 |


Наиболее распространенные способы кодирования и их свойства. Алгоритмы кодирования.
|
|
|
|
В этом разделе мы будем рассматривать просто кодировки. (То есть такие, когда одно слово представляется в виде другого слова).
Во всех случаях рассматривается следующая модель. Есть два алфавита
А = (а 1, …, аn) и B = (b 1, …, bq).
Кодирование φ это отображение слов α в алфавите А в слова β=φ(α) в алфавите В.
Кодирование называется дешифруемым, если по слову β однозначно восстанавливается α. (Отображение φ – биекция).
Кодирование слов и поиск минимального кода
Пусть у нас есть коды объектов - слова в алфавите A.
Опр. Длина кода – количество символов в нем.
Нельзя ли построить код минимальной длины, пусть даже в другом алфавите B?
Оказывается, эта задача алгоритмически неразрешима.
Теорема: Не существует МТ, которая строит код минимальной длины.
Доказательство: Упорядочим Bn (по длине в лексикографическом порядке):
0, 1, 00, 01, 11, 000, 001… (*)
Пусть есть МТ Т 1, который умеет на х строить К (х) минимальной длины (по К (х) можем однозначно восстановить х). Строим Т 2 = F (T 1, …). Натуральное m, T 2 в (*) слева направо подходит первое x: K (x) ≥m. Следовательно, m – код х (длина m→ log m), но K (x) – лучше по длине. Значит, K (x) ≤ log m.
Признаковое кодирование.

Признаки:
Рассматривается множество объектов s1,…,sm (люди, болезни, месторождения и т.п.), которое нужно кодировать, т.е. каждому объекту нужно сопоставить слово в алфавите. При этом есть другое множество объектов, называемых признаками, которые мы умеем кодировать. Тогда кодом объекта при признаковом кодировании является вектор, компонентами которого являются коды (значения) признаков, применительно к данному объекту.
Например,
α (si) = (α 1, …, αk) 
Пример: s 1 … sn – люди.
|
|
|
1) Цвет волос
2) Рост
3) Вес
p 1 … pn – размер частей тела человека.
Следующий шаг – появление классов объектов, задача – определить, какие из объектов к каким классам принадлежат.
В случае бинарных значений признаков при признаковом кодировании объектом исследования является матрица вектров признаков.
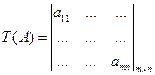
Выше мы уже говорили о стремлении строить неизбыточные коды. С этой задачей связана известная проблема дискретной математики – проблема поиска минимальных тестов таблицы.
Опр. Тест - это множество столбцов в T (A) такое, что все строки в подматрице, образованной этим множеством, попарно различны.
Длина теста – количество столбцов в тесте.
Минимальный тест – тест с минимальным количеством столбцов.
Признаковое кодирование и проблема распознавания.
С признаковым кодированием тесно связана проблема отнесения объекта к определенному классу.
 Есть классы объектов. Субъекты определенным образом кодируют эти объекты в некотором признаковом пространстве.
Есть классы объектов. Субъекты определенным образом кодируют эти объекты в некотором признаковом пространстве.
x = (x 1 ,…,xn)
|
Выборка известных кодированных объектов из класса называется обучающей выборкой.
 Задача: Взяв объект неизвестного класса, сопоставить ему набор признаков x, отнести его к какому-либо классу, по возможности однозначно.
Задача: Взяв объект неизвестного класса, сопоставить ему набор признаков x, отнести его к какому-либо классу, по возможности однозначно.
х
Если между информационным объектом и кодом связи нет, то задача не решаема. В противном случае все зависит от нас.
Гипотеза компактности:
1) 2 точки пространства x, принадлежащие одному классу, могут быть соединены непрерывной кривой, все точки которой принадлежат этому классу.
2) Если точка принадлежит классу k, то в некоторой ненулевой окрестности почти все точки принадлежат к классу k.
3) Число неопределенных точек пространства x имеет меру 0.
Приведем примеры некоторых методов распознавания.
Метод разделяющих функций

