 |


В системе экономических исследований
|
|
|
|
Метод группировок. Под группировкой понимают процесс образования групп единиц совокупности, однородных в каком-либо существенном отношении, а также имеющих одинаковые или близкие значения группировочного признака. Для осуществления группировки устанавливают признак, по которому единицы совокупности распределяют по группам, а также число групп и их обозначение (границы). Группировочный признак есть основание группировки, в зависимости от целей и задач исследования в качестве основания группировки может быть взят один или несколько признаков. Например, при группировке промышленных предприятий в качестве группировочного признака могут быть взяты объем выпущенной продукции, стоимость основных производственных фондов, численность работающих и другие. Выбор исследователем группировочного признака в значительной степени определяет результаты группировки и выводы, которые делаются на их основе [4].
Группировка показателей является неотъемлемой частью почти любого исследования, позволяя изучать экономические явления или процессы в их взаимосвязи и взаимозависимости. Метод группировки сводится к делению массива показателей изучаемой совокупности экономических объектов на качественно однородные группы по соответствующим признакам. Группировка всегда предполагает определенную классификацию явлений и процессов, а также причин и факторов, их обусловливающих, и должна быть научно обоснованной. Нельзя группировать явления или процессы, причины или факторы по случайным признакам, необходимо раскрыть их природу. Посредством экономического анализа устанавливается причинная связь, взаимосвязь и взаимообусловленность, основные причины и факторы лишь после этого устанавливается характер их влияния на основе построения групповых таблиц. Нельзя строить групповую таблицу для выявления второстепенного фактора.
|
|
|
Объединения однотипных предприятий, представляющие собой качественно однородные совокупности имеют возможность широкого применения типологических, структурных и аналитических группировок.
Типологические группировки формируются по однородным предприятиям в целом и по видам производства (по переделам). Например, в рамках машиностроительного предприятия можно выделить группировки литейного производства (с группировками серого и ковкого чугуна, стального и цветного литья), кузнечного производства, холодной штамповки, термообработки, механической обработки, сварки, сборки, нанесения защитных покрытий, прочих хозяйств (с группировками инструментального, складского, ремонтного и транспортного хозяйства).
Структурные группировки позволяют исследовать внутреннее строение показателей, соотношения их отдельных составляющих и используются при изучении деятельности подразделений и функциональных областей внутри предприятий, как в статике, так и в динамике. При этом группировки формируются по уровням производственной мощности, механизации, по производительности труда, по структуре выпускаемой продукции, работ, услуг (по видам и заданному ассортименту).
Аналитические (причинно-следственные) группировки, по существу, предназначены для выявления наличия, направления и формы связи показателей изучаемых объектов, явлений. По характеру признаков, на основании которых строится аналитическая группировка, она может быть качественной (когда выбранный признак построения не имеет количественного выражения) или количественной. По сложности построения различают два типа группировок – простые и комбинированные. С помощью простых группировок изучается взаимосвязь между явлениями, сгруппированными по какому-либо одному признаку. В комбинированных группировках деление изучаемой совокупности сначала производится по одному признаку, а затем внутри каждой группировки – по другому признаку и т.д. Таким образом, могут быть построены двух-, трех-, четырехуровневые группировки и т.д. По форме они соответствуют типологическим и структурным группировкам. При построении аналитических группировок из двух взаимосвязанных показателей один из них рассматривается в качестве фактора, влияющего на второй показатель, рассматривается как результат влияния первого показателя (и наоборот, факторный признак может выступать в качестве результативного).
|
|
|
Информационной основой группировки служит выборочная совокупность однотипных объектов. Выборочная совокупность конструируется по формуле случайной безвозвратной выборки:
 , (2.28)
, (2.28)
где  - необходимый объем выборки;
- необходимый объем выборки;
 - коэффициент доверия;
- коэффициент доверия;
 - общая выборочная дисперсия;
- общая выборочная дисперсия;
 - объем генеральной совокупности;
- объем генеральной совокупности;
 - предельная ошибка выборочной средней.
