 |


Типы данных в языке Turbo Pascal.
|
|
|
|
Контрольные суммы.
Любой файл на носителе состоит из последовательности байт, с помощью которых этот файл кодируется. Один байт состоит из 8 бит. Байт может принимать значения в диапазоне от 0 до 255 в десятичном представлении. Он принимает такие значения, потому что 8 бит – это 8 ячеек принимающих значения 0 или 1, число комбинаций из всевозможных состояний этих ячеек составляет как раз 256, или 28.
Например, число 810 = 000010002, 25510 = 111111112, 010 = 000000002.
Каждый байт имеет символьную интерпретацию (буква, цифра, знак и т.д.). Байт переводится в символ с помощью некой таблицы символьных преобразований, например, таблицы ASCII. В этой таблице каждому байту соответствует символ, и наоборот – каждому символу сопоставлено десятичное число от 0 до 255.
Любой файл можно прочитать с диска – либо по одному байту последовательно, либо массивами определенной длины. Теперь, зная, что файл представим на диске в виде последовательности чисел, можно сделать «отпечаток» этого файла и сохранить это значение в виде какого-либо числа.
Такой отпечаток называется контрольной суммой файла. Иными словами, контрольная сумма – это число или последовательность чисел. После подсчета контрольной суммы (КС) это значение можно будет где-либо сохранить, и если вдруг содержимое файла изменится (например, что-нибудь будет дописано, стерто или переписано), то новая КС тоже изменится.
КС используют для обнаружения изменений в файле. Иногда очень важна целостность файла и достоверность информации, но порой этот файл могут подменить или исказить данные в нем. Если нам неизвестна КС файла, нам будет и невдомек, что что-то не так. А, зная величину КС, можно быть уверенным, что этот файл был модифицирован.
|
|
|
Простейшим способом подсчета КС файла служит следующий алгоритм:
1) Обнулить переменную контрольной суммы Sum
2) Пока не конец файла
a. Считать очередной байт
b. Прибавить его к контрольной сумме
3) Найти остаток от деления Sum на некое большое целое число.
В результате получим КС – целое число, которое лежит в диапазоне от 0 до N -1 включительно.
Число N должно быть достаточно велико для того, чтобы у двух разных файлов не было одинаковых КС. Если N = 2, то КС примет одно значение из двух: либо 0, либо 1. При N =4, КС примет значение в диапазоне от 0 до 3-х и т.д. То есть получается, что вероятность встретить два разных файла с одной контрольной суммой, равна 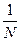 . Чем больше N, тем эта вероятность меньше и метод более надежен. Идеальный случай, когда
. Чем больше N, тем эта вероятность меньше и метод более надежен. Идеальный случай, когда  , но такое число нельзя задать, потому что память – ограниченная величина. Наиболее оптимально использовать N, равным 100 000 или 1 000 000.
, но такое число нельзя задать, потому что память – ограниченная величина. Наиболее оптимально использовать N, равным 100 000 или 1 000 000.
В языке Turbo Pascal относительно целых чисел применимы следующие операции деления:
1) Нахождение целой части от деления (оператор div);
15 div 2 = 7; 36 div 6 = 6
2) Нахождение остатка от деления (оператор mod).
15 mod 2 = 1; 36 mod 6 = 0
Число, которое делят и на которое делят, а также остаток должны являться целыми числами. Речь о целочисленном типе и других типах переменных пойдет далее.
Типы данных в языке Turbo Pascal.
В данном пособии опишем следующие типы данных: целочисленные, вещественные, строковые, символьные, файловые и булевы. Начнем с целочисленного типа. Данный тип служит для представления целых чисел (в том числе и натуральных), и в зависимости от сложности конкретных задач может иметь разные диапазоны значений, а также по-разному представим в памяти компьютера. Рассмотрим таблицу, где представлены целочисленные типы данных.
| Название типа | Число байт в памяти для хранения одной переменной | Диапазон принимаемых значений |
| byte | 0..255 | |
| integer | -32768..32767 | |
| longint | -2147483648..2147483647 |
|
|
|
К вещественным типам относят типы real и double. Данные типы необходимы для представления чисел с плавающей запятой (точкой): например, «0.0004» или «-7,93».
Слова, буквы и символы можно закодировать с помощью строкового типа string и символьного char. Отличие состоит в том, что char кодирует только один символ, а string – совокупность символов (слова и предложения). Переменная типа char в памяти компьютера занимает один байт. Если в текстовом файле находится 150 символов, то размер этого файла будет 150 байт (данные для кодировки ASCII). Пример строки: ’электронная версия’. Размер строки – 18 байт или 18 символов.
Операции со строками.
* Конкатенация (сложение, сцепка).
