 |


Г - возможность нейтрализации / восстановления.
|
|
|
|
1 - легко; 2 - трудно; 3 - очень трудно; 4 - невозможно.
Д - частота появления. Данная оценка отражает сравнительную характеристику частоты появления конкретной угрозы в сравнении с другими угрозами:
0 - неизвестна; 1 - низкая; 2 - средняя; 3 - высокая; 4 - сверх высокая.
Е - потенциальная опасность - оценивается опасность угрозы с точки зрения ущерба,:
1 - низкая; 2 - высокая; 3 - сверх высокая.
Ж - источник появления:
1 - внутренний; 2 - внешний.
Под внутренним источником понимается воздействие внутренних факторов, таких, как персонал, сбои и т.п. К внешним относят такие факторы, как стихийные бедствия, техногенные факторы (например, отключение электроэнергии), преднамеренные воздействия отдельных нарушителей или групп на безопасность.
З - уровень необходимых знаний - оценивается уровень профессиональной подготовки нарушителей для подготовки и реализации соответствующей угрозы:
1 - фундаментальные знания системной организации ресурсов, протоколов связи и др.; 2 - знание операционной системы; 3 - знание языков программирования; 4 - элементарные знания в области вычислительной техники.
И - затраты на проектирование и разработку злоупотребления:
1 - большие; 2 - средние; 3 - незначительные затраты.
К - простота реализации:
1 - очень трудно; 2 - трудно; 3 - относительно нетрудно; 4 - легко;
Л - потенциальное наказание в рамках существующего законодательства. При оценке угроз по данному критерию следует принимать во внимание факт возможности доказательства авторства программного злоупотребления и наличие юридической ответственности за соответствующие нарушения:
1 - строгое наказание (вплоть до уголовной ответственности); 2 - незначительное наказание; 3 - наказание отсутствует.
|
|
|
Таблица 1 Пример оценки угроз безопасности
| Угрозы безопасности | А | Б | В | Г | Д | Е | Ж | З | И | К | Л | Ком-плексная оценка | |
| Общесистемные угрозы | |||||||||||||
| Недоступность информации | 2.5 | 1.0 | 3.0 | 1.5 | 2.5 | 1.0 | 3.5 | 2.5 | 2.5 | 2.5 | 2.83 | ||
| Ошибки пользователя | 1,2,3 | 3.0 | 2.5 | 3.5 | 2.0 | 2.5 | 1.0 | 4.0 | 3.0 | 2.5 | 1.5 | 2.98 | |
| Ошибки программного обеспечения | 1,2,3 | 3.5 | 2.5 | 3.0 | 2.0 | 2.0 | 1.0 | 0.0 | 3.0 | 2.5 | 1.5 | 2.75 | |
| Неправильная маршрутизация | 2.0 | 1.5 | 4.0 | 2.0 | 2.0 | 2.0 | 1.0 | 1.5 | 1.5 | 1.5 | 2.65 | ||
| Аппаратные сбои | 1,2,3 | 4.0 | 1.5 | 1.5 | 2.5 | 1.5 | 1.0 | 0.0 | 3.0 | 1.5 | 2.5 | 2.65 | |
| Перегрузка трафика | 1.5 | 1.0 | 1.5 | 1.0 | 1.5 | 1.5 | 1.0 | 2.5 | 1.5 | 2.5 | 2.48 | ||
