 |


Глава 4 возможности и ограничения применения информационных технологий в исследовании влияния СМИ
|
|
|
|
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ВЫПУСКНАЯ РАБОТА ПО
«Основам информационных технологий»
Магистрантки ФФСН
кафедры социологии
Артёменко Елены Константиновны
Руководители:
Кандидат социологических наук, зав. каф. Социальной коммуникации Терещенко
Ольга Викентовна
Ассистент: Шешко Сергей
Михайлович
Минск – 2008
ОГЛАВЛЕНИЕ
ОГЛАВЛЕНИЕ. 2
СПИСОК ОБОЗНАЧЕНИЙ КО ВСЕЙ ВЫПУСКНОЙ РАБОТЕ. 3
РЕФЕРАТ ПО ИНФОРМАЦИОННЫМ ТЕХНОЛОГИЯМ В ПРЕДМЕТНОЙ ОБЛАСТИ.. 4
ИНТЕРНЕТ РЕСУРСЫ В ПРЕДМЕТНОЙ ОБЛАСТИ ИССЛЕДОВАНИЯ.. 29
ДЕЙСТВУЮЩИЙ ЛИЧНЫЙ САЙТ. 30
ГРАФ НАУЧНЫХ ИНТЕРЕСОВ.. 31
ПРЕЗЕНТАЦИЯ МАГИСТЕРСКОЙ ДИССЕРТАЦИИ.. 32
СПИСОК ЛИТЕРАТУРЫ К ВЫПУСКНОЙ РАБОТЕ. 33
ПРИЛОЖЕНИЕ. 34
СПИСОК ОБОЗНАЧЕНИЙ КО ВСЕЙ ВЫПУСКНОЙ РАБОТЕ
1. ИТ – Информационные технологии;
2. ПО – Программное обеспечение;
3. СМИ – Средства массовой информации;
4. SPSS – Statistical Package for the Social Science.
РЕФЕРАТ ПО ИНФОРМАЦИОННЫМ ТЕХНОЛОГИЯМ В ПРЕДМЕТНОЙ ОБЛАСТИ
«Проблемные вопросы использования ИТ в изучении влияния средств массовой информации»
ОГЛАВЛЕНИЕ РЕФЕРАТА
ОГЛАВЛЕНИЕ РЕФЕРАТА.. 3
ВВЕДЕНИЕ. 4
ГЛАВА 1 ОБЗОР ЛИТЕРАТУРЫ.. 6
ГЛАВА 2 ПРОБЛЕМНЫЕ ВОПРОСЫ ИСПОЛЬЗОВАНИЕ ПАКЕТА SPSS ДЛЯ ИЗУЧЕНИЯ ВЛИЯНИЯ СМИ.. 8
ГЛАВА 3 ПРОБЛЕМНЫЕ ВОПРОСЫ ИСПОЛЬЗОВАНИЯ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ В ИЗУЧЕНИИ АУДИТОРИИ СМИ.. 17
ГЛАВА 4 ВОЗМОЖНОСТИ И ОГРАНИЧЕНИЯ ПРИМЕНЕНИЯ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ В ИССЛЕДОВАНИИ ВЛИЯНИЯ СМИ 23
ЗАКЛЮЧЕНИЕ. 25
СПИСОК ЛИТЕРАТУРЫ К РЕФЕРАТУ.. 26
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ К РЕФЕРАТУ.. 27
ВВЕДЕНИЕ
Трудно переоценить роль средств массовой информации в современном обществе. СМИ называют «четвёртой властью», говоря о подотчётности им демократических институтов. Они выполняют информационную, развлекательную, воспитательную, солидаризирующую функции. Средства массовой информации выступают инструментом маркетинговых и политических коммуникаций, являются источником формирования общественного мнения и средством социализации. Среди важнейших функций средств массовой информации П. Лазарсфельд и Р. Мертон называют присвоение статуса (оценка групп, индивидов и явлений общественной жизни зависит от характера их освещения в СМИ), укрепление социальных норм. Однако эти исследователи, вместе с многими, отмечают и негативную сторону воздействия на общество средств массовой коммуникации: это и «наркотизирующая дисфункция» (при которой потребление средств массовой информации замещает другие виды активности, усыпляет людей), социальный конформизм, унификация вкусов. Эти неоднозначные эффекты делают влияние СМИ объектом беспрестанного интереса исследователей социологов, психологов, культурологов, экономистов и, конечно, специалистов в области информации и коммуникации.
