 |


Области использования стека.
|
|
|
|
ФГБОУ ВО «Дагестанский Государственный
Технический Университет»
Факультет КТВТиЭ
Кафедра программного обеспечения ВТ и АС
Курсовая работа
по дисциплине
«Алгоритмы и структура данных»
На тему
«Исследование стека, очереди, дека»
Выполнил:
Студент 3 курса
Группы У-326
Амиргамзаев М.Г.
Приняла:
Сулейманова О.Ш.
Махачкала 2016г.
Аннотация к курсовой работе
В данной курсовой работе рассматриваются основные понятия стека, очереди и дека. Задачи стека, очереди, дека и работа с ними.
Цель курсовой работы: изучение принципов работы стека для организации вычислений на примере теоретико-множественных операций над множествами.
Задачи:
1. Изучить и по анализировать научно-методическую литературу по теме исследования стека, очереди и дека.
2. написать программу демонстрирующую работу стека, очереди и дека на примере теоретико-множественных операций над множествами.
Курсовая работа содержит:
Печатных листов - 44
Рисунков - 11
Приложений - 3
Содержание
Введение………………………………………………………………………… 4
Постановка задачи ………………………………………………………………
Анализ предметной области………………………………………………………
Описание организации структур данных…………………………………………
Описание алгоритма……………………………………………………………….
Формальное описание входных и выходных данных …………………………..
Описание диалога………………………………………………………………….
Описание процедур функций…………………………………………………….
Результаты…………………………………………………………………………
Заключение………………………………………………………………………..
|
|
|
Литература………………………………………………………………………..
Приложение 1…………………………………………………………………….
Приложение 2…………………………………………………………………….
Приложение 3…………………………………………………………………….
Введение
Для решения многих практических задач используются структуры данных – массив, запись, множество и так далее. Цель описания типов данных и последующего описания переменных, как относящихся к этому типу, состоит в том, чтобы зафиксировать на время выполнения программы размер значений, которые присваиваются этим переменным и, соответственно, фиксировать размер выделяемой области памяти для них. Такие переменные называются статическими.
Вследствие фиксирования размера выделенной памяти возникают определенные трудности: неэффективное использование оперативной памяти. Нам, во многих случаях, заранее не известны значения той или иной переменной, и даже факт существования этого значения. Для решения задач мы можем использовать только статические переменные, но мы не знаем значения результата и его размеры, поэтому нам бы пришлось выделять место в памяти для максимально возможного итогового значения, что приводит к нерациональному использованию памяти машины.
Созданные и не описанные заранее, переменные размещаются на свободные участки в динамической области оперативной памяти. Такой способ распределения памяти называется динамическим. Существуют множество типов динамических структур данных, среди них, такие как стек, очередь, линейные списки, деки, деревья и другие.
В некоторых случаях решение задачи эффективней при использовании стеков, в других деревьев, в-третьих, – следующих. В этой работе неполный обзор стеков.
Стек характерен тем, что получить доступ к его элементам можно лишь с одного конца, называемого вершиной стека. В этой курсовой работе реализована программа которая добавляет, удаляет элементы стека и показывает сколько элементов содержит стек.
|
|
|
Очередь характеризуется тем же что и стек, но очередь организованно по другому принципу. В стеке в поле указатель содержится адрес предыдущего информационного поля. В очереди поле указатель содержит адрес следующего элемента.
Дек отличается от стека и очереди тем что доступ к его элементам осуществляется с обеих сторон. Дек содержит два поля указателя, один на предыдущий и другой на следующий.
Постановка задачи
Рассмотреть и реализовать:
1. Создание стека
Добавление элемента в стек.
Освобождение памяти, выделенное под данный элемент.
2. Создание очереди
Добавление элемента в очередь.
Освобождение памяти, выделенное под данный элемент.
3. Создание дека
Освобождение памяти, выделенное под данный элемент.
Удаление элемента из дека.