| Отказ в обслуживании | 3.0 | 1.5 | 2.5 | 3.0 | 2.0 | 1.5 | 3.5 | 2.5 | 3.0 | 2.5 | 2.95 | ||
| Программные злоупотребления | |||||||||||||
| Программы открытия паролей | 3.0 | 2.5 | 1.5 | 2.5 | 2.0 | 1.5 | 3.0 | 2.5 | 3.0 | 2.5 | 2.90 | ||
| Программы захвата паролей | 2.5 | 1.5 | 2.0 | 1.5 | 1.5 | 1.5 | 2.0 | 2.5 | 2.5 | 2.5 | 2.70 | ||
| Люки | 1,2,3 | 3.5 | 2.5 | 3.5 | 0.5 | 3.0 | 1.5 | 2.0 | 2.0 | 3.5 | 2.5 | 2.93 | |
| Логические бомбы | 3.5 | 2.5 | 3.0 | 0.5 | 2.5 | 1.5 | 2.0 | 2.0 | 3.5 | 2.5 | 2.88 | ||
| Троянские кони | 1,2,3 | 3.5 | 2.5 | 3.5 | 0.5 | 3.0 | 1.5 | 2.0 | 2.5 | 2.5 | 2.5 | 2.90 | |
| Репликаторы | 2.5 | 1.0 | 1.5 | 0.5 | 2.5 | 2.0 | 2.0 | 2.0 | 2.5 | 2.5 | 2.65 | ||
| Программные закладки | 2.5 | 2.5 | 2.5 | 1.5 | 2.5 | 1.5 | 1.0 | 2.0 | 3.0 | 2.5 | 2.78 | ||
| Скрытые каналы | 3.5 | 2.5 | 3.5 | 0.5 | 1.5 | 1.5 | 2.0 | 2.5 | 1.5 | 2.5 | 2.78 | ||
| Компьютерные вирусы | 2.5 | 1.5 | 2.0 | 3.0 | 1.5 | 2.0 | 2.0 | 2.0 | 3.5 | 1.5 | 2.78 | ||
| Работа между строк | 2.5 | 2.5 | 2.5 | 1.5 | 2.5 | 1.5 | 1.5 | 1.5 | 2.5 | 2.5 | 2.75 | ||
| Маскарад | 1,2,3 | 3.0 | 2.5 | 3.5 | 1.5 | 2.0 | 2.0 | 4.0 | 3.0 | 2.5 | 2.5 | 3.03 | |
| Подкладывание свиньи | 1,2,3 | 3.0 | 2.5 | 2.5 | 1.5 | 2.5 | 2.0 | 1.5 | 1.5 | 1.5 | 2.5 | 2.75 | |
| Пинание | 4.0 | 1.0 | 1.5 | 1.5 | 1.5 | 2.0 | 3.0 | 3.0 | 2.5 | 2.5 | 2.83 | ||
| Раздеватели - пиратство | 3.5 | 2.5 | 3.5 | 1.5 | 1.5 | 2.0 | 1.5 | 1.5 | 3.5 | 1.5 | 2.83 | ||
| Повторное использование объектов | 2.5 | 2.5 | 3.0 | 1.5 | 2.0 | 1.0 | 4.0 | 1.0 | 2.5 | 2.5 | 2.83 | ||
| Суперзаппинг | 1,2,3 | 2.5 | 2.5 | 2.5 | 1.5 | 3.0 | 1.5 | 3.5 | 2.5 | 2.0 | 2.5 | 2.90 | |
| Атаки салями | 2.5 | 2.5 | 3.5 | 0.5 | 1.5 | 1.0 | 1.5 | 1.5 | 2.0 | 1.5 | 2.60 | ||
| Воздушные змеи | 1.5 | 1.0 | 1.5 | 2.5 | 2.0 | 2.0 | 3.5 | 1.5 | 1.5 | 1.5 | 2.63 | ||
| Другие злоупотребления | |||||||||||||
| Злоупотребления информацией | 1,2,4 | 2.5 | 1.5 | 2.5 | 1.5 | 2.5 | 1.5 | 4.0 | 2.5 | 3.5 | 2.5 | 2.93 | |
| Перехват ПЭМИН | 3.5 | 3.0 | 4.0 | 0.5 | 1.5 | 2.0 | 4.0 | 2.0 | 2.5 | 2.5 | 2.98 | ||
| Перехват информации | 3.5 | 2.5 | 3.5 | 3.0 | 2.5 | 2.0 | 1.0 | 1.5 | 2.5 | 2.5 | 2.93 | ||
| Анализ трафика | 3.5 | 2.5 | 2.5 | 1.5 | 1.5 | 2.0 | 1.5 | 1.5 | 1.5 | 2.5 | 2.73 | ||
| Сетевые анализаторы | 4.0 | 2.5 | 2.5 | 1.5 | 1.5 | 2.0 | 1.5 | 1.5 | 2.0 | 2.5 | 2.78 | ||
| Умышленное повреждение данных и программ | 2.0 | 2.0 | 2.5 | 1.0 | 2.5 | 1.0 | 3.5 | 2.5 | 1.5 | 1.0 | 2.68 | ||
| Повреждение аппаратных средств | 3.5 | 1.5 | 2.5 | 1.5 | 2.0 | 1.5 | 0.0 | 2.0 | 1.0 | 1.0 | 2.53 | ||
