 |


Рассмотрим описанные выше инструменты на следующих примерах.
|
|
|
|
Импортируем файл «TestForPPP.txt», находящийся в папке…\Deductor Academic\Samples. Выполним команду «Выделить кнопку Сценарии /щелкнуть левой кнопкой мыши на кнопку мастера импорта  /Выбрать «Текстовый файл с разделителями»/Далее/Используя кнопку … открываем файл TestForPPP.txt/Далее/Далее/Далее/Пуск/Далее. На 6 шаге (настройка предыдущих этапов остается по умолчанию) необходимо определить вид отображения, где наиболее информативным в данном случае будет диаграмма. Установим переключателя «Диаграмма» и нажмем кнопку «Далее». При настройке столбцов (7 шаге) выберем «Синус» и тип диаграммы «Линии», нажмем кнопку «Далее».
/Выбрать «Текстовый файл с разделителями»/Далее/Используя кнопку … открываем файл TestForPPP.txt/Далее/Далее/Далее/Пуск/Далее. На 6 шаге (настройка предыдущих этапов остается по умолчанию) необходимо определить вид отображения, где наиболее информативным в данном случае будет диаграмма. Установим переключателя «Диаграмма» и нажмем кнопку «Далее». При настройке столбцов (7 шаге) выберем «Синус» и тип диаграммы «Линии», нажмем кнопку «Далее».

На последнем шаге необходимо указать название узла в дереве сценариев.

Озаглавим узел и нажмем «Готово». На этом этапе работа мастера импорта закончена, и в дереве сценариев появится новый узел. В рабочей области окна представлена диаграмма столбца «Синус» и соответствующая панель инструментов. Нажмём кнопку  – 3-х мерный вид.
– 3-х мерный вид.

В большинстве случае исходные данные не соответствуют определенным критериям качества и не пригодны для анализа. Предобработка становится нужным шагом для обеспечения удовлетворительного результата анализа.
Очистка данных
С помощью «Парциальной предобработки» можно осуществить восстановление пропущенных данных, редактирование аномальных значений и спектральную обработку (сглаживание) данных.
В нашем случае пример по парциальной предобработке «TestForPPP.txt.txt» содержит столбцы: «Аргумент» – аргумент, «Синус» – имеются пропущенные данные (значение синуса от аргумента), «Синус с выбросами» – синус с выбросами (аномалии), «Синус с большими шумами» – синус с большими шумами, «Синус со средними шумами» – синус со средними шумами, «Синус с малыми шумами» – значение синуса с малыми шумами. Все вышеперечисленные графики можно просмотреть с помощью кнопки  – «Отображать поля» на панели инструментов, выбирая тот или иной столбец. Оставляя график «Синус», выбирая поочередно аномалии, большие шумы, средние шумы, малые шумы просмотрите эти графики. Потом оставляйте только графика «Синус», остальные уберите.
– «Отображать поля» на панели инструментов, выбирая тот или иной столбец. Оставляя график «Синус», выбирая поочередно аномалии, большие шумы, средние шумы, малые шумы просмотрите эти графики. Потом оставляйте только графика «Синус», остальные уберите.
|
|
|
Восстановление пропущенных данных
Если отсутствующие в столбце данные как в нашем случае упорядочены, то в качестве восстановления данных используют аппроксимацию. В случае, когда данные не упорядочены, прибегают к методу максимального правдоподобия, когда вместо пропущенных данных подставляют наиболее вероятные значения, основываясь на всей выборке.
Из диаграммы видно, что необходимо использовать мастер парциальной обработки. Выделяум узел «Текстовый файл (TestForPPP.txt)» и нажимаем на кнопку  – Мастер обработки. На 2 шаге мастера выберем столбец «Синус» и укажем тип предобработки «Аппроксимация».
– Мастер обработки. На 2 шаге мастера выберем столбец «Синус» и укажем тип предобработки «Аппроксимация».

Метод предобработки определен, пропускаем оставшиеся типы обработки и переходим к запуску процесса обработки, нажимая кнопку «Пуск» запускаем процесса обработки.
Нажимаем кнопку «Далее». Указав вид отображения «Диаграмма», нажимаем кнопку «Далее» и выбрав столбец «Синус» и нажимаем кнопок «Далее» и «Готово», мы видим, что пропуски в данных восстановлены.