- предельная ошибка выборочной средней.
В табл. 2.3 представлен пример четырехфакторной группировки промышленных предприятий региона по уровню задолженности по платежам в бюджеты по налогу на прибыль. Определяющим фактором является рентабельность производства. От этого показателя зависит показатель уровня расходов на оплату труда и платежей по единому социальному налогу, а также показатель годового объема реализации продукции.
Таблица 2.3 – Группировка промышленных предприятий региона по уровню задолженности
по налогу на прибыль
| Группы предприятий по размерам задолженности по налогу на прибыль, млн. руб. | Рентабельность производства, % | Затраты на оплату труда на одного работающего, тыс. руб./год | Годовой объем реализации продукции, млрд. руб. |
| До 50 | 5,8 | 58,2 | 58,2 |
| 51 – 100 | 4,5 | 57,7 | 93,6 |
| 101 – 300 | 3,3 | 54,5 | 95,1 |
| 501 – 750 | 3,2 | 58,3 | 162,8 |
| 751 – 1000 | 2,7 | 57,1 | 110,5 |
| 1001 – 1300 | 2,1 | 53,9 | 92,8 |
| 1301 – 1600 | 1,8 | 52,0 | 88,0 |
| 1601 – 2000 | 1,5 | 55,5 | 71,7 |
| 2001 – 2500 | 1,3 | 57,4 | 23,8 |
| 2501 – 3000 | 1,1 | 56,3 | 31,6 |
| Свыше 3000 | 0,8 | 50,6 | 22,9 |
| В ЦЕЛОМ | 2,2 | 57,0 | 851,0 |
Аналитичность табл. 2.3 достаточно высока: чем ниже рентабельность производства на предприятиях, тем выше уровень задолженности по платежам по налогу на прибыль. Как правило, рост рентабельности производства благоприятно сказывается как на годовом объеме реализации продукции предприятия (рост доли рынка сбыта), так и на уровне заработной платы в расчете на одного работающего на предприятии.
|
|
|
В табл. 2.4 представлен пример четырехфакторной группировки по некоторой совокупности торговых предприятий, определяющим фактором в которой является объем товарооборота.
От показателя объема товарооборота зависят показатели среднегодового оборота на одного работника (производительность труда), товарных запасов (скорость товарооборота) и уровня издержек обращения. Очевидна высокая аналитичность приведенной таблицы 3.2: рост объема товарооборота весьма благоприятно сказывается на всех перечисленных выше показателях деятельности.
Правильная группировка показателей дает возможность исследовать зависимость между ними, более глубоко разобраться в сущности экономических явлений, систематизировать материалы анализа, определить главное, характерное, типичное. Одним из важнейших вопросов при проведении исследований является вопрос выбора интервала группировки. С этой целью применяются два подхода.
Первый подход предполагает деление всей совокупности данных на группы с равными интервалами значений. Этот подход используется наиболее часто, так как при выборе границ интервалов отсутствует элемент субъективизма. В рамках этого подхода длина интервала группировки определяется по следующим формулам Стерджеса:
 ; (2.29)
; (2.29)
 , (2.30)
, (2.30)
где  - максимальное значение признака в исследуемой совокупности данных;
- максимальное значение признака в исследуемой совокупности данных;
 - минимальное значение признака в исследуемой совокупности данных;
- минимальное значение признака в исследуемой совокупности данных;
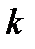 - число групп с одинаковой длиной интервала;
- число групп с одинаковой длиной интервала;
- число наблюдений.