|
|
|
Влияние СМИ – это многомерное явление. Для его изучения, для изучения эффектов массовой коммуникации необходимо совмещать данные о содержании сообщения и данные об изменении знаний, представлений, убеждений и поведения как отдельных людей, так и социальных групп. При изучении влияния исследователям необходимо устанавливать причинно-следственную связь между потреблением продукта массовой коммуникации и предполагаемым результатом этого потребления. Однако этот процесс обусловлен столькими факторами и так сложен для объяснения, что до сих пор у исследователей нет единого мнения насчёт силы и характера влияния СМИ.
Роль информационных технологий в изучении влияния СМИ очень высока. Во-первых, для психологических, социологических, культурологических исследований разрабатывается большое количество средств программного обеспечения для обработки результатов анализа, в том числе средства статистической обработки данных о потреблении СМИ и изменениях, связанных с этим потреблением. А во-вторых, в современных условиях функционирования СМИ разрабатывается большое количество инструментов изучения аудитории СМИ и различных её характеристик, которые являются очень важными факторами влияния СМИ на личность и общество.
|
|
|
Цель данной работы заключается в том, чтобы проанализировать основные проблемы использования информационных технологий в исследовании влияния СМИ. Для её достижения необходимо решить следующие задачи: рассмотреть инструменты изучения причинно-следственных связей между продуктом медиа и его влиянием на аудитории, а также, рассмотреть основные аспекты изучения аудитории как важнейшего фактора влияния СМИ, и также проблемы использования информационных технологий в данных исследованиях.
Всё это делает информационные технологии необходимым и очень важным элементом изучения влияния СМИ.
ГЛАВА 1 ОБЗОР ЛИТЕРАТУРЫ
Влияние средств массовой коммуникации является многомерным и разносторонним явлением. Для того, чтобы изучать проблемы применения информационных технологий в исследованиях влияния СМИ, необходимо понять суть процессов, связанных с медиа-воздействием и медиа-влиянием. Для этого в данной работе рассматривается учебник авторов из университета штата Алабама Дж. Брайанта и С. Томпсон «Основы воздействия СМИ». В нём не только излагается понимание феномена медиавоздействия, но и рассматриваются основные научные школы изучения СМИ, а также приводятся примеры интересных исследований в этой сфере.
Кроме того, для изучения проблемных вопросов использования в исследованиях информационных технологий, необходимо было иметь представление и дать описание основных методов исследования средств массовой коммуникации, что подробно делается в учебнике Т.В. Науменко «Социология массовой коммуникации». В нём рассматриваются различные аспекты функционирования массовой коммуникации, в том числе сущность массовой коммуникации, субъекты массовой коммуникативной деятельности, проблемы массовой коммуникации и свободы слова, законодательная защита общества от информационного воздействия, и, наконец, направления и методы исследования системы массовой коммуникации.
|
|
|
Для изучения влияния необходимо обратить внимания на возможности применения статистических пакетов в социальных науках. Поэтому при описании возможностей анализа данных средствами SPSS использовалось учебное пособие заведующей кафедры социальной коммуникации ФФСН БГУ О.В.Терещенко «Первые шаги в SPSS для Windows», которое содержит подробное описание работы с прикладным статистическим пакетом – одним из самых распространённых средств статистической обработки и анализа данных социальных исследований. Кроме того, для описания особенности статистической обработки данных были использованы материалы энциклопедии «Социология», статьи «Линейная парная регрессия» и «Факторный анализ», в которых рассматривается суть методов, часто используемых при изучении воздействия СМИ. Также в работе использовались материалы учебного пособия исследователей Г.Д. Ковалевой и П.С. Ростовцева «Анализ социологических данных с применением статистического пакета SPSS: Учебно-методическое пособие».