Удаление аномалий
Аномальные значения не позволяют понять статистическую картину данных и определить характер этих данных, так как содержат значения резко отклоняющиеся от ожидаемых. Для наглядности нажмите на кнопку  – отображать поля, из всплывающего меню выберите «Аномалии». На графике столбца «Синус с выбросами» (аномалии) эти отклонения наглядно видны.
– отображать поля, из всплывающего меню выберите «Аномалии». На графике столбца «Синус с выбросами» (аномалии) эти отклонения наглядно видны.

Применим предобработку «Удаление аномальных значений», в мастере парциальной обработки со степенью подавления - «Большая». Для этого выделим узел «Парциальная предобработка (Восстановление)» и нажмём кнопку  – Мастер обработки. Выполним команду «Выбрать «Парциальная обработка»/Далее/Выделить поле «Синус»/указать для него тип обработки «Аппроксимация»/Далее/Выбрать редактирование аномальных значений – Аномалии, установить переключатель «Редактирование аномальных значений», степень подавления «большая»/Далее/Далее/Пуск/Далее/Выбрать способ отображение данных «Диаграмма» /Далее/Выбрать столбца диаграммы «Аномалии», тип «Линии»/Далее/Готово. Мы видим, что выбросы исчезли, остались небольшие «волнения», которые легко удалить с помощью спектральной обработки.
– Мастер обработки. Выполним команду «Выбрать «Парциальная обработка»/Далее/Выделить поле «Синус»/указать для него тип обработки «Аппроксимация»/Далее/Выбрать редактирование аномальных значений – Аномалии, установить переключатель «Редактирование аномальных значений», степень подавления «большая»/Далее/Далее/Пуск/Далее/Выбрать способ отображение данных «Диаграмма» /Далее/Выбрать столбца диаграммы «Аномалии», тип «Линии»/Далее/Готово. Мы видим, что выбросы исчезли, остались небольшие «волнения», которые легко удалить с помощью спектральной обработки.
|
|
|

Спектральная обработка
Как видим из примера, данные необходимо сгладить. Сглаживание применяется для удаления шумов, способствуя выявлению тенденции, трудно видимой в исходном наборе. Deductor располагает следующими видами спектральной обработки: вычитание шума путем указания степени вычитания шума, сглаживание данных методом указания полосы пропускания и вейвлет преобразование путем указания глубины разложения и порядка вейвлета.
Вейвлет-преобразование (англ. Wavelet transform) — интегральное преобразование, которое представляет собой свертку вейвлет-функции с сигналом.
Cпособ преобразования функции (или сигнала) в форму, которая или делает некоторые величины исходного сигнала более поддающимися изучению или позволяет сжать исходный набор данных. Вейвлетное преобразование сигналов является обобщением спектрального анализа. Термин (англ. wavelet) в переводе с английского означает «маленькая волна», или «волны, идущие друг за другом». Вейвлеты – это обобщенное название математических функций определенной формы, которые локальны во времени и по частоте («маленькие»), и в которых все функции получаются из одной базовой, изменяя её (сдвигая, растягивая по оси времени (так что они «идут друг за другом»)).
Воспользуемся методом «Вейвлет преобразование» с параметрами по умолчанию (глубина разложения 3, порядок вейвлета 6).
Для этого выделим узел «Парциальная предобработка (Восстановление, Аномалии)» и нажмём кнопку  – Мастер обработки. Выполним шаги, использованных в предыдущем пункте «Удаление аномалий»: «Выбрать «Парциальная обработка»/Далее/Выделить поле «Синус»/указать для него тип обработки «Аппроксимация»/Далее/Выбрать редактирование аномальных значений – Аномалии, установить переключатель «Редактирование аномальных значений», степень подавления «большая»/Далее/Установить способ спектральной обработки для «Аномалии» «Вейлет преобразование», глубина разложения 3, порядок вейвлета 6/Далее/Пуск/Далее/Выбрать способ отображение данных «Диаграмма» /Далее/Выбрать метку столбца диаграммы «Аномалии», тип «Линии»/Далее/Готово.
– Мастер обработки. Выполним шаги, использованных в предыдущем пункте «Удаление аномалий»: «Выбрать «Парциальная обработка»/Далее/Выделить поле «Синус»/указать для него тип обработки «Аппроксимация»/Далее/Выбрать редактирование аномальных значений – Аномалии, установить переключатель «Редактирование аномальных значений», степень подавления «большая»/Далее/Установить способ спектральной обработки для «Аномалии» «Вейлет преобразование», глубина разложения 3, порядок вейвлета 6/Далее/Пуск/Далее/Выбрать способ отображение данных «Диаграмма» /Далее/Выбрать метку столбца диаграммы «Аномалии», тип «Линии»/Далее/Готово.
|
|
|