Таблица 2.4 – Группировка специализированных магазинов по объему товарооборота
| Группы магазинов по размерам розничного товарооборота, млн. руб. | Среднегодовой оборот на одного работника, тыс. руб. | Товарные запасы, суток | Уровень издержек обращения, % к обороту |
| До 150 | 9,94 | ||
| 151 – 200 | 9,15 | ||
| 201 – 300 | 8,79 | ||
| 301 – 400 | 8,45 | ||
| 401 – 600 | 8,32 | ||
| 601 – 800 | 8,12 | ||
| 801 – 1000 | 7,95 | ||
| 1001 – 1200 | 7,73 | ||
| 1201 – 1500 | 7,57 | ||
| 1501 – 2000 | 7,13 | ||
| Свыше 2000 | 6,52 | ||
| В ЦЕЛОМ | 8,88 |
|
|
|
Очевидно, что знаменатель дроби в формуле (2.29) численно равен количеству групп или интервалов, на которое разбивается исследуемая совокупность данных. Таким образом, можно рассчитать оптимальное число групп, соответствующее некоторому числу наблюдений, согласно формуле Стерджеса (табл. 2.5).
Таблица 2.5 – Результаты расчета оптимального числа групп согласно формуле Стерджеса
| Число наблюдений
| 9-14 | 15-24 | 25-44 | 45-89 | 90-164 |
| Число групп
|
Прямое применение формулы Стерджеса предполагает отсутствие каких-либо ограничений на параметры группировки. Однако, возможно введение таких ограничений. Например, заранее устанавливается количество групп исходя из представлений аналитика о качественной однородности выделяемых групп единиц совокупности. В таком случае длина интервала группировки определяется по формуле (2.30).
В соответствии со вторым подходом интервалы группировки можно выбирать равными или неравными, как возрастающими, так и убывающими. Такой подход обычно применяется в тех случаях, когда имеет место большая вариация ( ) и неравномерность распределения признака по всему интервалу его изменения. При выборе размера интервала группировки руководствуются здравым смыслом и логикой, опираясь при этом на опыт и традиционно сложившиеся подходы в группировке данных. При втором подходе интервалы часто выбирают таким образом, чтобы группы оказались равнозаполненными.
) и неравномерность распределения признака по всему интервалу его изменения. При выборе размера интервала группировки руководствуются здравым смыслом и логикой, опираясь при этом на опыт и традиционно сложившиеся подходы в группировке данных. При втором подходе интервалы часто выбирают таким образом, чтобы группы оказались равнозаполненными.
Индексный метод. Всякий индекс исчисляется соизмерением отчетной величины с базисной величиной. При этом сравниваются в относительных числах производительность труда, цены, товарооборот, объемы производства, затраты на производство и реализацию продукции (работ, услуг) и т.д. Под индексом понимается статистический относительный показатель, характеризующий соотношение во времени (динамические индексы) или в пространстве (территориальные индексы) разнообразных социально-экономических явлений – цен отдельных товаров, объемов производства и реализации продукции (работ, услуг), себестоимости и других [4].
Выделяют индивидуальные и сводные индексы. Индивидуальные (частные) индексы выражают соотношение непосредственно соизмеримых величин и являются исходными для индексных расчетов. К таким индексам относятся, например, индексы реализации определенного вида продукции (работ, услуг) в отчетном и базисном периодах. Сводные индексы включают разновидности групповых и общих индексов ихарактеризуют соотношения сложных явлений. К таким индексам относятся, например, групповой индекс продукции легкой промышленности или общий индекс объема розничного товарооборота по району. По существу, групповые (общие) индексы представляют собой некоторую среднюю величину из индивидуальных (частных) индексов. Таким образом, групповой (общий) индекс всегда меньше, чем наибольший из индивидуальных (частных) индексов, и всегда больше, чем минимальный из них.
|
|
|
Расчет индивидуального (частного) индекса ведется путем деления величины исследуемого элемента (показателя) в отчетном периоде на соответствующую величину этого элемента (показателя) в базисном периоде. Например, формула для расчета индивидуального индекса ( ), характеризующего изменение цены определенного товара в отчетном периоде по сравнению с базисным, будет выглядеть так:
), характеризующего изменение цены определенного товара в отчетном периоде по сравнению с базисным, будет выглядеть так:
 , (2.31)
, (2.31)
где  - цена данного товара соответственно в отчетном и базисном периодах.
- цена данного товара соответственно в отчетном и базисном периодах.