| Кража информации | 1,2,3 | 2.0 | 2.5 | 3.5 | 1.5 | 2.0 | 1.5 | 2.5 | 2.0 | 1.5 | 1.0 | 2.70 | |
| Другие виды мошеничества | 2.0 | 2.0 | 3.5 | 1.5 | 2.5 | 1.5 | 2.5 | 2.0 | 2.5 | 2.0 | 2.80 | ||
| Примечание. Максимальные оценки для графы А - 4; для графы Б - 4; для графыВ - 3; для графы Г - 4; для графы Д - 4; для графы Е - 3; для графы Ж - 2; для графы З - 4; для графы И - 3; для графы К - 4; для графы Л - 3. |
|
|
|
Комплексная оценка угрозы может быть рассчитана следующим образом:
 , (1)
, (1)
где  - оценка i-й угрозы по j-му параметру; m - количество параметров оценки;
- оценка i-й угрозы по j-му параметру; m - количество параметров оценки;
 - максимальная оценка по j-му параметру;
- максимальная оценка по j-му параметру;
На основе рассмотренных угроз безопасности и практического опыта предлагаются оценки угроз безопасности АИС (общесистемных, программных и других злоупотреблений), которые представлены в таблице 3.
Анализируя оценки общесистемных угроз безопасности АИС, следует отметить, что самыми опасными являются ошибки пользователей. Это обусловлено тем, что их предотвратить достаточно сложно. Наименьшей опасностью характеризуется такая угроза, как перегрузка трафика. Это обусловлено тем, что предотвратить ее достаточно просто, если соответствующим образом организовать мониторинг ресурсов системы и анализировать их использование.
Комплексные оценки угроз распределены в следующих интервалах: до 2.70; от 2.71 до 2.85 и больше 2.85. Все угрозы безопасности и злоупотребления целесообразно разделить на три основные группы:
- неопасные угрозы, которые легко предотвращаются или обнаруживаются, нейтрализуются и устраняются;
- опасные, для которых процессы предотвращения, обнаружения и нейтрализации, с точки зрения технологии, не отработаны;
- очень опасные, которые обладают максимальными оценками по всем параметрам и реализация процессов противостояния сопряжены с огромными затратами.
|
|
|
1.2 Определение затрат на средство защиты
Полная ожидаемая стоимость защиты может быть выражена суммой расходов на защиту и на потерь от ее нарушения. Совершенно очевидно, что оптимальным решением было бы выделение на защиту информации средств в размере Сопт, поскольку при этом обеспечивается минимизация общей стоимости защиты информации.
Для определения уровня затрат, обеспечивающих требуемый уровень защищенности информации, необходимо по крайней мере знать, во-первых, полный перечень угроз информации, во-вторых, потенциальную опасность для информации для каждой из угроз и, в третьих, размеры затрат, необходимых для нейтрализации каждой из угроз.