Кроме того, для рассмотрения программных средств для изучения аудиторий, было использовано издание «PaloMARSv2.0.Руководство пользователя», в котором описываются основные возможности программы по формированию отчётов о телесмотрении и описанию аудиторий.
Для описания разрабатываемого в настоящее время комплексного продукта МедиаКлиент-Медиасервер, анализирующего данные пиплметрии, использовались материалы, предоставленные на официальном сайте независимой исследовательской компании ГЕВС.
ГЛАВА 2 ПРОБЛЕМНЫЕ ВОПРОСЫ ИСПОЛЬЗОВАНИЕ ПАКЕТА SPSS ДЛЯ ИЗУЧЕНИЯ ВЛИЯНИЯ СМИ
Влияние СМИ выражается в причинно-следственной связи между содержанием и распространением продукта средств массовой информации и действием на аудиторию (изменением знаний, ценностей и поведения). Традиционно для определения причинно-следственной связи необходимо соблюдения трёх условий: должна иметься корреляция между двумя переменными, причина должна предшествовать следствию во времени, не должно быть общих факторов, определяющих обе переменные. Например, в исследовании «Проект культурных индикаторов» американский социологи Джордж Гребнер анализировал корреляцию между частотой просмотра телевизора и приближением картины мира опрашиваемых к реальности, транслируемой медиа. «Исследования показали, что, по сравнению с прочими категориями людей, у тех зрителей, которые много смотрят телевизор, формируется столь же искаженный образ мира, как тот, который они видят на телеэкране (рис. 6.1.). Используя уже упомянутый пример процентной доли пожилых людей и уровня преступности, можно сказать, что телезрители склонны недооценивать процент людей пожилого возраста в США и значительно переоценивать уровень преступности».[1, c.121]
|
|
|
Однако, в такой ситуации полное сосредоточение на применении информационных технологий в исследовании оказывается проблемным. Если с помощью специального программного обеспечения можно определить степень корреляции и её статистическую значимость, то определение двух других условий требует самостоятельного анализа от исследователя.
Наиболее полным и часто используемым программным пакетом для статистической обработки данных социальных исследований является пакет SPSS. Норман Най, Хедли Халл и Дейл Бент разработали первую версию системы в 60-х годах, далее этот пакет развивался Чикагским университетом. Первая версия пакета под Microsoft Windows вышла в1992 году. На данный момент существуют версии под MacOs X и Linux.
В пакете SPSS предусмотрена обработка как количественных, так и качественных статистических переменных. «Существуют три основных типа данных, которые принято упорядочивать по возрастанию уровня измерения: номинальный, порядковый, количественный. Выбор методов статистического анализа может оказаться ограниченным, если данные имеют низкий уровень измерения. Поэтому прежде, чем Вы начнёте их собирать, важно определить, какие данные потребуются для определения того или иного метода».[5, c.12] От того, к какому типу относится переменная и какое явление она отражает, зависят возможные операции анализа, которые к ним применяются. В диалоговом окне базы описания переменных можно задать один из типов: Numeric, Comma, Dot, Scientific notation, Date, Dollar, Custom currency, String.