Анализ предметной области
Принципы работы стека
Стек - частный случай линейного односвязного списка, для которого разрешено добавлять или удалять элементы только с одного конца списка, который называется вершиной стека. Если мы удалим элемент, в вершине оказывается следующий. Включение нового элемента как бы проталкивает имеющиеся элементы в сторону дна. Порядок их следования при хранении не нарушается, как и в очередях, массивах и других структурах. Поскольку в каждый момент нужен доступ к одному, верхнему, элементу стека, индексы элементов не нужны.
Наиболее простой из них является стек, представляющий собой последовательность объектов данных, связанных между собой с помощью указателей.
Организация структуры стека
Каждый объект стека связан с последующим с помощью указателя next. Если указатель next равен NULL, то достигнут конец стека. Особенность работы со стеком заключается в том, что новый объект всегда добавляется в начало списка. Удаление также возможно только для первого элемента. Таким образом, данная структура реализует очередь по принципу <первым вошел, последним вышел>. Такой принцип характерен при вызове функций в рекурсии, когда адрес каждой последующей функции записывается в стеке для корректной передачи управления при ее завершении.
Основные операции, которые используются при применении стека:
|
|
|
· Сделать пустым.
· Добавить элемент. Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз.
· Взять элемент. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх.
· Стек пуст.
· Вершина стека: Т.
Процедура <сделать пустым> делает стек пустым, то есть <на дне стека ничего нет>.
Процедура <добавить элемент> добавляет элемент X, типа T, в начало последовательности.
Процедура <взять элемент> применима, если последовательность S
не пустая, она забирает из нее последний элемент, который становится значением переменной X).
Выражение <стек пуст> истинно, если последовательность S пуста.
Выражение <вершина стека> определенно, если последовательность S не пустая, и равно последнему элементу последовательности S.
Особенно явно преимущества стековой организации проявляются при работе в сложных ситуациях, возникающих в программных системах, где на ограниченные ресурсы претендуют несколько конкурирующих задач. Такие ситуации могут встречаться в различных ЭВМ, начиная от небольших однопользовательских систем (при необходимости совместить выполнение фоновой задачи с вводом-выводом) до сложных мультипрограммных систем, управляющих комплексом пользовательских и системных программ. В любом случае от программного обеспечения требуется гибкость, экономия времени выполнения и используемой памяти.
В большинстве процессоров стек (т.е. память со стековым доступом) организован в участке обычной памяти с адресной организацией. Для этого в процессоре имеется специальный регистр - указатель стека Stack Pointer SP. Этот регистр содержит адрес памяти того участка, в который будет осуществляться стековый доступ, а, говоря более точно, адрес "верхушки стека". Указатель стека обычно программно доступен, то есть к нему можно производить обращение как к любому другому регистру.
|
|
|
Стековая память
Стековой называют память, доступ к которой организован по принципу: "последним записан - первым считан" (Last Input First Output - LIFO). Использование принципа доступа к памяти на основе механизма LIFO началось с больших ЭВМ. Применение стековой памяти оказалось очень эффективным при построении компилирующих и интерпретирующих программ, при вычислении арифметических выражений с использованием польской инверсной записи. В малых ЭВМ она стала широко использоваться в связи с удобствами реализации процедур вызова подпрограмм и при обработке прерываний.
Принцип работы стековой памяти состоит в следующем. Когда слово А помещается в стек, оно располагается в первой свободной ячейке памяти. Следующее записываемое слово перемещает предыдущее на одну ячейку вверх и занимает его место и т.д. Запись 8-го кода, после H, приводит к переполнению стека и потере кода A. Считывание слов из стека осуществляется в обратном порядке, начиная с кода H, который был записан последним. Заметим, что выборка, например, кода E невозможна до выборки кода F, что определяется механизмом обращения при записи и чтении типа LIFO. Для фиксации переполнения стека желательно формировать признак переполнения.
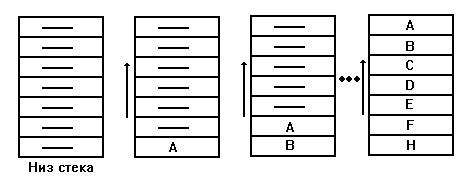
Рис. 4.15. Принцип работы стековой памяти.
