 |


Программная модель процессоров семейства X 86
|
|
|
|
Пользовательские регистры
Как следует из названия, пользовательскими регистры называются потому, что программист может использовать их при написании своих программ. К этим регистрам относятся (рис. 1):
· восемь 32-битных регистров, которые могут использоваться программистами для хранения данных и адресов (их еще называют регистрами общего назначения (РОН)):
o eax/ax/ah/al;
o ebx/bx/bh/bl;
o edx/dx/dh/dl;
o ecx/cx/ch/cl;
o ebp/bp;
o esi/si;
o edi/di;
o esp/sp.
· шесть регистров сегментов: cs, ds, ss, es, fs, gs;
· регистры состояния и управления:
o регистр флагов eflags/flags;
o регистр указателя команды eip/ip.
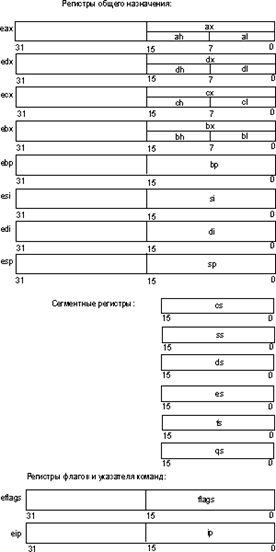
Рис. 1. Пользовательские регистры микропроцессоров i486 и Pentium
Почему многие из этих регистров приведены с наклонной разделительной чертой?
Нет, это не разные регистры — это части одного большого 32-разрядного регистра. Их можно использовать в программе как отдельные объекты.
Так сделано для обеспечения работоспособности программ, написанных для младших 16-разрядных моделей микропроцессоров фирмы Intel, начиная с i8086.
Микропроцессоры i486 и Pentium имеют в основном 32-разрядные регистры. Их количество, за исключением сегментных регистров, такое же, как и у i8086, но размерность больше, что и отражено в их обозначениях — они имеют приставку e (E xtended).
Регистры общего назначения
Все регистры этой группы позволяют обращаться к своим “младшим” частям.
Для самостоятельной адресации можно использовать только младшие 16 и 8-битные части этих регистров. Старшие 16 бит этих регистров как самостоятельные объекты недоступны. Это сделано, как мы отметили выше, для совместимости с младшими 16-разрядными моделями микропроцессоров фирмы Intel.
Перечислим регистры, относящиеся к группе регистров общего назначения. Так как эти регистры физически находятся в микропроцессоре внутри арифметико-логического устройства (АЛУ), то их еще называют регистрами АЛУ:
|
|
|
· eax/ax/ah/al (Accumulator register) — аккумулятор.
Применяется для хранения промежуточных данных. В некоторых командах использование этого регистра обязательно;
· ebx/bx/bh/bl (Base register) — базовый регистр.
Применяется для хранения базового адреса некоторого объекта в памяти;
· ecx/cx/ch/cl (Count register) — регистр-счетчик.
Применяется в командах, производящих некоторые повторяющиеся действия. Его использование зачастую неявно и скрыто в алгоритме работы соответствующей команды.
К примеру, команда организации цикла loop кроме передачи управления команде, находящейся по некоторому адресу, анализирует и уменьшает на единицу значение регистра ecx/cx;
· edx/dx/dh/dl (Data register) — регистр данных.
Так же, как и регистр eax/ax/ah/al, он хранит промежуточные данные. В некоторых командах его использование обязательно; для некоторых команд это происходит неявно.
Следующие два регистра используются для поддержки так называемых цепочечных операций, то есть операций, производящих последовательную обработку цепочек элементов, каждый из которых может иметь длину 32, 16 или 8 бит:
· esi/si (Source Index register) — индекс источника.
Этот регистр в цепочечных операциях содержит текущий адрес элемента в цепочке-источнике;
· edi/di (Destination Index register) — индекс приемника (получателя).
Этот регистр в цепочечных операциях содержит текущий адрес в цепочке-приемнике.
В архитектуре микропроцессора на программно-аппаратном уровне поддерживается такая структура данных, как стек. Для работы со стеком в системе команд микропроцессора есть специальные команды, а в программной модели микропроцессора для этого существуют специальные регистры:
· esp/sp (Stack Pointer register) — регистр указателя стека.