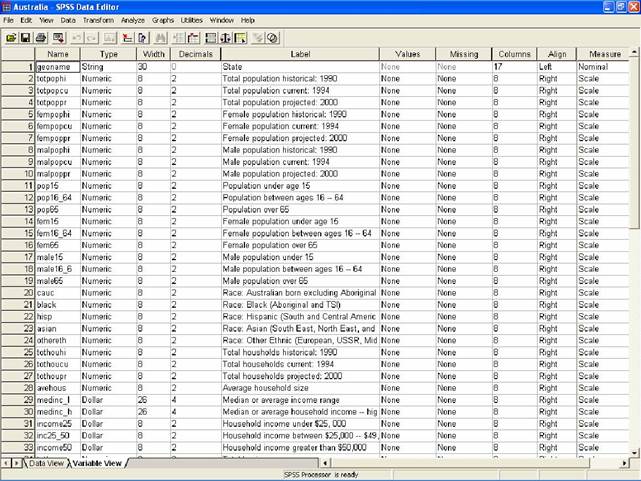
Рисунок 2.1 – Редактор переменных пакета SPSS
Чаще всего, те переменные, которые описывают содержание знаний, представлений, поведения можно описать только с помощью переменной типа String, для которой очень ограничен набор производимых операций. Ей соответствует номинальная шкала, переменные которой не могут быть подвержены большинству видов статистического анализа из-за того, что не соответствуют числовым значениям. Для того, чтобы расширить возможности анализа данных, переменные часто сводятся к порядковой шкале (и на вопрос о частоте просмотра той или иной телепередачи можно давать ответы: «редко»; «скорее редко, чем часто»; «скорее часто, чем редко»; «часто» – которые могут быть закодированы числами от 1 до 4, после чего могут быть подвергнуты количественному анализу). Другой способ обработки данных подобного рода – приведение номинальной переменной к бинарной шкале (где варианты ответов на вопрос «Смотрели ли Вы ту или иную передачу вчера?» - а он часто используется в исследовании телесмотрения методом day-after-call – могут звучать однозначно «да» или «нет», и их можно закодировать числами 0 и 1).
|
|
|
Кроме обозначения типа переменной при вводе её в базу SPSS используются такие параметры, как Name, Width, Decimals – обозначающие общее количество знаков и количество знаков после запятой, Lable, Values – содержащий описание переменной, Missing – задающий способ обработки пропусков данных, Columns, Align – задающие вид и Measure – обозначающий тип шкалы.
Среди методов сравнения и сопоставления различных переменных, применяемых программой, стоит выделить таблицы сопряжённости, регрессионный анализ и факторный анализ. При этом используется анализ коррелиций между различными переменными, вычисляются подходящие в данном случае коэффициенты корреляции, а также проверяются гипотезы о связи. Подробнее все эти методы будут рассмотрены ниже. Однако стоит отметить, что для переменных различных типов и для различных шкал существуют ограничения в применении этих методов сравнения. Проблема состоит в том, что для номинальных переменных среди всех методов обработки данных в плане установления зависимостей между ними доступен только метод анализа таблиц сопряжённости, а все остальные методы, позволяющие черпать более подробную информацию о характерах связи, могут применятся только к количественным переменным.
Таблицы сопряжённости предоставляют структурированную информацию, дающую наглядное представление о связи между переменными. «Существует несколько способов измерения статистических связей между переменными. Наиболее универсальным из них является анализ таблиц сопряжённости». [5, c.60] Таблицы сопряжённости формируются на основании массивов данных с помощью команды Descriptive statistic -> Crosstabs меню Analyze.
«Crosstabs получает таблицы сопряженности многомерных распределений и связей двух и более переменных. Рекомендуется использовать CROSSTABS для переменных с небольшим числом значений (обычно для неколичественных переменных), так как каждая комбинация значений соответствует новой клетке в таблице.
Таблицы сопряженности для пары переменных X и Y содержат частоты Nij, с которыми встретилось сочетание i -го значения X и j -го значения Y. Кроме того, в таблице обязательно присутствуют маргинальные частоты Ni. - равные сумме чисел Nij по строке; N.j - сумме по столбцу (частоты i -го значения X и j -го значения Y, подсчитанные независимо) и N - общее число объектов.
Таблица, заполненная одними частотами Nij, обычно не имеет смысла, так как не проясняет должным образом взаимосвязи между переменными. Для исследования взаимосвязи необходимы статистики взаимосвязи переменных и статистики связи значений». [2, c.35]
В качестве примера исследования с помощью анализа таблиц сопряжённости можно привести исследование зависимости доверия к СМИ разной формы собственности и ценности уверенности для молодых людей. Анализ производится на основании данных исследования «Молодёжь Беларуси, какие мы?». Количество опрошенных девушек – 506 человек. Среди них студентки БГУ, БГУИР, БНТУ, ИСЗ и БУК.