Перемещение данных при записи и считывании информации в стековой памяти подобно тому, как это имеет место в сдвигающих регистрах. С точки зрения реализации механизма доступа к стековой памяти выделяют аппаратный и аппаратно-программный (внешний) стеки.
Аппаратный стек представляет собой совокупность регистров, связи между которыми организованы таким образом, что при записи и считывании данных содержимое стека автоматически сдвигается. Обычно емкость аппаратного стека ограничена диапазоном от нескольких регистров до нескольких десятков регистров, поэтому в большинстве МП такой стек используется для хранения содержимого программного счетчика и его называют стеком команд. Основное достоинство аппаратного стека - высокое быстродействие, а недостаток - ограниченная емкость.
Наиболее распространенным в настоящее время и, возможно, лучшим вариантом организации стека в ЭВМ является использование области памяти. Для адресации стека используется указатель стека, который предварительно загружается в регистр и определяет адрес последней занятой ячейки. Помимо команд CALL и RET, по которым записывается в стек и восстанавливается содержимое программного счетчика, имеются команды PUSH и POP, которые используются для временного запоминания в стеке содержимого регистров и их восстановления, соответственно. В некоторых МП содержимое основных регистров запоминается в стеке автоматически при прерывании программ. Содержимое регистра указателя стека при записи уменьшается, а при считывании увеличивается на 1 при выполнении команд PUSH и POP, соответственно.
|
|
|
Области использования стека.
Очень часто некоторые промежуточные результаты работы программы необходимо где-то временно сохранить, прежде чем они будут использованы в дальнейшей обработке. Стек позволяет нам это сделать. Типичная, хотя и не единственная, ситуация заключается в следующем. Пусть некоторому фрагменту программы в машинных командах требуется использовать несколько регистров процессора для хранения промежуточных результатов, которые по окончании его работы уже не будут представлять интереса. Поскольку регистров у процессора не так много, программисты часто стараются не портить их значения без крайней необходимости. Таким образом, с одной стороны, регистры нам действительно нужны, а с другой - не хочется менять их значений.
Рассмотрим простой пример для процессоров с системой команд, принятой в IBM-совместимых компьютерах. Пусть некоторый фрагмент программы должен использовать для промежуточных данных регистры BX и CX. Надежное решение проблемы такое:
SH BX
PUSH CX
<здесь любые манипуляции с BX и CX>
POP CX
POP BX
После завершения работы указанного фрагмента постоянство значений сохраняемых регистров гарантируется независимо от длины и сложности фрагмента.
Подобные фрагменты программисты используют настолько часто, что, начиная с процессора Intel 80286, к системе команд записи в стек была добавлена инструкция PUSHA (от push all), сохраняющая в стеке сразу все регистры процессора.
Одним из важнейших предназначений стека является создание возможностей для вызова подпрограмм. Подпрограммой называют некоторый функционально законченный (в котором решается какая-то частная задача) фрагмент программы, оформленный так, чтобы им можно было пользоваться из различных точек основной программы.
Главной проблемой организации подпрограммы является не столько возможность перехода к ней, сколько создание механизма возврата в ту точку, откуда подпрограмма была вызвана, после окончания ее работы. Именно здесь стек и оказывается необычайно полезен. Логика работы подпрограмм является стандартной и строится следующим образом. В конце выделенного фрагмента, оформляемого в виде подпрограммы, ставится специальная инструкция возврата RET (сокращение происходит от return - вернуться). А в любом месте программы, где потребуется выполнить подпрограмму, помещается ее вызов CALL A, где A - адрес начала подпрограммы.
Рассмотрим, как происходит процесс вызова подпрограммы, подробнее. Пусть подпрограмма расположена начиная с адреса A, ее вызов - в адресе C, а следующая за вызовом инструкция (точка возврата) - в адресе N.
Процесс вызова программы
В принятых обозначениях для перехода к подпрограмме необходимо выполнить два действия:
1) сохранить (в стеке) значение N для последующего возврата;
2) перейти к подпрограмме по адресу A.