 Классы k 1 (×) и k 2 (○) – обучающие выборки.
Классы k 1 (×) и k 2 (○) – обучающие выборки.
|
|
|
Это в чистом виде эвристический подход. Строим функцию по обучающей выборке, затем относительно нее определяем, к какому классу относить новые точки.
4.2.3.2  Метод комитетов
Метод комитетов
Комитеты (эксперты)

Всегда существует комитет такой, что для любой точки из обучающей выборки
x:  M = (pi 1 ,…,pik), k >
M = (pi 1 ,…,pik), k > 
pi 1 ,…pik – корректно определяют точку x.
Если больше половины правильно классифицируют эту точку, то это называется комитет.
x0 (конкретная точка) ← p 1 ,…,ps (по большинству относятся к k 1 или k 2) .
4.2.3.3 Метод потенциалов (пришел из физики)
x • ← заряд (ассоциируем каждую точку с неким зарядом).
 U(X) – потенциальная функция поля.
U(X) – потенциальная функция поля.
Вычисляем потенциал x0, и смотрим, к чему он ближе.
Метод вычисления оценок
k 1 и k 2 – строится обучающая таблица.
|
|



X = Bn (0,1)
1) В этой таблице строятся опорные множества T 1 ,…Tk.
Tj  {1 ,…,n } – подмножества столбцов.
{1 ,…,n } – подмножества столбцов.
2) ρTj (x,y) – функция близости объектов по заданному опорному множеству.
3) Г = (γ 1, …,γm) – действительные числа (веса) – веса строк.
4) Вычисление оценок.

 X 1 P= { p 1 ,…,pn } – признаковое пр-во.
X 1 P= { p 1 ,…,pn } – признаковое пр-во.
 |
 X 2 – веса.
X 2 – веса.
 |
X ω
1. Система опорных множеств
T 1, T 2, …, Tn, Ti {1, …, n } – подмножество множества стобцов. В простейшем случае подмножество одно – это все матрица.
2. Функция близости по опорному множеству
 . Построить ее можно, например, так:
. Построить ее можно, например, так:
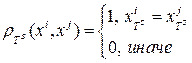
Но эту функцию можно строить и по другому: если больше 1 признака совпадает, или если больше 50% совпадает.
3. Вычисление функции близости по xi
В самом простом случае Г (xω, xi) = γi ρ (xω, xi) – функция близости к искомому
объекту с учетом доверия ему к классу.
В общем случае формула примет вид: Г(xω, xi) = F(γi ρ (xω, xi))
4. Вычисление функции по классу
 в – близость
в – близость  к каждому классу.
к каждому классу.
5. Решающее правило
Теперь задаем решающее правило – max, min и т.п., и определяем по нему принадлежность.
В общем случае этот алгоритм является параметрическим. A (Г, ρ, M), где Г, ρ, M – некий набор параметров, - изначально помимо обучающей выборки были известны прецеденты; параметры подгонялись так, чтобы известные прецеденты попадали по алгоритму в верные классы.
Сериальное кодирование
|
|
|
Здесь А = (0,1) и B = (0,1,…,9,*). Здесь символ * играет роль разделителя.
В данном примере битовые последовательности кодируются натуральными числами. Как это следует из свойств данного кодирование, оно дает эффект сжатия, когда битовые последовательности представляют собой чередование сравнительно больших блоков нулей и единиц.
Алгоритм кодирования. Пусть дана битовая последовательность α и а 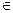 (0,1) ее первый символ. Блоком назовем часть последовательности, состоящую из одинаковых символов. Тогда любую битовую последовательность можно представить как чередование блоков из нулей и единиц. Пусть в последовательности α всего S блоков, длина первого x1, длина второго x2,…, длина S –го - xS. Тогда кодом α будет слово β=φ(α)=а* x1* x2*…* xS.
(0,1) ее первый символ. Блоком назовем часть последовательности, состоящую из одинаковых символов. Тогда любую битовую последовательность можно представить как чередование блоков из нулей и единиц. Пусть в последовательности α всего S блоков, длина первого x1, длина второго x2,…, длина S –го - xS. Тогда кодом α будет слово β=φ(α)=а* x1* x2*…* xS.
Алгоритм декодирования очевиден.
Определение. Длиной сериального кода назовем число  .
.
Определение. Средней длиной кода для n-последовательностей назовем число
 ,
,
Где сумма берется по всем двоичным последовательностям длины n.
Свойства кодирования определяются следующими двумя утверждениями.
Утверждение.  .
.
Доказательство.
 .
.
Утв. Средняя длина слова в сериальном кодировании
 .
.
Из этих утверждений следует.