Общая формула для расчета индивидуальных индексов такова:
 , (2.32)
, (2.32)
где  - индексируемый показатель, соответственно, в отчетном и базисном периодах.
- индексируемый показатель, соответственно, в отчетном и базисном периодах.
Расчет группового индекса может производиться по формулам агрегатного индекса, среднего арифметического индекса, среднего гармонического индекса.
Агрегатный индекс является основной формой сводных индексов и характеризует относительные изменения индексируемого показателя в отчетном периоде по сравнению с базисным периодом. Числитель и знаменатель агрегатных индексов представляют собой суммы произведений индексируемого показателя и его веса за два сравниваемых периода.
Формула агрегатного индекса с весами текущего периода:
 , (2.33)
, (2.33)
где - индексируемые показатели, соответственно, в отчетном и базисном периодах;
 - веса индексов в отчетном периоде;
- веса индексов в отчетном периоде;
- количество разновидностей индексируемого показателя.
Формула агрегатного индекса с весами базисного периода:
 , (2.34)
, (2.34)
где 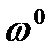 - веса индексов в базисном периоде.
- веса индексов в базисном периоде.
Агрегатный индекс с совместным изменением обоих показателей:
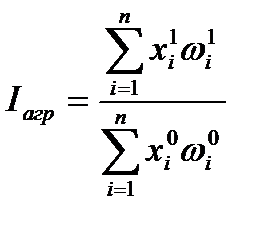 . (2.35)
. (2.35)
В системе анализа коммерческой деятельности важную роль играет исследование динамики индекса ассортиментных сдвигов в товарообороте. Указанный индекс показывает изменение товарооборота за счет сдвигов в внутригрупповой, ассортиментной структуре продажи товаров. Данный индекс ( ) строится по следующей формуле:
) строится по следующей формуле:
 , (2.36)
, (2.36)
где 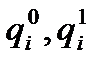 - количество i –го сорта товара, реализованного, соответственно, в базисном и отчетном периодах;
- количество i –го сорта товара, реализованного, соответственно, в базисном и отчетном периодах;
 - цена i –го вида (сорта) товара соответственно в базисном и отчетном периодах;
- цена i –го вида (сорта) товара соответственно в базисном и отчетном периодах;
- количество видов (сортов) реализуемого товара в ассортименте.
В практике экономического анализа коммерческой деятельности достаточно часто используется целый ряд других индексов.
Например, индекс издержкоемкости товарооборота, характеризующий влияние на динамику среднего уровня издержек обращения изменений состава товарооборота по ряду признаков:
- по товарам;
- по видам оборотов (складской и транзитный в оптовой торговле);
- по торговым системам и другим.
Исчисляется индекс издержкоемкости товарооборота как отношение двух сумм издержек, рассчитанных на одинаковые по объему, но разные по структуре суммы товарооборота при равных групповых уровнях издержек обращения (обычно это издержки базисного периода):
 , (2.37)
, (2.37)
где  - уровни издержек обращения по группам товаров (равны частному от деления общей суммы издержек на сумму товарооборота по группам товаров), соответственно, в отчетном и базисном периодах;
- уровни издержек обращения по группам товаров (равны частному от деления общей суммы издержек на сумму товарооборота по группам товаров), соответственно, в отчетном и базисном периодах;
 - товарооборот по группам товаров, соответственно, в отчетном и базисном периодах;
- товарооборот по группам товаров, соответственно, в отчетном и базисном периодах;
- количество рассматриваемых групп товаров в общем объеме товарооборота.
Индекс физического объема розничного товарооборота отражает динамику товарооборота в сопоставимых ценах и исчисляются отдельно по каждой товарной группе, по продовольственным и непродовольственным товарам. Когда количество товаров измеряется в натуральных единицах, используется агрегатная форма этого индекса ( ):
):
 , (2.38)
, (2.38)
где - объемы реализации товаров по товарным группам, соответственно, в отчетном и базисном периодах;
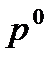 - цены товаров по группам базисного периода;
- цены товаров по группам базисного периода;
 - количество рассматриваемых товарных групп.