Смысл производимых действий становится гораздо более понятным, если учесть, что для хранения адреса очередной команды программы процессор использует специальный регистр - счетчик команд. В процессорах Intel этот регистр обозначается IP (Instruction Pointer) [7]. В новой терминологии смысл перехода к подпрограмме можно сформулировать короче:
1) сохранить в стеке значение PUSH IP;
2) занести A в регистр IP (JMP A).
При возврате из подпрограммы осуществляется обратное действие: из стека извлекается адрес возврата и заносится в IP (POP IP), что обеспечивает переход к этому адресу.
На практике необычайно широко используются вложенные подпрограммы, т.е. одна подпрограмма часто вызывает другую. Очевидно, что здесь способность стека хранить произвольное количество значений и возвращать их по принципу LIFO приходится как нельзя кстати.
Таким образом, мы видим, что благодаря использованию стековой организации памяти процессор получает великолепный механизм организации системы подпрограмм любой степени вложенности.
Подчеркнем, что с точки зрения описанного механизма вызова вложенных подпрограмм ситуация, когда подпрограмма вызывает сама себя (на этом базируется так называемая "рекурсия"), ничем не нарушает алгоритма работы (более того, процессору необычайно трудно проверить, вызывает ли подпрограмма другую или саму себя!). Как было указано выше, проблемы здесь заключаются в передаче параметров и создании локальных переменных так, чтобы они "не портили друг друга" при рекурсивных вызовах. Рассмотрим данную проблему подробнее.
Основываясь на уже имеющихся у нас знаниях о стеке, мы можем предположить, что этот вид памяти поможет нам и здесь. Наличие возможности последовательного сохранения вложенных данных, о которой мы уже неоднократно говорили, дает нам ключ и к решению проблемы переменных в процедурах. В наиболее общих чертах это делается следующим образом. При входе в процедуру в стеке выделяется место под локальные переменные подпрограммы, а по завершении работы это место освобождается. Очевидно, что предлагаемый алгоритм прекрасно сочетается с требованиями рекурсии: при каждом вызове в стеке создаются свои собственные копии переменных, которые никак не мешают друг другу.
На практике процесс создания в стеке структур переменных выглядит несколько сложнее, поскольку согласно принципам программирования, вложенным процедурам не запрещается пользоваться переменными процедур вышележащих уровней вложенности. Поэтому трансляторы организуют фреймы локальных переменных так, чтобы обеспечивать возможность доступа от фреймов одного уровня к другому.
Отметим, что параметры подпрограмм (точнее говоря, их значения или адреса; в первом случае говорят о передаче параметра по значению, а во втором - по ссылке) также передаются при обращении к подпрограмме через стек.
В программировании часто встречаются ситуации, когда одинаковые действия необходимо выполнять многократно в разных частях программы (например, вычисление функции sin x). При этом с целью экономии памяти не следует многократно повторять одну и ту же последовательность команд - достаточно один раз написать так называемую подпрограмму (в терминах языков высокого уровня -процедуру) и обеспечить правильный вызов этой подпрограммы и возврат в точку вызова по завершению подпрограммы. Для вызова подпрограммы необходимо указать ее начальный адрес в памяти и передать (если необходимо) параметры - те исходные данные, с которыми будут выполняться предусмотренные в подпрограмме действия. Адрес подпрограммы указывается в команде вызова CALL, а параметры могут передаваться через определенные ячейки памяти, регистры или стек.
Стек используется практически во всех программах, хотя начинающий программист может и не подозревать, что программа работает со стеком. Связано это с тем, что ряд команд работает со стеком неявным образом:
- call - вызов подпрограммы (запоминает в стеке адрес возврата);
- ret - возврат из подпрограммы (берет из стека адрес возврата);
- int n - программное прерывание (запоминает в стеке адрес возврата и регистр флагов);
- iret - возврат из прерывания (выталкивает из стека адрес возврата и восстанавливает флаги)
Очереди
Очередь — это динамически изменяемый упорядоченный набор элементов. Добавление элемента в очередь производится с одного конца (хвоста очереди), а выборка — с другого конца [(Головы очереди) в соответствии с правилом “Первым пришел — первым ушел” (FIFO: First Input — First Output). Такая очередь является простой очередью без приоритетов. Часто используются очереди с приоритетами, в них более приоритетные элементы включаются ближе к голове очереди, выборка осуществляется, как обычно, с головы очереди.