Только для строкового типа определена конкатенация (сложение) или сцепка строк. Конкатенацией называют такую операцию, при которой к одной строке сбоку приписывается еще одна строка, причем приписывать можно как слева, так и справа. Однако результирующие строки будут различными в случае, когда одна строка приписывается к другой слева или справа. Например, есть две строки S1=’ABCD’ и S2=’XYZ’. Результат будем записывать в строку S3.
S3 = S1 + S2
Результат: ‘ABCDXYZ’
S3 = S2 + S1
Результат: ‘XYZABCD’
Операция конкатенации задается символом ‘+’. Еще один пример. Пусть имеются две строки S1=’500’ и S2=’200’.
S3 = S1+S2 не будет равняться ‘700’. Вместо этого строка S3 примет значение ‘500200’.
* Длина строки - length(<строка>).
Для строк существует функция определения длины строки. Данная функция возвращает целое число – количество символов в строке, а в качестве аргумента выступает строковая переменная. Пример. Пусть S – наша <строка> и S =’12345678’, тогда length(S) будет равно 8. Длина пустой строки, которая обозначается ‘’, равна нулю. Следует отменить, что строки в языке программирования Turbo Pascal заключены в апострофы.
*Обращение к i-тому элементу в строке.
Строка – это массив (совокупность) символов. К любому элементу (символу) строки можно обратиться следующим образом:
c:=S[i], где c – это переменная типа char.
Если нам нужен первый элемент (первая буква) в строке, то можно обратиться к нему так:
S[1]. Если нам нужен последний элемент, то к нему обращаются: S[length(S)]. Например, необходимо в слове ‘Ошипка’ исправить ошибку. Для этого следует:
|
|
|
S:=’Ошипка’;
S[4]:=’б’;
*Операция вставки - insert(<строка_1>, <строка_2>, <позиция>)
Данная процедура вставляет одну строку в другую на определенную позицию.
В строку <строка_2> на позицию <позиция> помещается строка <строка_1>. Пусть S1 - <строка_1>, S2 - <строка_2>. Тогда:
S1:=’FFFF’;
S2:=’123456789’;
Insert(S1, S2, 2)
Результат: ‘1FFFF23456789’.
*Удаление – delete(<строка>, <позиция>, <длина>)
Процедура delete удаляет в строке <строка> фрагмент строки, длиной <длина>, начиная с позиции <позиция>. Пусть есть строка S=’abcdefghijk’. Удалим из нее фрагмент длиной 4 символа, начиная с индекса номер 3.
Delete(S,3,4);
Результат: S=’abghijk‘.
*Копирование строки – copy(<строка>, <позиция>, <длина>)
Copy – функция строкового типа, возвращает результат, полученный от копирования текстового фрагмента длины <длина> в исходной строке с позиции <позиция>. Пусть есть строка S=’abcdefghijk’. Скопируем из нее фрагмент длиной 4 символа, начиная с индекса номер 2.
Copy(S,2,4);
Результат: S=’bcde‘.
*Позиция символа в строке – Pos(<символ>, <строка>).
Функция Pos возвращает индекс (позицию) первого вхождения символа <символ> в строку <строка>. Функция Pos имеет целочисленный тип, в качестве аргументов выступают символ и строка. Если в строке ни разу не встречается данный символ, то значение этой функции равно нулю. Пример: пусть имеется символ c:=’B’ и строка S:=’OCTOBER’.
k:=pos(c, S)
Результат: 5, где k – целое число.
*Чтение и запись строк
Для ввода строки S с экрана используют процедуру Readln(S). Для вывода строки на экран используют процедру Writeln(S). Если имеется строка S и файл F, то чтение и запись строки осуществляется с помощью процедур Readln(F,S) и Writeln(F,S).
Работа с файлами.
Под работой с файлами будем понимать чтение и запись из файла. В данном пособии рассмотрим два режима работы: байтовый (бинарный) и строковый. Первый режим более универсален, здесь файл представляется как совокупность байт и за одну операцию чтения считывается одна единица информации – байт или символ. Во втором режиме файл интерпретируется как совокупность строк, каждая из которых заканчивается символом перевода на другую строку.
|
|
|
*Бинарный (байтовый) режим
В разделе описания переменных var описываем файл и переменную типа byte:
Var
F: file of byte;
b: byte;
…
Для связи файловой переменной F и реального файла на диске используется процедура Assign(<Файл>, <‘Имя Файла’>):
Assign(F, ’input.txt’);
Для открытия файла на чтение используют процедуру Reset(<Файл>). Необходимо, чтобы файл с таким именем существовал на диске, иначе будет ошибка.
Reset(F);
Для открытия файла на запись используют процедуру Rewrite(<Файл>). Наличие файла на диске необязательно, однако, если такой файл существует на диске, то его содержимое обнуляется.
Rewrite(F);
Для того, чтобы считать один байт из файла, применяют процедуру
Read(<Файл>, <Байт>):
Read(F,b);
Для того, чтобы записат ь один байт в файл, применяют процедуру
Write(<Файл>, <Байт>):
Write(F,b);
|
|
|