- количество рассматриваемых товарных групп.
В тех же случаях, когда продажа товаров учитывается в денежных единицах, индекс физического объема розничного товарооборота строится по формуле, в которой в числителе товарооборот отчетного периода  пересчитывается в базисные цены:
пересчитывается в базисные цены:
 . (2.39)
. (2.39)
Индекс поставки товаров ( ) характеризует динамику оптового товарооборота. При этом используется система индексов товарооборота в сопоставимых ценах. Так как поставка продовольственных товаров учитывается в натуральных единицах, то их индекс поставки строится по агрегатной форме. Так как поставка непродовольственных товаров учитывается в денежных единицах, то их индекс поставки строится по формуле индекса физического объема товарооборота с использованием индивидуальных индексов цен. В общем индексе поставки товаров (включая продовольственные и непродовольственные товары) числитель агрегируется из числителей двух предыдущих индексов, а знаменатель – из их знаменателей:
) характеризует динамику оптового товарооборота. При этом используется система индексов товарооборота в сопоставимых ценах. Так как поставка продовольственных товаров учитывается в натуральных единицах, то их индекс поставки строится по агрегатной форме. Так как поставка непродовольственных товаров учитывается в денежных единицах, то их индекс поставки строится по формуле индекса физического объема товарооборота с использованием индивидуальных индексов цен. В общем индексе поставки товаров (включая продовольственные и непродовольственные товары) числитель агрегируется из числителей двух предыдущих индексов, а знаменатель – из их знаменателей:
 , (2.40)
, (2.40)
где  - розничные цены продовольственных и непродовольственных товаров в базисном и отчетном периодах;
- розничные цены продовольственных и непродовольственных товаров в базисном и отчетном периодах;
 - количество поставленных продовольственных и непродовольственных товаров в базисном и отчетном периодах;
- количество поставленных продовольственных и непродовольственных товаров в базисном и отчетном периодах;
- индивидуальные (или групповые) индексы розничных цен;
 - количество ассортиментных групп соответственно продовольственных и непродовольственных товаров.
- количество ассортиментных групп соответственно продовольственных и непродовольственных товаров.
В экономическом анализе широко используются такие индексы:
- индекс средних розничных цен;
- индекс структурных сдвигов;
- индекс стоимости основных фондов;
- индекс тарифный (транспортный);
- индекс территориальный;
- индекс трудоемкости товарооборота;
- индекс физического объема внешней торговли;
- индекс физического объема продукции;
- индекс цен внешней торговли;
- индекс цен потребительских товаров и услуг;
- индексы закупочных цен;
- индексы оптовых цен на промышленную продукцию;
- индексы производительности труда в торговле;
- индексы себестоимости строительной продукции;
- индексы соотношения цен;
- индексы цен и тарифов на услуги;
- индексы цен на продукцию строительства;
- индексы цепные;
- индексы биржевые (фондовые);
- индексы валютной корзины;
- индекс деловой активности;
- индекс заработной платы;
- индекс конкурентоспособности промышленных товаров;
- индекс котировки (курсов) акций;
- индекс курсов;
- индекс сбыта;
- индекс себестоимости;
- индекс цен и тарифов на услуги населению;
- индекс цен по капиталовложениям и др.
Математико-статистические методы изучения связей в современных системах экономического анализа применяются весьма широко и включают корреляционный, регрессионный, дисперсионный, кластерный анализ. Указанные методы используются в системе стохастического моделирования и, в определенной степени, представляют собой дополнение и углубление системы детерминированного анализа [4, 5]. При использовании этих методов требуется обеспечить достижение следующих целей:
- оценка уровней влияния факторов на результативный показатель, по которым нельзя построить жестко детерминированную модель;
- изучение и сравнение уровней влияния факторов, которые невозможно включить в одну и ту же детерминированную модель;
- выделение и оценка уровней влияния сложных факторов, которые не могут быть выражены каким-то одним количественным показателем.