Содержит указатель вершины стека в текущем сегменте стека.
|
|
|
· ebp/bp (Base Pointer register) — регистр указателя базы кадра стека.
Предназначен для организации произвольного доступа к данным внутри стека.
Не спешите пугаться столь жесткого функционального назначения регистров АЛУ. На самом деле, большинство из них могут использоваться при программировании для хранения операндов практически в любых сочетаниях. Но, как мы отметили выше, некоторые команды используют фиксированные регистры для выполнения своих действий. Это нужно обязательно учитывать.
Использование жесткого закрепления регистров для некоторых команд позволяет более компактно кодировать их машинное представление. Знание этих особенностей позволит вам при необходимости хотя бы на несколько байт сэкономить память, занимаемую кодом программы.
Сегментные регистры cs, ss, ds, es, gs, fs.
Их существование обусловлено спецификой организации и использования оперативной памяти микропроцессорами Intel. Она заключается в том, что микропроцессор аппаратно поддерживает структурную организацию программы в виде трех частей, называемых сегментами. Соответственно, такая организация памяти называется сегментной.
Для того чтобы указать на сегменты, к которым программа имеет доступ в конкретный момент времени, и предназначены сегментные регистры. Фактически, с небольшой поправкой, как мы увидим далее, в этих регистрах содержатся адреса памяти с которых начинаются соответствующие сегменты. Логика обработки машинной команды построена так, что при выборке команды, доступе к данным программы или к стеку неявно используются адреса во вполне определенных сегментных регистрах. Микропроцессор поддерживает следующие типы сегментов:
1. Сегмент кода. Содержит команды программы.
Для доступа к этому сегменту служит регистр cs (code segment register) — сегментный регистр кода. Он содержит адрес сегмента с машинными командами, к которому имеет доступ микропроцессор (то есть эти команды загружаются в конвейер микропроцессора).
2. Сегмент данных. Содержит обрабатываемые программой данные. Для доступа к этому сегменту служит регистр ds (data segment register) — сегментный регистр данных, который хранит адрес сегмента данных текущей программы.
|
|
|
3. Сегмент стека. Этот сегмент представляет собой область памяти, называемую стеком. Работу со стеком микропроцессор организует по следующему принципу: последний записанный в эту область элемент выбирается первым. Для доступа к этому сегменту служит регистр ss (stack segment register) — сегментный регистр стека, содержащий адрес сегмента стека.
4. Дополнительный сегмент данных.
Неявно алгоритмы выполнения большинства машинных команд предполагают, что обрабатываемые ими данные расположены в сегменте данных, адрес которого находится в сегментном регистре ds.
Если программе недостаточно одного сегмента данных, то она имеет возможность использовать еще три дополнительных сегмента данных. Но в отличие от основного сегмента данных, адрес которого содержится в сегментном регистре ds, при использовании дополнительных сегментов данных их адреса требуется указывать явно с помощью специальных префиксов переопределения сегментов в команде.
Адреса дополнительных сегментов данных должны содержаться в регистрах es, gs, fs (extension data segment registers).
Регистры состояния и управления eflags и ip
Они постоянно содержат информацию о состоянии, как самого микропроцессора, так и программы, команды которой в данный момент загружены на конвейер. Используя эти регистры, можно получать информацию о результатах выполнения команд и влиять на состояние самого микропроцессора.
eflags/flags (flag register) — регистр флагов. Разрядность eflags/flags — 32/16 бит. Отдельные биты данного регистра имеют определенное функциональное назначение и называются флагами. Младшая часть этого регистра полностью аналогична регистру flags для i8086.
