 |


Основные сервисы Google.
|
|
|
|
Информационно-поисковая система Rambler
Система – множество связанных друг с другом элементов некоторого вполне определенного множества (некоторых определенных множеств), образующих целостный объект при условии задания для этих объектов и отношений между ними некоторой цели и некоторых ресурсов для достижения этой цели.
В качестве примеров системы могут выступать: электронная почта, операционная система компьютера, телевидение, система высшего профессионального образования, информационно- поисковая система.
Информационно- поисковая система – система, предназначенная для поиска документов в информационных массивах, базах данных и всей совокупности информационных ресурсов.
Ниже приведен список наиболее популярных поисковых систем:
AltaVista (www.altavista.com)
Google (www.google.com)
InfoSeek (www.infoseek.com)
Lycos (www.lycos.com)
Microsoft (www.search.msn.com)
Yahoo (www.yahoo.com)
Апорт (www.aport.com)
Rambler (www.rambler.ru)
Яndех (www.yandex.ru)
Цель данной работы – изучить назначение, механизм работы, функции одной из популярных российских поисковых систем —Google; выделить в ней подсистемы, одну из которых рассмотреть детально; определить достоинства и недостатки системы в целом.
Google появился сравнительно недавно, в 1998 г. Его создатели, сотрудники Стенфордского университета (США) Сергей Брин и Лоуренс Пейдж, постарались сделать его механизм более гибким и расширяемым, чем существовавшие на то время у грандов поиска - Аltavista и Inktomi. На данный момент Google и Fast (еще одна ИПС, www.alltheweb.com) имеют самый большой объем проиндексированных страниц - более двух миллиардов (данные на июль 2002 г.). Речь идет не только о собственно html- и xml-документах, но и pdf, doc и даже флэш-анимации. Причем только Google, в отличие от других иностранных ИПС (мы не рассматриваем "Яндекс", "Рамблер> и <Апорт>), хорошо индексирует русскоязычные Web-ресурсы в зоне.ru.
|
|
|
Хотя корпорация была основана 2 сентября 1998 года, а домен Google.com зарегистрирован 15 сентября 1997 года, поисковик (с 2000 года) иногда отмечает свой день рождения и в другой день: как 7, так и 27 сентября.
Название Google произошло от намеренно искажённого Сергеем Брином слова Гугол (Googol), которое означает «десять в сотой степени» — 10100.
Успех компании Google состоит из трех основных слагаемых:
Первый – прекрасный релевантный алгоритм поиска. В отличие от многих поисковых систем Google не применяет программы, имеющие механизм мета поиска. Поисковая система гугл проводит анализ каждой интернет страницы, местонахождение всех заданных слов и шрифта. Когда происходит запрос фразы, которая несет смысловую нагрузку, Google выдается ссылка на главную страницу ресурса по указанной теме, а не только на те статьи, где из текста запроса есть какие-то слова.
Второй – очень дружелюбный интерфейс по отношению к пользователям. Человек, который попадет на сайт поисковой системы первый раз, удивится тому, насколько чистое окно, где, кроме поиска, нет ничего лишнего. Это, в отличие от конкурирующих сайтов поисковых систем, дает возможность загружаться намного быстрее. Каждый имеет возможность ознакомиться в гугл с исходным текстом его программного обеспечения, и внести свои предложения по улучшению.
Третье – поисковая система Google является некоммерческим проектом. Никогда реклама не была основным его источником доходов, даже создавался данный проект без какого-либо бизнес-плана. Вся его реклама очень ненавязчивая.

Рисунок 1 - Информационно-поисковая система Google.
Основные сервисы Google.
• Вопросы и ответы – сервис, предназначенный для коллективного получения ответов на различные вопросы.
• Google AdWords – данный сервис контекстной рекламы, который работает с ключевыми словами;
• Google AdSense – сервис контекстной рекламы, который дает возможность владельцам страниц, где наблюдается высокая посещаемость, хорошо заработать на этом.
• Google App Engine – специальная платформа, предназначенная для создания и хостинга масштабируемых интернет приложений на серверах гугл.