Применение стохастического подхода, в отличие от детерминированного подхода, требует выполнения некоторых предпосылок. Прежде всего, это требование наличия достаточно большой совокупности объектов. Так, если для анализа детерминированной модели достаточно даже одного объекта, то для анализа стохастической модели необходима уже совокупность объектов. Кроме того, для стохастического анализа нужен достаточный объем наблюдений, так как лишь по одному-двум наблюдениям нельзя судить о характере стохастической связи. Особенностью использования стохастических моделей в экономике считается трудность получения совокупности данных достаточного объема. Если, например, в ходе технического исследования можно повторить тот или иной эксперимент, то в экономике этого сделать нельзя. Поэтому в системе экономического анализа нередко приходится работать в условиях малых выборок (менее 20 наблюдений). Кроме того, одним из требований статистических расчетов при построении регрессии является достаточность количества наблюдений, которое в 6-8 раз должно превышать количество исследуемых факторов, что в практике экономического анализа наблюдается крайне редко.
Поскольку стохастическая модель, как правило, выражается уравнением регрессии, ее построение требует соблюдения ряда условий:
- случайность наблюдений;
- качественная и количественная однородность совокупности (показателем количественной однородности совокупности является показатель вариации, который рассматривается ниже);
- наличие специального математического аппарата для проведения вычислений.
При этом следует учитывать, что стохастическое моделирование предназначено для решения трех основных задач:
1. Установление факта наличия или отсутствия статистически значимой связи между изучаемыми результативными и факторными признаками.
2. Прогнозирование неизвестных значений результативных показателей по заданным значениям факторных признаков (это, по существу, задачи интерполяции и экстраполяции).
3. Выявление причинных связей между изучаемыми показателями, измерение их тесноты и сравнительный анализ степени влияния.
Проведение стохастического моделирования и выявление связей представляет собой достаточно сложный процесс, состоящий из нескольких этапов, на каждом из которых необходимо выполнить определенные процедуры. Ниже приводятся характеристики основных этапов стохастического моделирования.
Этап 1. Качественный анализ:
- постановка цели анализа;
- определение совокупности данных, используемых для анализа;
- определение результативных признаков;
- определение факторных признаков;
- выбор периода анализа;
- выбор метода анализа.
Этап 2. Предварительный анализ моделируемой совокупности данных:
- проверка однородности совокупности;
- исключение аномальных наблюдений;
- уточнение необходимого объема выборки;
- установление законов распределения изучаемых переменных.
Этап 3. Построение регрессионной модели экономического объекта:
- перебор (чередование, выбор) конкурирующих вариантов построения модели;
- уточнение перечня исследуемых факторов, включаемых в модель;
- расчет оценок параметров уравнений регрессии.
Этап 4. Оценка адекватности модели:
- проверка статистической значимости уравнения регрессии в целом и его отдельных параметров;
- проверка соответствия формальных свойств полученных оценок задачам исследования.
Этап 5. Экономическая интерпретация и практическое использование модели. На данном этапе выполняются следующие действия:
- определение пространственно-временной устойчивости полученных зависимостей;
- оценка прогностических свойств модели.
Перечисленные выше процедуры стохастического анализа имеют ряд методологических особенностей и теоретических аспектов:
1. Для анализа следует брать всю имеющуюся совокупность данных. Если эта совокупность слишком велика, необходимо обеспечить тщательность составления выборки из этой совокупности. Выборки должна быть типичной (практически проверенной) для данного круга явлений, в противном случае анализ не будет иметь смысла, поскольку его результаты не позволят сделать значимые выводы для всей совокупности данных.
2. В качестве результативных признаков в экономическом анализе используют либо показатели экономического эффекта (выручка, товарооборот, объем реализации и т.п.), либо показатели экономической эффективности (рентабельность, оборачиваемость, производительность и т.п.). Более предпочтительно использование не абсолютных, а относительных показателей. Этому есть несколько причин, в том числе сравнимость относительных показателей и большая близость их распределений нормальному закону распределения. Последнее обстоятельство также важно, поскольку нормальность распределения признаков является основной предпосылкой корреляционно-регрессионного анализа.