После соответствующей обработки, результат рассмотрим на визуализаторе «Диаграмма». Выбрав для сравнения график столбеца «Синус», используя кнопки  – отображать поля, видим, что шумы были удалены. Оба графика имеют очень близкие значения в соответствующих аргументах.
– отображать поля, видим, что шумы были удалены. Оба графика имеют очень близкие значения в соответствующих аргументах.

Удаление шумов
Из-за присутствующих шумов в значениях общая тенденция поведения данных не видна, а при построении модели теряются важные обобщающие качества.
В примере, который у нас имеется, находятся столбцы: «Большие шумы», «Средние шумы» и «Малые шумы». Применим к данным столбцам в спектральной обработке метод «Вычитание шума» и укажем степень подавления – «Большая», «Средняя» и «Малая» соответственно.
Для этого выделим узел «Парциальная предобработка (Восстановление, Аномалии, Фильтрация (Вейвлет))» и нажмём кнопку – Мастер обработки. Выполним 4-х шагов, использованных в предыдущем пункте «Спектральная обработка»: «Выбрать «Парциальная обработка»/Далее/Выделить поле «Синус»/указать для него тип обработки «Аппроксимация»/Далее/Выбрать редактирование аномальных значений – Аномалии, установить переключатель «Редактирование аномальных значений», степень подавления «большая»/Далее/Установить способ спектральной обработки для «Аномалии» «Вейлет преобразование», глубина разложения 3, порядок вейвлета 6. Кроме того на 4-м шаге для способа спектральной обработки «Большие шумы» установим переключатель «Вычитание шума», степень вычитания шума – Большая; для «Средние шумы» установим переключатель «Вычитание шума», степень вычитания шума – Средняя; для «Малые шумы» установим переключатель «Вычитание шума», степень вычитания шума – Малая.
|
|
|

Выполнить команду «Далее/Пуск/Далее/Выбрать способ отображение данных «Диаграмма»/ Далее/Выбрать метки столбцов диаграммы «Большие шумы», «Средние шумы», «Малые шумы», тип «Линии».

Выполнить команду «Далее/Готово».
После обработке на диаграмме можно просмотреть результат.

В некоторых случаях неплохие результаты удаление шумов дает вейвлет преобразование.В мастере парциальной предобработки выберем поля «Большие шумы», «Средние шумы» и «Малые шумы», указав метод обработки «Вейвлет преобразование», параметры обработки остаются по умолчанию.
Для этого выделим узел «Парциальная предобработка (Восстановление, Аномалии, Фильтрация (Шумы))» и нажмём кнопку  – Мастер обработки.
– Мастер обработки.
Выполним 4-х шагов, использованных в предыдущем пункте «Спектральная обработка»: «Выбрать «Парциальная обработка»/Далее/Выделить поле «Синус»/указать для него тип обработки «Аппроксимация»/Далее/Выбрать редактирование аномальных значений – Аномалии, установить переключатель «Редактирование аномальных значений», степень подавления «большая»/Далее/Установить способ спектральной обработки для «Аномалии» «Вейлет преобразование», глубина разложения 3, порядок вейвлета 6. Кроме того, для способов спектральной обработки «Большие шумы», «Средние шумы», «Малые шумы» поочередно установим переключатель «Вейлет преобразование», глубина разложения 3, порядок вейвлета 6.

Выполним команду Далее/Пуск/Далее/Выбрать способ отображение данных «Диаграмма» /Далее/Выбрать меток столбцов диаграммы «Большие шумы», «Средние шумы», «Малые шумы», тип «Линии»/Далее/Готово.

Результат сглаживания данных можно просмотреть на диаграмме.