Очереди находят широкое применение в операционных системах (очереди задач, буфера ввода-вывода, буфер ввода с клавиатуры, очереди в сетях ЭВМ и т.п.), при моделировании реальных процессов и т.д.
Очереди могут иметь векторную или списковую структуру хранения, в свою очередь векторная структура может занимать статическую либо динамическую память. Очередь векторной структуры из-за ограниченности элементов имеет свойство переполнения, когда хвост очереди достигнет конца вектора. В этом случае добавление элементов становится невозможным, даже если в начальной части вектора будут свободные элементы из-под выбранных элементов. Для устранения такого недостатка образуют кольцевые очереди. При достижении конца вектора новые элементы добавляются в свободные элементы с начала вектора. Здесь также возможно переполнение, когда хвост догонит голову. Если же голова догонит хвост, то очередь оказывается пустой. Изображение очереди в векторной памяти приведено на рис. 2.3.
un ug ux uk
| + | + | ++ | ++ | … |
Рис2.3
Рис. 2.3. Очередь в векторной памяти: un — указатель начала вектора; uk — указатель конца вектора; uq — указатель головы очереди; ux — указатель хвоста очереди; + — занятые ячейки очереди.
Основными операциями над очередью являются:
• создание и освобождение очереди;
• включение в очередь нового элемента;
• выборка элемента из очереди.
При их выполнении используются такие вспомогательные операции, как проверка наличия элементов, проверка переполнения, организация перехода по кольцу, изменение приоритета и вызванная этим перестройка очереди.
Операции над очередями списковой структуры не вызывают никаких затруднений. Элементы добавляются в начало списка, а выбираются с его конца либо, наоборот, в зависимости от того, какая операция должна выполняться быстрее: включение или выборка элемента.
Операции создания и освобождения очереди векторной структуры. Они такие же, как и при работе со стеками. Дескриптор очереди должен содержать адрес начала вектора, указатели головы, хвоста и конца очереди в виде их адресов или индексов.
Опишем возможные состояния и соответствующие действия при выполнении операций включения и выборки элементов.
Включение в очередь нового элемента. 1. Очередь заполнена — возврат признака переполнения. 2. Очередь пуста — включение элемента в начало очереди, корректировка указателя хвоста. 3. Очередь заполнена частично — добавление в первый свободный элемент с учетом кольцевой организации, корректировка указателя хвоста.
Выборка элемента из очереди. 1. Очередь пуста — возврат соответствующего признака. 2. В очереди единственный элемент — выбрать элемент и установить указатели в начало. Очередь заполнена частично — выбрать элемент с головы очереди с учетом кольцевой организации, скорректировать указатель головы.
Создадим файл, в котором определены структура дескриптора очереди QUE и переменная ql типа QUE; туда же включены функции, реализующие операции над очередями. Дескриптор строится транслятором, память под элементы выделяется динамически по запросу. Этот файл включается директивой #include в исходный файл с программой для работы с очередью. Предварительно должен быть определен тип элемента EL, на пример define int EL. Допускаются типы EL, только такие, что переменным этого типа можно присваивать значения оператором «=». Такими типами являются скалярные типы и структурный тип struct.
Деки
Дек — это разновидность очереди, в которой включение и выборка элементов возможны с обоих концов. Например, дек может использоваться при управлении памятью, когда распределение памяти производится и сверху, и снизу.
В свою очередь, существуют разновидности дека: дек с ограниченным входом и дек с ограниченным выходом. Дек с ограниченным входом допускает включение элементов только на одном конце, а дек с ограниченным выходом допускает выборку элементов только с одного конца.
Деки могут иметь как векторную, так и списковую структуру хранения. Операции над деками такие же, как и над очередями. При векторном способе хранения программная реализация операций достаточна сложна, она упрощается при представлении очереди в виде двунаправленного списка.
|
|
|
