать понятие целостности базы данных? Определить механизмы поддержания целостности на уровне логического моделирования баз данных.
7. Описать синтаксис стандарта IDEF1X, используемого при моделировании баз данных.
8. В чем суть нормализации реляционной базы данных?
9. Описать основные операции алгебры отношений.
10. Привести примеры характерных моделей информационных объектов, составляющих основу интегрированной базы данных.
 Раздел Раздел
 
|
 |
В этом разделе…
2. Системы управления базами данных
2.1. Функции СУБД
Система управления базами данных (сервер баз данных) –это совокупность языковых и программных средств, предназначенная для организации ведения и коллективного использования баз данных. Развитие СУБД прошло несколько этапов.
- 70-е – первая половина 80-х годов. Распространение СУБД для ЕС ЭВМ, основанных на иерархических и сетевых моделях данных.
- Конец 80-х – начало 90-х годов. Широкое внедрение псевдореляционных СУБД на ПЭВМ, так называемых систем dBASE-группы. С развитием локальных сетей появление сетевых версий этих систем.
- Середина 90-х годов. Освоение реляционно-полных серверов БД на рабочих станциях SUN, DEC под UNIX, а также Pentium Pro под Windows NT и выше. Развитие распределенной обработки данных в архитектуре «клиент-сервер», корпоративных сетей.
- Конец 90-х годов. Внедрение объектно-ориентированного подхода в технологию баз данных, появление объектно-реляционных и объектно-ориентированных СУБД.
- Начало нового тысячелетия. Соединение баз данных с Интернет-технологиями, распространение корпоративных порталов.
Перечислим основные функции СУБД:
1) управление данными во внешней памяти, организация методов доступа к дисковому пространству;
2) управление базой данных с поддержанием ее целостности, включая санкционирование доступа, поддержание пользовательских представлений, резервное копирование и восстановление, шифрование информации, управление транзакциями и параллелизмом, обработку запросов;
3) поддержание языков работы с базами данных;
4) администрирование БД;
5) автоматизированная разработка приложений (на основе CASE-средств, включая генераторы форм, отчетов, средствапроектирования баз данных, средства поддержки принятия решений).
2.1.1. Управление данными во внешней памяти
С точки зрения операционной системы (ОС) база данных представляет собой один или несколько файлов. Каждый файл разделяется на блоки (за один шаг доступа к базе в буфер оперативного запоминающего устройства (ОЗУ) считывается один блок, называемый страницей, размером 2, 4, 8 Кб). Страницы объединяются в экстенты (целое число страниц), которыми манипулирует администратор базы при распределении дискового пространства. Таким образом, на физическом уровне оперируют понятиями «файл», «страница», «экстент».
Действия, выполняемые при сохранении и извлечении записей из файла, называются методом доступа. В СУБД используются последовательный, прямой, индексный методы доступа.
При последовательном методе доступа страницы в ОЗУ выбираются одна за другой, последовательно от начала файла. На одной странице может быть расположено несколько логических записей. Записи в памяти просматриваются также последовательно, до нахождения нужной информации. Одновременно в ОЗУ может располагаться определённое количество блоков, с которыми работают предметные приложения. Процесс обработки информации в буфере ОЗУ с периодическим сбрасыванием изменений на диск называется кэшированием.
В основе прямого метода доступа лежит прямое обращение к конкретному номеру страницы. При этом первичный ключ записи должен строго соответствовать номеру страницы. Если в конкретном предметном приложении отсутствуют ключи, соответствующие определённым номерам страниц, место под них всё равно выделяется.
В реальной практике не всегда возможно установить однозначное соответствие между ключом и номером страницы. Существуют методы алгоритмизированного определения номера страницы по ключу. Это так называемые методы хеширования. Задается хеш-функция, посредством которой осуществляется соответствие между ключом и номером страницы. В случае коллизий предусматривается область переполнения.