Видим, что красный график – сглаженные большие шумы, желтый – сглаженные средние шумы и синий – сглаженные малые шумы.
Факторный анализ
Цель факторного анализа заключается в понижении размерности пространства факторов. Понижение размерности необходимо в случаях, когда входные факторы коррелированы друг с другом, т.е. взаимозависимы. В факторном анализе речь идет о выделении из множества измеряемых характеристик объекта новых факторов, более адекватно отражающих свойства объекта.
Факторный анализ - метод многомерного статистического анализа, позволяющий на основе экспериментального наблюдения признаков объекта выделить группу переменных, определяющих корреляционную взаимосвязь между признаками. Например, при проведении элементного анализа предельных углеводородов можно отдельно измерять массовую долю углерода и массовую долю водорода - два признака. Однако, эти признаки не являются независимыми (коррелируют между собой) и оба определяются длиной углеродной цепи. В этом и состоит суть факторного анализа - на основе исследования корреляционных взаимосвязей признаков находить причины, определяющие эти взаимосвязи.
|
|
|
Поле может быть использовано в факторном анализе, если выполнено несколько условий:
- оно имеет числовой тип данных;
- в нем не содержатся пропуски;
- стандартное отклонение столбца не равно нулю, то есть в столбце содержатся различные значения.
В противном случае, поле будет автоматически помечено как непригодное. Для понижения размерности пространства факторов необходимо наличие хотя бы двух входных полей.
Процесс заключается в отбрасывании некоторых факторов, которые в меньшей степени объясняют дисперсию результирующих факторов, а оставшиеся факторы в достаточной мере определяют дисперсию результирующих факторов.
Устранение незначащих факторов необходимо, когда входные факторы наименьшим образом коррелированы с выходным фактором и могут быть исключены из результирующего набора данных практически без потери полезной информации. Обязательно наличие хотя бы двух входных полей и одного выходного.
В обоих случаях, если степень корреляция между факторами меньше порога значимости, устанавливаемым аналитиком при работе с тем или иным алгоритмом, то такие факторы могут быть удалены из исходной выборки как незначащие.
Импортируем данные из файла «TestForCPP.txt» для обработки. Данный файл содержит столбцы: «Аргумент», «Фактор1», «Фактор2», «Фактор3», «Результат1» и «Результат2» – импортируем с параметрами по умолчанию.
Для этого выполним команду «Выделить узел «Текстовый файл (TestForPPP.txt)»/Щелкнуть левой кнопкой мыши на кнопку мастера импорта /Выбрать «Текстовый файл с разделителями»/Далее/Используя кнопку … открывать файл TestForCPP.txt/Далее/Далее. На 3-м шаге установим назначений: «Аргумент» – неиспользуемое, «Фактор1», «Фактор2», «Фактор3» – входные факторы (можно их выделить и сразу для всех назначить – входные факторы), «Результат1» и «Результат2» – выходные факторы. Выполним команду «Далее/ Пуск/ Далее/ Определите вид отображения – Диаграмма/Нажмите кнопку «Далее»/Выберите метки столбцов «Фактор1» – зельёный, «Фактор2» – синий, «Фактор3» – оранжевый, тип «Линии»/Далее/Готово. Получим:

Построим также диаграмм для результатов. Для этого выделим узел «Текстовый файл (TestForCPP.txt-Факторы)» и выполним предыдущую команду для построения диграмму для факторов, лишь с разницей тем, что вместо выбора меток столбцов выбираем метки результатов «Результат1» – цвет лимона и «Результат2» – бледно-синий. Получим:

Понижение размерности и устранение незначащих факторов
Выделим узел «Текстовый файл (TestForCPP.txt)» и нажмем кнопку – Мастер обработки. В мастере обработки выберём «Факторный анализ» и нажмем кнопку «Далее».
Установим назначений: «Аргумент» – неиспользуемое, «Фактор1», «Фактор2», «Фактор3» – входные факторы, «Результат1» и «Результат2» – неиспользуемое.

Выполним команду «Далее/ Пуск/ Далее».
На 4 шаге мастер предлагает установить настройки для «Устранения незначащих факторов», где нас все устраивает (порог значимости 90%).