Таким образом, сериальное кодирование при малых количествах серий и большой длине серий приводит к тому, что при таком кодировании возникает эффект сжатия.
Если серии короткие и их много, например:  и
и  , то эффекта сжатия не возникает.
, то эффекта сжатия не возникает.
Алфавитное кодирование.
Если пренебречь разделителями, то в качестве двух алфавитов возьмем алфавиты
А = (а 1, …, аn) и B = (b 1, …, bq).
Алгоритм кодирования. Каждой букве ai алфавита A ставится в соответствие Bi= φ(ai) – слово в алфавите B длины li.
Алфавитное кодирование будет дешифруемым, если отображение  индуцирует биекцию, т.е. для
индуцирует биекцию, т.е. для  .
.
 |
Обратим внимание на следующий важнейший факт, который, по сути дела, и оправдывает интерес к такому виду кодирования. Очевидно, что ограничение на вид отображения φ сразу влечет дешифруемость однобуквенных (в алфавите А) слов. Но из дешифруемости однобуквенных слов сразу следует дешифруемость слов (в алфавите A) любой длины.
|
|
|
Заметим также, что в случае дешифруемого кодирования все слова Bi= φ(ai) обязательно различны.
Оказывается, что дешифруемость накладывает ограничение на набор длин кодовых слов. Об этом говорит утверждение, известное как неравенство Крафта.
Неравенство Крафта.
Теорема. Если алфавитное кодирование с длиной кодов l 1, …, lm дешифруемо, то выполняется неравенство:

Доказательство. Пусть А = (а 1, …, аn) и B = (b 1, …, bq). Каждой букве ai алфавита A ставится в соответствие Bi= φ(ai) – слово в алфавите B длины li. Положим