3. В качестве факторных признаков следует выбирать показатели, которые комплексно характеризуют исследуемое экономическое явление. Также предпочтительнее ориентироваться на относительные показатели.
- В анализе экономических явлений выделяют два подхода – статистический и динамический. Чаще используется статистический подход, так как он отличается относительной простотой и не требует применения сложных математических методов. Динамический анализ (исследование рядов данных во времени) часто предполагает рассмотрение автокорреляционных зависимостей, что требует применения сложного эконометрического инструментария.
5. Предварительная обработка рядов данных начинается с установления законов распределения (распределение должно быть близко к нормальному). В условиях использования малых выборок проверка нормальности распределения проводится путем сравнения эмпирических коэффициентов асимметрии и эксцесса с их средними квадратическими ошибками (их аналитические выражения приводятся ниже). При этом должна быть подтверждена нормальность распределения рядов данных.
6. Проверка однородности сводится к проверке уровня коэффициента вариации. Если совокупность неоднородна, следует исключить из нее наиболее отклоняющиеся, «аномальные» наблюдения, поскольку именно эти наблюдения, скорее всего, нетипичны для данного исследования. Для устранения таких аномальных наблюдений используется правило «трех сигм».
7. Уточнение перечня факторов может осуществляться, например, путем расчета матрицы парных коэффициентов корреляции. Перебор (выбор) конкурирующих вариантов модели, осуществляется, как правило, с использованием компьютеров и прикладных программ.
- Проверка устойчивости модели осуществляется расчетом ее параметров на усеченной или расширенной совокупности, а также на той же совокупности, но уже в другом интервале времени.
При изучении некоторой совокупности данных в системе стохастического моделирования используют ряд специфических характеристик. К таким характеристикам относятся средние значения. При стохастическом анализе больших массивов данных обычно интересуются двумя аспектами:
- величинами, которые характеризуют ряд значений как целого (характеристиками общности);
- величинами, которые описывают различие между членами совокупности (характеристиками вариации, разброса значений).
Так, все средние величины относятся в первой группе показателей (характеристикам общности), поскольку являются характеристиками изучаемой совокупности как целого. Кроме средних величин, в качестве показателей (характеристик) общности также используются такие характеристики как середина интервала, мода, медиана.
Середина интервала возможных значений показателя  определяется по следующей формуле:
определяется по следующей формуле:
 . (2.41)
. (2.41)
Мода представляет собой такое значение изучаемого признака, которое среди всех его значений встречается наиболее часто (можно сказать, что это типичное значение случайной величины). В этом случае говорят об унимодальном распределении. Если же чаще других встречаются два или более различных значений, то такую совокупность данных называют соответственно бимодальной или мультимодальной. Если же ни одно из значений совокупности не встречается чаще других (например, все значения совокупности встречаются по одному разу или равное количество раз), то такая совокупность считается безмодальной.
Медиана представляет собой такое значение изучаемой величины, которое делит изучаемую совокупность на две равные части, в которых количество членов со значениями меньше медианы равно количеству членов со значениями больше медианы. Медиану можно найти только в таких совокупностях, которые содержат нечетное количество членов. В отличие от средней величины, медиана не зависит от крайних значений показателей (если увеличивается максимальное или минимальное значение исследуемого показателя, то вместе с ним возрастают все средние величины, но медиана остается неизменной). Поэтому медиана представляется более удобной характеристикой совокупности в тех случаях, когда совокупность данных неоднородна и имеет резкие флуктуации.
В качестве показателей (характеристик) вариации чаще всего используются размах вариации, среднее линейное отклонение, среднеквадратическое отклонение, дисперсия, коэффициент вариации.