• Google Alerts – сервис, который с определенной заданной периодичностью отправляет на почту все результаты поиска.
• Google Calendar – сервис онлайн, предназначенный для планирования событий, встреч и различных важных дел с обязательной привязкой к календарю. Можно даже календарь использовать группой пользователей. Данный сервис взаимодействует с Gmail.
• Google Docs – данное приложение разработано для того, чтобы можно было работать с документами, возможно использование документа совместно.
• Bloggers – это сервис используется для ведения блогов. На хостинге находится только программное обеспечение, а полностью вся информация, то есть персональные страницы, записи и комментарии, сберегается на серверах гугл.
• Google Analytics – данный бесплатный сервис предоставляет подробную статистику по трафику интернет ресурса.
• Google Bookmarks – сервис, который дает возможность отмечать закладками ресурсы, и добавлять к ним примечания и ярлыки. Закладки сберегаются на сервере, и доступ к ним может быть с любого компьютера, а по примечаниям и ярлыкам можно осуществлять поиск.
• Google Buzz – это инструмент социальной сети, который был разработан компанией Google и интегрирован в Gmail.
• Google Dictionary – сервис, используемый для перевода определенных слов на другие языки.
• Google Knol – вики-энциклопедия, которая состоит из авторских статей по конкретным заданным тематикам.
• Google Health – это личная онлайновая медицинская карта.
• Gmail – является электронной бесплатной почтой, имеющей много места для хранения информации, то есть сообщений, удобный веб-интерфейс и доступ по POP3.
• Google Maps – это карты, которые основаны на базе бесплатного картографического сервиса.
• Google Checkout – данный сервис обработки платежей онлайн создан для того, чтобы существенно упростить процесс осуществления покупок онлайн. Данный сервис функционирует по всему миру. И в качестве одной из форм оплаты веб-мастера нередко его используют.
• Google Orkut – это социальный ресурс, где есть возможность создавать дружеские связи, указывать личные и профессиональные данные, и по взаимным интересам объединяться в сообщества.
|
|
|
|
|
|
Кроме этого, есть еще масса сервисов Google, например, карта Луны, карта Марса, персональные галереи фотографий, история поисковых запросов каждого пользователя, инструменты для веб-мастеров и целый ряд других.
Наряду с этим, есть также и специальные сервисы Google, которые являются полезными и интересными пользователям.
Теперь более подробно рассмотрим схему функционирования информационно-поисковой системы Google. Всю основную работу по просеиванию сквозь себя содержимого Сети выполняют Интернет-роботы (боты, crawlers). Каждый из них берет один адрес (URL, uniform resource locator; каждый URL соответствует определенному идентификатору документа) из базы данных URL-сервера, скачивает и передает содержимое странички на сервер хранения документов (рис. 2). Необходимо отметить, что все содержимое сервера хранится в заархивированном виде для увеличения его вместимости.
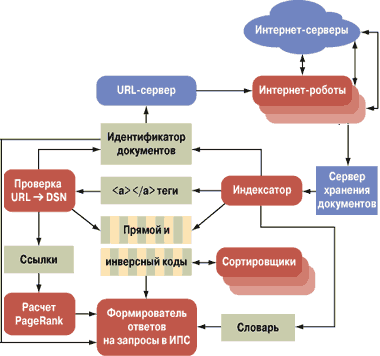
Рис. 2. Структура информационно-поисковой системы Google
Другая программа - индексатор - занимается тем, что разлагает текст документа на составляющие его слова (хит в терминологии Google), запоминая при этом местонахождение, шрифтовой вес, а также написано ли слово заглавными или строчными буквами и принадлежит ли оно к категории <особенных> (названия документов, метатеги, URL'ы и тексты ссылок). Вся эта информация складывается в набор контейнеров, именуемых на рисунке прямым индексом. Структура хранимых в нем данных выглядит следующим образом (рис. 3).