В основе индексного метода доступа лежит принцип создания отдельного набора данных, состоящего из значений упорядоченного поля индексирования и ссылок на соответствующие номера страниц. Первичные индексы создаются по ключевым полям базы данных. Вторичные индексы – по любым неключевым полям (сочетанию полей). Из-за незначительных объёмов индексы могут помещаться в буфер ОЗУ, что ускоряет обработку информации. Организуются плотные и неплотные индексы (рис. 2.1). Неплотные индексы используются в случае физического упорядочения записей по ключу.
Рис. 
2.1. Организация индексов
В индексном методе доступа алгоритм поиска включает следующие шаги:
- поиск номера страницы по значению ключа;
- прямой доступ к соответствующей странице;
- последовательный просмотр записей страницы при поиске искомой.
Для работы с индексами применяется метод половинного деления. Возможно использование бинарных деревьев. Индексы используются как для быстрого доступа к записям, так и для упорядоченной обработки информации по индексируемому полю. Они могут быть составными. При этом поиск осуществляется по любому количеству ключей, входящих в состав индекса. Поддерживается так называемое мультисписковое индексирование, т.е. создается столько индексов, сколько необходимо для
эффективной работы с базой данных.
СУБД первого поколения базировались на последовательном, индексном и прямом методах доступа ОС. В системах второго поколения (псевдореляционных) файл базы данных соответствует одной таблице, по которой возможно мультисписковое индексирование посредством отдельных индексных файлов. Поиск в реляционно-полных СУБД также основан на мультисписковом индексировании. В единой БД наряду с таблицами, присоединенными процедурами, ограничениями целостности и другими элементами хранятся индексы.
Следует отметить, что системы управления базами данных, как правило, поддерживают уникальные модели данных. Так модель данных СУБД Informix основана на следующих элементах:
Chank – непрерывная область дисковой памяти, которая отводится серверу для использования; это неструктурированный диск/файл UNIX;
Page – страница размером 2 или 4 Кб; за одно обращение к диску считывается одна страница (физический блок);
Extent – совокупность страниц (Кб), которая выделяется под Dbspace;
Dbspace – логическая единица памяти, обеспечивающая возможность регулирования месторасположения данных; объединяет несколько баз данных;
Database – база данных;
Table – таблица;
Tbspace – объединение страниц одной таблицы для обеспечения эффективной обработки информации.
2.1.2. Управление базой данных
Защита базы данных
БД представляет собой важный корпоративный ресурс, который должен быть надлежащим образом защищен. Защита базы данных – это обеспечение ее охраны против любых предумышленных и непредумышленных угроз с помощью различных компьютерных и некомпьютерных средств. К угрозам относятся: похищение и фальсификация данных; утрата конфиденциальности; нарушение неприкосновенности любых данных; утрата целостности; потеря доступности.
Перечислим основные мероприятия, связанные с защитой БД.
Авторизация пользователей – это предоставление прав (или привилегий), позволяющих владельцу иметь законный доступ к системе. Каждому пользователю системный администратор присваивает уникальный идентификатор, с которым связан пароль. Некоторые СУБД поддерживают списки идентификаторов, отличные от ОС. Привилегии на доступ к отдельным объектам БД задают на языке SQL (команды REVOKE, GRANT).
Представление (подсхема) – динамический результат одной или нескольких реляционных операций с базовыми отношениями в целях создания некоторого иного отношения. Это виртуальное отношение, которое реально в базе не существует и которое позволяет скрыть от пользователя часть БД.
Резервное копирование и восстановление – это периодически выполняемая процедура получения копии БД и ее файла журнала (логического журнала) на носителе, сохраняемом отдельно от системы. Ведение журнала – это процедура создания и обслуживания файла журнала, содержащего сведения обо всех изменениях, внесенных в БД с момента создания последней резервной копии, и предназначенного для обеспечения эффективного восстановления системы в случае ее отказа.
Шифрование –это кодирование данных с использованием специального алгоритма, в результате чего данные становятся недоступными для чтения любой программой, не имеющей кода дешифрования.
|
|
|