Размах вариации является одним из показателей вариации и характеризует пределы колеблемости (вариацию) индивидуальных значений признака (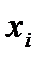 ) в совокупности. Размах вариации (
) в совокупности. Размах вариации ( ) представляет собой разность между наибольшим (
) представляет собой разность между наибольшим ( ) и наименьшим (
) и наименьшим ( ) значениями i -го признака:
) значениями i -го признака:
 . (2.42)
. (2.42)
Среднее линейное отклонение (или средний модуль отклонения  ) представляет собой отклонение значения признака () от среднего арифметического (
) представляет собой отклонение значения признака () от среднего арифметического ( ) и вычисляется по формуле
) и вычисляется по формуле
 . (2.43)
. (2.43)
При использовании весовых коэффициентов ( ) формула расчета средневзвешенного среднего линейного отклонения имеет вид
) формула расчета средневзвешенного среднего линейного отклонения имеет вид
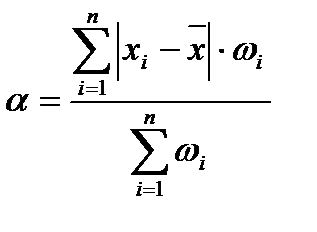 , (2.44)
, (2.44)
где  - частота, с которой в изучаемой совокупности встречается значение признака .
- частота, с которой в изучаемой совокупности встречается значение признака .
Наиболее распространены при изучении вариации значений данных получили величины среднеквадратического отклонения и дисперсии.
Дисперсия представляет собой математическое ожидание квадрата отклонения случайной величины от ее математического ожидания. Дисперсией также называют средний квадрат отклонения значений признака от его среднего отклонения в генеральной совокупности. Чем больше величина дисперсии, тем сильнее разброс значений признака вокруг среднего. Расчет величины дисперсии ( ) ведут как по формуле взвешенной дисперсии, так и по формуле невзвешенной дисперсии. Формула расчета невзвешенной дисперсии имеет вид
) ведут как по формуле взвешенной дисперсии, так и по формуле невзвешенной дисперсии. Формула расчета невзвешенной дисперсии имеет вид
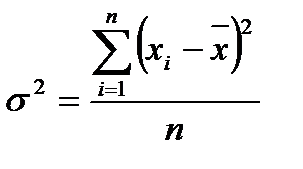 , (2.45)
, (2.45)
где  - математическое ожидание случайной величины .
- математическое ожидание случайной величины .
В свою очередь, значение математического ожидания случайной величины можно определить по формуле
 . (2.46)
. (2.46)
Формула расчета взвешенной дисперсии имеет такой вид:
 . (2.47)
. (2.47)
Среднеквадратическое отклонение ( ) представляет собой корень второй степени из среднего квадрата отклонений значений признака от их средней величины (математического ожидания):
) представляет собой корень второй степени из среднего квадрата отклонений значений признака от их средней величины (математического ожидания):
 ; (2.48)
; (2.48)
 ; (2.49)
; (2.49)
 . (2.50)
. (2.50)
Чем больше величина или , тем сильнее разброс значений () вокруг среднего. Следует отметить, что всегда больше модуля среднего линейного отклонения . Так, для нормально распределенных величин имеет место соотношение
 . (2.51)
. (2.51)
Если соотношение (2.51) не выполняется, то это свидетельствует о том, что в исследуемом массиве данных есть элементы, неоднородные с основной массой, т.е. сильно выбивающиеся по своей величине из общего ряда. В зависимости от решаемой задачи следует определить порядок исключения этих выбивающихся элементов из рассмотрения, либо не использовать их при построении некоторых моделей, поскольку эти элементы являются как бы исключениями из правила.
Как следует из определения величина среднеквадратического отклонения зависит от абсолютных значений изучаемого признака: чем больше величины , тем больше будет . Поэтому вводится показатель коэффициента вариации, чтобы сравнивать ряды данных, отличающихся по абсолютным величинам:
 . (2.52)
. (2.52)
Коэффициент вариации является относительной мерой вариации и представляет собой отношение среднеквадратического отклонения () к средней величине признака (). Коэффициент вариации является показателем количественной неоднородности исследуемой совокупности данных. При этом значени
|
|
|