Рис. 3. Структура прямого индекса (doc_id - идентификатор документа; word_id - идентификатор слова; null_word - символ окончания документа; n_hits - частота, с которой слово встречается в документе)
Идентификаторы слов берутся из словаря, который постоянно пополняется. Одновременно с этим индексатор просматривает содержимое тегов <a></a> и проверяет корректность всех ссылок в службе разрешения имен DNS (domain name service). Если ему встретился URL, которого нет в базе данных по doc_id, он пополняет не только ее, но и коллекцию ссылок. В дальнейшем этот Интернет-адрес попадает в URL-сервер и круг замыкается. Система поиска новых документов, при условии, что на них хоть кто-нибудь ссылается, становится самодостаточной - она сама себя подпитывает.
|
|
|
Но каким образом ИПС узнает о новых Web-ресурсах, которых еще никто не успел посетить? Для разрешения этой проблемы разработчики предусмотрели ручную форму регистрации ресурсов в поисковой системе. Введенные в нее адреса после проверки на корректность также попадают в URL-сервер.
Заметим, что каждая из программ, обозначенных на рис. 1 эллипсом, работает независимо от других, причем аппаратные конфигурации серверов и рабочих станций, на которых функционирует <движок> Google, выбираются так, чтоб не создавать <пробок> при обработке информации, собранной Интернет-роботами.
Описанная выше структура прямого индекса не очень удобна при поиске документов на основании встречающихся в них слов (пользователь задает слово или словосочетание, а система должна найти подходящий документ). Чтобы решить эту проблему, был введен так называемый инверсный, или обратный, индекс (рис. 4). В нем любому слову из словаря соответствует набор doc_id-документов, в которых это слово встречается. Работой по постоянному формированию инверсного индекса занимаются сортировщики. Так как, во-первых, всегда появляются новые документы и, во-вторых, обновляются старые, индекс приходится постоянно перестраивать.

Рис. 4. Структура инверсного индекса (word_id - идентификатор слова; ndocs - количество документов с этим словом; doc_id - идентификатор документа; n_hits - частота, с которой слово встречается в документе)
Пусть от пользователя поступил запрос найти документы со словом <мухобойка>. Программа, формирующая ответы, посмотрит в словарь, найдет там word_id для <мухобойки>, сформирует запрос в базу данных с использованием инверсного индекса и получит набор документов, в которых это слово встречается. Далее на основании PageRank, количества хитов, их качества и, может быть, других ограничений и приоритетов разработчиков будут распределены порядковые номера страниц в выходном списке. В итоге Интернет-пользователь получит самую оптимальную, по мнению ИПС, информацию о том, где и что писали о правилах и способах мухоубийства.
Полнота - это одна из основных характеристик поисковой системы, которая представляет собой отношение количества найденных по запросу документов к общему числу документов в Интернете, удовлетворяющих данному запросу.
|
|
|
Точность - еще одна основная характеристика поисковой машины, которая определяется как степень соответствия найденных документов запросу пользователя. Огромную роль в повышении точности поиска играет ранжирование. Google использует алгоритм расчёта авторитетности PageRank. PageRank — это числовая величина, характеризующая «важность» веб-страницы. Чем больше ссылок на страницу, тем она становится «важнее». Кроме того, «вес» страницы А определяется весом ссылки, передаваемой страницей B. Таким образом, PageRank — это метод вычисления веса страницы путём подсчёта важности ссылок на неё. PageRank является одним из вспомогательных факторов при ранжировании сайтов в результатах поиска. PageRank не единственный, но очень важный способ определения положения сайта в результатах поиска Google. Google использует показатель PageRank найденных по запросу страниц, чтобы определить порядок выдачи этих страниц посетителю в результатах поиска.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Сегодня Google представляет обновленный интерфейс и функционал поиска. Живой поиск Google сразу показывает результаты поиска по мере того, как вы вводите запрос. Благодаря живому поиску пользователь сможет сэкономить от 2 до 5 секунд на каждом запросе. Главное отличие Живого поиска от обычного заключается в том, что получить нужную информацию можно гораздо быстрее, так как необязательно вводить весь запрос и даже нажимать Enter. Кроме того, в Живом поиске видны результаты прямо при вводе текста. Преимущества живого поиска:
Более быстрый поиск. В Живом поиске вы получаете результаты непосредственно при вводе текста, что позволяет экономить от 2 до 5 секунд при каждом запросе.