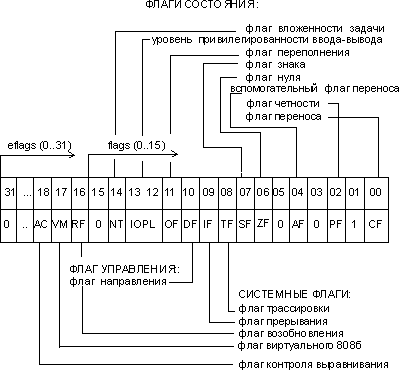

Рис. 2. Содержимое регистра eflags
Исходя из особенностей использования, флаги регистра eflags/flags можно разделить на три группы:
· 8 флагов состояния. Эти флаги могут изменяться после выполнения машинных команд. Флаги состояния регистра eflags отражают особенности результата исполнения арифметических или логических операций. Это дает возможность анализировать состояние вычислительного процесса и реагировать на него с помощью команд условных переходов и вызовов подпрограмм.
|
|
|
· 1 флаг управления - df (Directory Flag). Значение флага df определяет направление поэлементной обработки цепочек данных: от начала строки к концу (df = 0) либо наоборот, от конца строки к ее началу (df = 1).
· 5 системных флагов, управляющих вводом/выводом, маскируемыми прерываниями, отладкой, переключением между задачами и виртуальным режимом 8086. Прикладным программам не рекомендуется модифицировать без необходимости эти флаги, так как в большинстве случаев это приведет к прерыванию работы программы.
eip/ip (Instraction Pointer register) — регистр -указатель команд.
Регистр eip/ip имеет разрядность 32/16 бит и содержит смещение следующей подлежащей выполнению команды относительно содержимого сегментного регистра cs в текущем сегменте команд. Этот регистр непосредственно недоступен программисту, но загрузка и изменение его значения производятся различными командами управления, к которым относятся команды условных и безусловных переходов, вызова процедур и возврата из процедур. Возникновение прерываний также приводит к модификации регистра eip/ip.
Типы данных. Переменные
В программе на ассемблере переменными являются регистры или ячейки памяти, в которых хранятся данные. Существует несколько типов данных-переменных:
1. Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды. 20d, 0a2h, 10111b
2. Данные простого типа, описываемые с помощью ограниченного набора директив резервирования памяти, позволяющих выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации.
Эти два типа данных являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу. Но насколько это будет удобно — вот вопрос.
3. Данные сложного типа, (массивы, структуры, записи и пр.) которые были введены в язык ассемблера с целью облегчения разработки программ. Сложные типы данных строятся на основе базовых типов, которые являются как бы кирпичиками для их построения. Введение сложных типов данных позволяет несколько сгладить различия между языками высокого уровня и ассемблером
Физическая интерпретация данных простого типа основывается на размерности данных:
· байт — восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом;
· слово — последовательность из двух байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
|
|
|
· двойное слово — последовательность из четырех байт (32 бита), расположенных по последовательным адресам.
· учетверенное слово — последовательность из восьми байт (64 бита), расположенных по последовательным адресам.
· 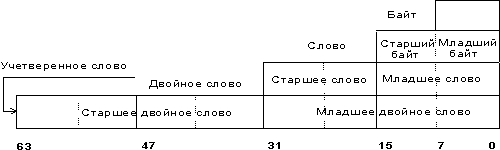
Рис. 3. Основные типы данных микропроцессора
Логическая интерпретация этих типов:
- Целый тип со знаком — двоичное значение со знаком, размером 8, 16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31-м бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде. Числовые диапазоны для этого типа данных следующие:
o 8-разрядное целое — от –128 до +127;
o 16-разрядное целое — от –32 768 до +32 767;
o 32-разрядное целое — от –231 до +231–1.
- Целый тип без знака — двоичное значение без знака, размером 8, 16 или 32 бита. Числовой диапазон для этого типа следующий:
o байт — от 0 до 255;
o слово — от 0 до 65 535;
o двойное слово — от 0 до 232–1.
- Указатель на память двух типов:
o ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
o дальнего типа — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
- Цепочка — представляющая собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт.
- Битовое поле представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
- Неупакованный двоично-десятичный тип — байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
- Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей.
-
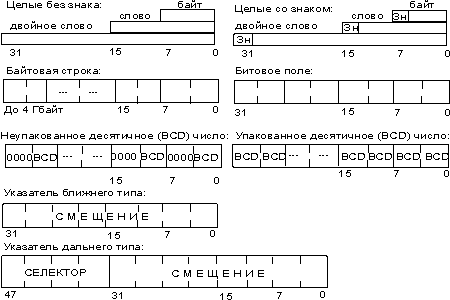
Рис. 4. Основные логические типы данных микропроцессора
|
|
|