 (2)
(2)
Поскольку оптимальное решение вопроса о целесообразном уровне затрат на защиту состоит в том, что этот уровень должен быть равен уровню ожидаемых потерь при нарушении защищенности, достаточно определить только уровень потерь. Специалистами фирмы IBM предложена следующая эмпирическая зависимость ожидаемых потерь от i-й угрозы информации:
Где Si — коэффициент, характеризующий возможную частоту возникновения соответствующей угрозы; Vi — коэффициент, характеризующий значение возможного ущерба при ее возникновении. Предложенные специалистами значения коэффициентов:
Таблица2 - Значения коэффициента Si
| Ожидаемая (возможная) частота появления угрозы | Предполагаемое значение Si |
| Почти никогда | |
| 1 раз в 1000 лет | |
| 1 раз в 100 лет | |
| 1 раз в 10 лет | |
| 1 раз в год | |
| 1 раз в месяц (примерно, 10 раз в год) | |
| 12 раза в неделю (примерно 100 раз в год) | |
| 3 раза в день (1000 раз в год) |
Таблица 3 - Возможные значения коэффициента Vi
| Значение возможного ущерба при проявлении угрозы (доллары США) | Предполагаемое значение Vi |
| 1 000 | |
| 10 000 | |
| 100 000 | |
| 1 000 000 | |
| 10 000 000 |
Суммарная стоимость потерь определяется формулой
|
|
|
 |
Задание на выполнение
1. Для рассматриваемой фирмы (см. лабораторную работу №1) провести комплексную оценку угроз:
1.1 На основании таблицы 1 построить таблицу, включающую возможные угрозы (4-5) и показатели (4 - 5)
1.2 Рассчитать комплексные показатели для каждой угрозы по формуле (1). Определить суммарный показатель и рассчитать долю каждой угрозы в процентах. Построить гистограмму (горизонтальная ось – название угроз, вертикальная – доля каждой угрозы в процентах).
2. Рассчитать затраты на ликвидацию конкретной угрозы по формуле 2 и суммарную стоимость потерь. Свести данные в таблицу и построить гистограмму распределения затрат по угрозам.
ЛАБОРАТОРНАЯ РАБОТА №3
МОДЕЛИРОВАНИЕ РАЗГРАНИЧЕНИЯ ДОСТУПА
Цель работы: ознакомиться с моделями разграничения доступа, разработать диаграмму потоков данных системы управления доступом
1. Теоретические сведения
1.1 Модель дискреционного доступа (DAC)
В рамках дискреционной модели контролируется доступ субъектов (пользователей или приложений) к объектам (представляющим собой различные информационные ресурсы: файлы, приложения, устройства вывода и т.д.).
Для каждого объекта существует субъект-владелец, который сам определяет тех, кто имеет доступ к объекту, а также разрешенные операции доступа. Основными операциями доступа являются READ (чтение), WRITE (запись) и EXECUTE (выполнение, имеет смысл только для программ).
Таким образом, в модели дискреционного доступа для каждой пары субъект-объект устанавливается набор разрешенных операций доступа. При запросе доступа к объекту, система ищет субъекта в списке прав доступа объекта и разрешает доступ, если субъект присутствует в списке и разрешенный тип доступа включает требуемый тип. Иначе доступ не предоставляется.
Пусть имеем множество из трёх пользователей {Администратор, Гость, Пользователь_1} и множество из четырёх объектов {Файл_1, Файл_2, CD-RW, Дисковод}. Множество возможных действий включает следующие: {Чтение, Запись, Передача прав другому пользователю}. Действие «Полные права» разрешает выполнение всех трёх действий, действие «Запрет» запрещает выполнение всех перечисленных действий. В данном случае, матрица доступа, описывающая дискреционную политику безопасности, может выглядеть следующим образом.