Выполним команду «Далее/Выбрать способ отображение данных «Диаграмма» /Далее/Выбрать меток столбцов диаграммы «Фактор1», «Фактор2», тип «Линии»/Далее/Готово.
Получим:

Диаграмма позволяет нам оценить результаты мастера.


| а) исходные входные факторы | б) полученные входные факторы |
После обработки вместо трех входных факторов осталось два входных фактора «Фактор1» – красный и «Фактор2» – зельёный, что является результатом понижения размерности. На диаграмме видно, что фактор «Фактор2» близок к полю «Фактор3», соответственно, «Фактор1» – это преобразованные факторы «Фактор1» и «Фактор2».
Трансформация данных
При анализе часто возникает необходимость просмотреть данные не по всей совокупности, а по определенным группам (какую сумму берут на определенные цели, сумму кредита того или иного возраста).
Рассмотрим разбиение данных на группы с помощью инструмента обработки «Настройка набора данных» на примере данных по рискам кредитования физических лиц (файл Credit.txt).
Для этого выполним команду «Выделить узел «Текстовый файл (TestForCPP.txt-Результаты)»/Щелкнуть левой кнопкой мыши на кнопку мастера импорта /Выбрать «Текстовый файл с разделителями»/Далее/Используя кнопку … открываем файл Credit.txt.
Выполним команду «Далее/Далее/Далее/Пуск/Далее». После импорта данных из текстового файла в качестве способа отображения данных выберём «Куб». Нажмём кнопку «Далее».
В качестве назначений для столбцов «Возраст» и «Цель кредитования» установим «Измерение», а для столбца «Сумма Кредита» – «Факт». Остальные столбцы установим как «Неиспользуемые». Для этого оптимально сначало выделить все столбцы и установить назначений для них «Неиспользуемые», а потом установить эти назначении для столбцов «Возраст», «Цель кредитования» и «Сумма Кредита».

Нажмём кнопку «Далее». При настройке 8 шага куба установим «Цель кредитования» как измерение в строках, а измерение «Возраст» в столбцах. Нажмём кнопку «Далее».
На 9 шаге укажем в качестве факта «Сумма кредита» - ∑ Сумма, а в качестве вариантов отображения установим – значение.

Выполним команду «Далее/Готово». В результате мы получим кросс-таблицу с интересующими нас данными.

ü Разбиение даты (по неделям)
Разбиение временного ряда на определенные периоды дает возможность всестороннего анализа информации. Исходя из такой возможности, мы, например, можем определить активный (неактивный) временной интервал.
Допустим, необходимо получить данные о суммах взятых кредитов по неделям (файл Credit.txt). Выделим узел «Текстовый файл (Credit.txt-Кросс-таблица)» и нажмем кнопку – Мастер обработки. В окне «Мастер обработки» выберём пункт предобработки «Дата и время» и нажмем кнопку «Далее». На втором шаге «Назначение» для поля «Дата кредитования» установим «Используемое», а все остальные поля определим как «Непригодное». Для поля «Дата кредитования» в столбце «Строка» установим галочку напротив строки «Год + Неделя».

Нажмём кнопку «Далее». Выберем в качестве визуализатора «Таблицу» и «Куб». Нажмём кнопку «Далее». При настройке назначения полей куба в качестве измерений выберем «Дата кредитования (Год + Неделя)» и столбец «Цель кредитования». В качестве факта выберем «Сумма кредита», а остальные поля установим «Неиспользуемые».

На следующем шаге перенесем «Цель кредитования» в область строк, а «Дата кредитования (Год + Неделя)» в область колонок.
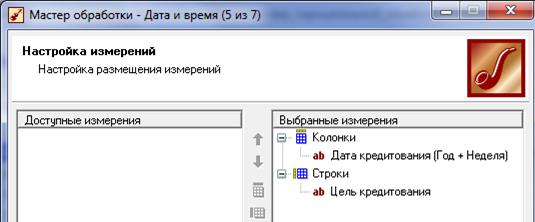
На 6 шаге установим в качестве факта «Сумма кредита», а в качестве вариантов отображения– «Значение».

Выполним команду «Далее/Готово». В результате мы получим кросс-таблицу о суммах кредитов, взятых по неделям в разрезе целей кредитования.