Пусть  . Возведем Z в некоторую степень n, тогда
. Возведем Z в некоторую степень n, тогда
 .
.
Здесь введено обозначение S (n, t) – число слов длины t и вида Bi 1 Bi 2 …Bin. Из дешифруемости следует, что все такие слова различны, но число различных слов длины t в алфавите из q букв не превосходит qt, поэтому
S (n, t)  qt.
qt.
Тогда  , где n – натуральное, а l ≥ 0, целое. Это неравенство должно выполняться для любого n, но это возможно только тогда, когда Z не превосходит единицы, т.е.
, где n – натуральное, а l ≥ 0, целое. Это неравенство должно выполняться для любого n, но это возможно только тогда, когда Z не превосходит единицы, т.е.
 .
.
Утверждение доказано.
Префиксные коды.
Определение. Слово α является подсловом слова β, если существуют слова ϒ и ϑ (возможно пустые) такие, что β=ϒαϑ.
В общем случае из неравенства Крафта не следует дешифруемость.
Определение. Кодирование называется префиксным, если ни одно из кодовых слов не является началом другого.
Теорема. Префиксный код дешифруем.
Доказательство: Пусть есть α и β – два слова: φ (α) = Bi 1 Bi 2 …Bin, φ (β) = Bj 1 Bj 2 …Bjn).
Покажем, что из равенства φ (α) = φ (β)следует равенство α = β.
Пусть Bi 1 Bi 2 …Bin = Bj 1 Bj 2 …Bjn
Поочередно слева направо сравниваем подслова слов α и β, используя знание функции ϕ, которая определяет наше побуквенное кодирование (эта функция позволяет находить Bi= φ(ai) среди подслов слов α и β. Сначала сравниваем Bi 1= Bj 1, затем переходим к Bi 2и Bj 2 и т.д.
Если длины слов Bi 1и Bj 1одинаковы, то сами слова должны быть одинаковыми из того, что Bi 1 Bi 2 …Bin = Bj 1 Bj 2 …Bjn. Если длины слов разные, то одно из двух слов: Bi 1или Bj 1– начало другого, что противоречит определению префиксности.
Значит, α = β.
Теорема доказана.
Из теоремы сразу следует алгоритм декодирования префиксного кода.
Алгоритм декодирования. Берем первый символ слова φ (α)и ищем однобуквенное слово среди кодовых слов. Если находим такое слово, например, Bi= φ(ai), то декодируем слово Bi= φ(ai) в букву ai и продолжаем работать, начиная со следующего символа слова φ (α). Если не находим, то добавляем следующий символ и ищем среди кодовых слов уже двухбуквенное слово. И т.д.
В случае алфавитного кодирования можно ограничиться префиксными кодами, так как, в каком-то смысле, любой дешифруемый алфавитный (побуквенный) код можно свести к префиксному. А существование префиксного кода полностью определяется неравенством Крафта.
|
|
|
Теорема (о существовании префиксного кода). Префиксный код с длинами кодов l 1 … ln существует тогда и только тогда, когда выполняется неравенство Крафта
 .
.
Доказательство. Т.к. префиксный код дешифруем, то выполняется неравенство Крафта. С другой стороны, пусть выполняется неравенство Крафта. Покажем, что в этом случае существует префиксный код. Мы просто опишем алгоритм построения такого кода, т.е. построим отображение Bi= φ(ai).
Пусть . Пусть среди чисел l 1 … ln имеется S 1 единиц, S 2 двоек, S 3 троек и т.д. до S l слов длины l. При этом некоторые из S i могут быть нулями. Упорядочим Bi= φ(ai) по возрастанию длины.
 B 1 = | l 1| = 1
B 1 = | l 1| = 1
B 2 = | l 2| = 1 S 1 слов длины 1
…
 BS 1 = | lS 1| = 1
BS 1 = | lS 1| = 1
B S 1+1 = | l S 1+1| = 2
S 2 слов длины 2
…


 Тогда левую часть неравенства Крафта можно представить в виде:
Тогда левую часть неравенства Крафта можно представить в виде: 
S 1 S 2 S 3
Теперь пошагово строим наш префиксный код.
Первый шаг: Любые S 1 букв в B можно использовать для кодирования слов длины. Это следует из того, что при выполнении неравенства Крафта справедливо соотношение: S 1/ q ≤ 1, из которого следует, что S 1 ≤ q. Таким образом мы получили первую группу однобуквенных слов.
Второй шаг: Аналогично из неравенства Крафта получаем S 1/ q + S 2/ q ≤ 1. Отсюда S 1 q + S 2 ≤ q 2, S 2 ≤ q 2 – s 1 q. Поэтому можно взять S 2 слов длины 2 в алфавите B так, что они не начинаются со слов первой группы. Таким образом мы получили вторую группу двухбуквенных слов.
Третий шаг: На этом шаге строим группу трехбуквенных слов так, чтобы они не начинались с ранее построенных слов. Такие трехбуквенные слова в нужном количестве существуют, так как вновь из неравенства Крафта следует, что S 1 /q + S 2 /q + S3 / q ≤ 1. А это означает, что S3 ≤ q3 – qS 2 – q 2 S 1.
Таким образом проходим все l шагов и в результате получаем дешифруемый префиксный код.
Теорема доказана.
|
|
|