Таблица 1. Пример матрицы доступа
| Объект / Субъект | Файл_1 | Файл_2 | CD-RW | Дисковод |
| 1. Администратор | Полные права | Полные права | Полные права | Полные права |
| 2. Гость | Запрет | Чтение | Чтение | Запрет |
| 3. Пользователь_1 | Чтение, передача прав | Чтение, запись | Полные права | Запрет |
|
|
|
Например, Пользователь_1 имеет права на чтение и запись в Файл_2. Передавать же свои права другому пользователю он не может.
Пользователь, обладающий правами передачи своих прав доступа к объекту другому пользователю, может сделать это. При этом, пользователь, передающий права, может указать непосредственно, какие из своих прав он передает другому.
Например, если Пользователь_1 передает право доступа к Файлу_1 на чтение пользователю Гость, то у пользователя Гость появляется право чтения из Файла_1.
Недостаток модели DAC заключается в том, что субъект, имеющий право на чтение информации может передать ее другим субъектам, которые этого права не имеют, без уведомления владельца объекта. Таким образом, нет гарантии, что информация не станет доступна субъектам, не имеющим к ней доступа. Кроме того, не во всех АИС каждому объекту можно назначить владельца (во многих случаях данные принадлежат не отдельным субъектам, а всей системе).

Рисунок 1 – Схема дискреционного управления
1.2. Модель мандатного управления доступом
Одна из наиболее известных моделей безопасности — модель Белла-Ла Падулы (модель мандатного управления доступом). Эта модель в основном известна двумя основными правилами безопасности: одно относится к чтению, а другое – к записи данных.
Пусть в системе имеются данные (файлы) двух видов: секретные и несекретные, а пользователи этой системы также относятся к двум категориям: с уровнем допуска к несекретным данным (несекретные) и с уровнем допуска к секретным данным (секретные).
1. Свойство простой безопасности: несекретный пользователь (или процесс, запущенный от его имени) не может читать данные из секретного файла.
2. *-свойство или свойство ограничения: пользователь с уровнем доступа к секретным данным не может записывать данные в несекретный файл. Это правило менее очевидно, но не менее важно.
Действительно, если пользователь с уровнем доступа к секретным данным скопирует эти данные в обычный файл (по ошибке или злому умыслу), они станут доступны любому «несекретному» пользователю. Кроме того, в системе могут быть установлены ограничения на операции с секретными файлами (например, запрет копировать эти файлы на другой компьютер, отправлять их по электронной почте и т.д.). Второе правило безопасности гарантирует, что эти файлы (или даже просто содержащиеся в них данные) никогда не станут несекретными и не «обойдут» эти ограничения. Таким образом, вирус, например, не сможет похитить конфиденциальные данные.
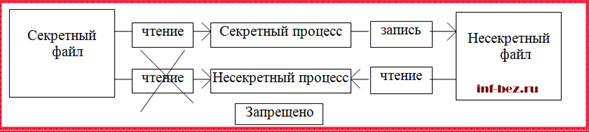
Рисунок 2 – Модель безопасности Белла-Ла Падулы
Общее правило звучит так: пользователи могут читать только документы, уровень секретности которых не превышает их допуска, и не могут создавать документы ниже уровня своего допуска. То есть теоретически пользователи могут создавать документы, прочесть которые они не имеют права.

Рисунок 3 – Схема мандатного доступа
1.3 Диаграммы потоков данных
Диаграммы потоков данных (Data Flow Diagrams – DFD) представляют собой иерархию функциональных процессов, связанных потоками данных.
Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут такой уровень декомпозиции, на котором процессы становятся элементарными и детализировать их далее невозможно
Компоненты диаграммы потоков данных:
1. Внешние сущности – материальный предмет или физическое лицо, представляющее собой источник или приемник информации. Например: заказчики, персонал, поставщики, клиенты, склад
Внешняя сущность обозначается квадратом
 |
Она может быть представлена в самом общем виде на так называемой контекстной диаграмме в виде одной системы как единого целого, либо может быть декомпозирована на ряд подсистем
2. Процесс - преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, – программа, аппаратно реализованное логическое устройство.