Более точные подсказки. Даже если вы не уверены, как сформулировать запрос, система подсказок поможет вам найти нужные слова. При этом лучшая подсказка появится прямо в строке поиска (выделяется серым цветом), и если она подойдет, вам даже не придется вводить весь запрос – результаты уже будут на экране.
Мгновенные результаты. Раньше приходилось сначала указывать ключевое слово, после этого нажимать Enter, а затем ждать результаты. Теперь вы видите результаты еще при вводе запроса и можете сразу менять направление поиска.
Наглядность представления результатов является необходимым компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости запросов или неточности поиска, даже первые страницы не всегда содержат только нужную информацию. Это означает, что пользователю часто приходится проводить свой собственный поиск внутри списка найденного. Различные элементы ответной страницы помогают ориентироваться в результатах поиска. Человек, который попадет на сайт поисковой системы Google первый раз, удивится тому, насколько чистое окно, где, кроме поиска, нет ничего лишнего.
Как лучше искать в Google:
Говорят что правильно заданный вопрос это половина ответа. Одной из самых важных состовляющих поиска – релевантность: полнота и точность. Поисковик оценивает не только сам факт нахождения слов в тексте, но и их порядок, структуру и местонахождение, что влияет на рейтинг страниц. Страница на которой искомое слово в заголовке будет иметь больший рейтинг чем страница на которой это слово в тексте. При отображении количество ссылок на эту страницу в и-нете также будет влиять на рейтинг.
При запросе на поиск двух и более слов поисковик выдает вам результаты в которых есть хотя бы 1 из этих слов. Возьмем к примеру скриншот №1. Скачать песню queen – we will rock you -197 результатов. Придется убить всю ночь на просмотр всех. Но есть способ сократить ненужные вам результаты
Если взять искомую фразу в кавычки то поисковик будет искать не одно из слов, а только эти 3 слова и только в заданной последовательности. Результат — 10 страниц. 197 и 10 — есть разница?
define – команда, которая используется для поиска терминов в интернете. Например: define – Флюоресценция.
intitle – с помощью этой команды поиск будет вестись только там, где это слово находится в заголовках сайтов.
Например: intitle: music
inurl – поиск только по url в которых содержится данное слово.
info – выдает сведения о главной станице сайта. Набрав: info:akak.ru, вы увидите информацию о главной странице этого сайта.
site – с помощью данной команды поиск будет вестись только на заданном сайте. Например site:www.akak.ru, будет искать заданную информацию на этом сайте.
safesearch – исключает из поиска сайты эротического характера. Пример приводить не буду, у вас их и так хватает)
… – 3 точки это оказывается тоже команда. Используется для ввода диапазона чисел, например цен или населения
Например: Купить игру 10…20 у.е. Ах да, и не забудьте поставить единицу измерения или валюту, ато будут отображены все диапазоны.
filetipe: ведет поиск по типу файла. Например: Скачать установочные файлы filetipe:rar
Так же гугл можно использовать вместо калькулятора, просто введите числа и знаки: /,*,-,+. Чтобы высчитать процент введите 13% of 333. Так же есть конвертер валют. Работает по такому принципу, нужно вводить названия валют на англ. Например: 47RUB in USD.
Актуальность – очень важная характеристика поиска, которая определяется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу. Для поисковиков очень важна актуальность информации. Не случайно, если вы наберете в поиске по картинкам Google запрос чемпионат мира, поисковик выдаст события в картинках в хронологическом порядке. Это можно использовать для своих целей, регулярно обновляя и наращивая визуальный контент сайта.
Чтобы выделить основные достоинства и недостатки информационно-поисковой системы Google необходимо представить ее в сравнении с другими поисковыми системами.
Для этого следует определить степень схожести структур поисковых запросов к крупнейшим российским поисковым системам (Яндекс, Rambler, Google); определить процент транзакционных («продающих») запросов от общего числа поисковых запросов к поисковой системе; определить процент пересечения поисковых запросов, в исследуемых поисковых системах.
|
|
|