Квантование
Квантование предназначено для преобразования непрерывных данных в дискретные. Данные разбиваются по интервалам (одинаковой длины) или по квантилям (данные разбиваются на интервалы так, чтобы в каждом интервале находилось одинаковое количество данных. k-квантилями (k-th quantils) множества из n чисел называют k-1 его элементов, обладающих следующим свойством: если расположить элементы множества в порядке возрастания, то квантили будут разбивать множество на k равных (точнее, отличающихся не более чем на один элемент) частей. Более точно можно определить k-квантили как порядковые статистики с номерами [n/k], [2n/k], …, [(k-1)n/k].
Используем предыдущий файл (Credit.txt) для разбиения данных о возрасте кредиторов на 5 интервалов (до 30 лет, от 30 до 40, от 40 до 50, от 50 до 60, свыше 60лет). Данные необходимо разбиты на пять интервалов, поскольку по статистике минимальный возраст кредиторов составляет 19 лет, а максимальный 69 лет. Данное разбиение позволит определить наиболее активный возрастной период кредитования и в последующем принять соответствующие меры стимулирования или ужесточения условий кредитования в тех или иных возрастных группах. Просмотрим данные в разрезе по неделям, поэтому продолжим работу с последним узлом.
В мастере квантования выберем назначение поля «Возраст» используемым (для поля «Срок кредита» назначение - информационное), укажем способ разбиения «По интервалам» и количество интервалов 5, в качестве значения выберем «Метку интервала».
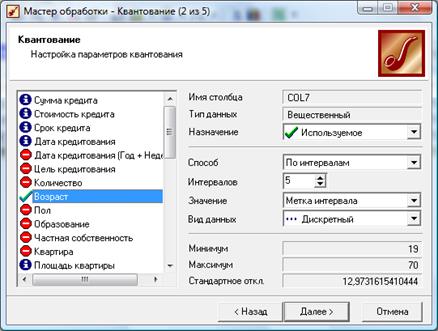
На следующем шаге мастера установим метки по тем размерам, которые были определены выше.

Выберем в качестве визуализатора «Куб» и укажем поле «Сумма кредита» в качестве факта, «Возраст» и «Дата кредитования (Год + Неделя)» в качестве измерений.
Далее перенесем «Возраст» и «Дата кредитования (Год + Неделя)» из доступных измерений в выбранные: «Возраст» - колонки; «Дата кредитования (Год + Неделя)» - строки.
На кросс-таблице отображена информация о том, какие суммы берут кредиторы тех или иных возрастных категорий в разрезе по неделям.

Исходя из данной кросс-таблицы, аналитик делает выводы, что нужно снизить стоимость кредита в возрастной группе старше 50 лет либо применить какие-нибудь другие меры по стимулированию этой группы.
Группировка данных
Собранный в процессе статистического наблюдения материал нуждается в определенной обработке для принятия решения. Необходима сводная информация по различным разрезам. В Deductor имеется соответствующий инструмент, позволяющий осуществлять сбор сводной информации – «Группировка». Данный инструмент дает возможность объединить записи по полям – измерениям и агрегировать данные в полях – фактах для дальнейшего анализа.
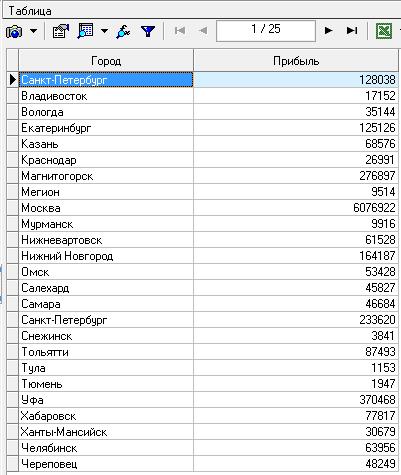
Предположим, аналитик располагает информацией о статистике банков России за определенный период. Необходимо выявить города, в которых прибыль банков самая большая. Для этого нужно определить суммарную прибыль всех банков в каждом городе, используя инструмент группировку.
Данные для обработки содержатся в файле «Banks.txt». После импорта данных из текстового файла просмотрим информацию в виде таблицы.
Выделив импортированный файл, запустим мастер обработки и выберем в качестве инструмента «Группировка». На втором шаге мастера определим в качестве измерения «Город», фактом укажем измерение «Прибыль», а все остальные поля определим как неиспользуемые. По полю «Прибыль» в качестве функции агрегации укажем «Сумму».

Для просмотра результата мастера обработки воспользуемся таблицей. После обработки получим необходимые данные по прибыли всех банков в каждом городе, которые можно использовать в дальнейшей работе аналитика.
|
|
|