Рисунок 4 – Изображение процесса.
Номер процесса служит для его идентификации. Поле имени - наименование процесса в виде предложения с глаголом. Поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс
3. Накопители данных – абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь. Накопитель данных может быть реализован в виде таблицы в оперативной памяти, файла на сменном носителе и т.д

Рисунок 5 – Графическое изображение накопителя
Накопитель данных идентифицируется буквой "D" и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика
4. Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой: – по кабелю между двумя устройствами, – пересылаемыми по почте письмами, дисками, переносимыми с одного компьютера на другой и т.д. на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока Каждый поток данных имеет имя, отражающее его содержание.
Рисунок 6 – Поток данных
Построение иерархии диаграмм потоков данных
Шаг 1: построение контекстных диаграмм. Вначале строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы
Шаг 2: Строится иерархия контекстных диаграм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем
Шаг 3: После построения контекстных диаграмм полученную модель следует
проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами)
Шаг 4: Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Каждый процесс на DFD, в свою очередь, может быть детализирован при помощи: другой DFD либо миниспецификации.
Правила детализации
• правило балансировки: при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников/приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеет информационную связь детализируемая подсистема или процесс на родительской диаграмме
• правило нумерации: при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т.д.
Решение о завершении детализации процесса принимается в случае:
– наличия у процесса небольшого количества входных и выходных потоков данных (2-3 потока);
– возможности описания преобразования данных процессом в виде последовательного алгоритма;
– выполнения процессом единственной логической функции преобразования входной информации в выходную;
– возможности описания логики процесса при помощи миниспецификации небольшого объема (не более 20-30 строк)
Пример. Рассмотрим работу фильмотеки, которая получает запросы от клиентов на фильмы, проверяет членство клиентов, контролирует возврат лент, не допуская выдачу фильмов тем, кто просрочил аренду фильма. За аренду начисляется плата, за просрочку возврата - пени. Информация об аренде лент хранится отдельно от записей о членстве клиентов. Новые фильмы видеотека получает от поставщиков, фиксируя информацию о них. Служащие регулярно готовят отчеты для руководства за определенный период времени о членах видеотеки, поставщиках лент, выдаче фильмов и приобретенных лентах.
1. Контекстная диаграмма, содержащая один процесс (обслуживание фильмотеки), внешние сущности (клиент, поставщик, руководство) и потоки данных.

Рисунок 7 – Контекстная диаграмма
Содержание потоков данных
• Информация от клиента включает данные о клиенте и запрос на фильм;
• Информация для клиента включает ответ на запрос об аренде фильма и членскую карточку.
• Информация от поставщика включает данные о поставщике и о новых фильмах;
• Информация от руководства включает: запросы отчетов о новых членах, о новых поставщиках, о новых фильмах; об аренде фильмов, о составе видеотеки, о поставщиках вообще.
• Информация для руководства включает все эти виды отчетов.
Разбиение на диаграммы 1-го уровня
Можно разбить процесс 0-го уровня "Обслуживание фильмотеки" на 4 процесса, отражающие основные виды деятельности фильмотеки:
– учет клиентов,
– учет поставщиков,
– учет аренды фильмов,
– управление фондом фильмов.

Рисунок 8 - Диаграммы 1-го уровня: учет клиентов фильмотеки
Каждый процесс на диаграмме «Учет клиентов фильмотеки» имеет 2-3 входных и выходных потока данных, поэтому их дальнейшая детализация нецелесообразна.
2. Задание на выполнение работы
Построить диаграммы потоков данных, содержащие не менее 2-х уровней для следующих процессов
1) Пользователь пытается прочитать файл в системе с дискреционным управлением доступа
2) Пользователь пытается прочитать файл в системе с мандатным управлением доступа
Лабораторная работа № 4
|
|
|