|
| Государственным газетам и журнвлам | Total | ||
|
| 0 | 1 | ||
| Быть уверенным в себе | 0 | 2 | 0 | 2 |
| 1 | 7 | 1 | 8 | |
| 2 | 4 | 3 | 7 | |
| 3 | 29 | 4 | 33 | |
| 4 | 86 | 33 | 119 | |
| 5 | 381 | 103 | 484 | |
| Total | 509 | 144 | 653 | |
Таблица 2.1 – Таблица сопряжённости между переменными «ценность уверенности» и «доверие к государственным газетам и журналам».
|
| Value | Approx. Sig. | |
| Nominal by Nominal | Phi | ,104 | ,217 |
| Cramer's V | ,104 | ,217 | |
| N of Valid Cases | 653 | ||
Таблица 2.2 – Проверка статистической значимости связи между переменными «ценность уверенности» и «доверие к государственным газетам и журналам».
|
| негосуд. газеты и журналы | Total | ||
|
| 0 | 1 | ||
| быть уверенным в себе | 0 | 2 | 0 | 2 |
| 1 | 5 | 3 | 8 | |
| 2 | 3 | 4 | 7 | |
| 3 | 18 | 13 | 31 | |
| 4 | 69 | 48 | 117 | |
| 5 | 257 | 212 | 469 | |
| Total | 354 | 280 | 634 | |
Таблица 2.3 – Таблица сопряжённости между переменными «ценность уверенности» и «доверие к негосударственным газетам и журналам».
|
| Value | Approx. Sig. | |
| Nominal by Nominal | Phi | ,068 | ,709 |
| Cramer's V | ,068 | ,709 | |
| N of Valid Cases | 634 | ||
Таблица 2.4 – Проверка статистической значимости связи между переменными «ценность уверенности» и «доверие к негосударственным газетам и журналам».
Так, таблицы 2.1 и 2.3 показывают, какова частота совместного появления различных оценок важности ценности уверенности в себе и доверия государственным или негосударственным газетам и журналам, а таблицы 2.2 и 2.4 демонстрируют значения коэффициентов корреляции и предоставляют значения Approx. Sig., которое можно сравнить с задаваемым исследователем уровнем ошибки первого рода α и подтвердить или не подтвердить гипотезу о связи между двумя переменными. Если Approx. Sig. больше α, то гипотеза не подтверждается, что мы можем увидеть в данном случае при α=0,1.
Регрессионный анализ доступен для количественных переменных, относящихся к порядковой, интервальной или относительной шкале. Он позволяет не просто подтвердить связь между переменными, но и определить как измениться зависимая переменная при определённом изменении независимой. Результатом регрессионного анализа является уравнение регрессии вида y=ax+b.
Зависимость может быть разного рода: логарифмическая, экспоненциальная, линейная. Обрабатывая данные, SPSS предлагает значения коэффициентов для составления уравнения, а также проверяет статистическую значимость этих коэффициентов. Эти коэффициенты впоследствии применяются к переменной, логарифму от переменной или экспоненте от переменной. Это определяется по характеру размещения точек на координатной плоскости с помощью визуального анализа, доступного средствами программы. [4, c.846-847] Кроме определения характера связи, регрессионный анализ обладает очень важным прогностическим потенциалом, и оценить возможное значение зависимой переменной мы можем для любого предполагаемого значения независимой.
Например, по материалам исследования, рассмотренного ранее, можно составит уравнение регрессии для зависимости важности ценности сохранять здоровье от доверия к государственному телевидению, что может быть весьма актуальным для оценки действенности социальной рекламы на эту тему и государственных программ популяризации здорового образа жизни. В результате обработки значений этих переменных мы получаем таблицу следующего вида:
| Model | Unstandardized Coefficients | Standardized Coefficients | t | Sig. | ||
| B | Std. Error | Beta | ||||
| 1 | (Constant) | 4,586 | ,036 | 128,845 | ,000 | |
| гос. телевидение | ,134 | ,088 | ,060 | 1,525 | ,128 | |
a Dependent Variable: иметь возможность сохранять здоровье
Таблица 2.5
Где B - это значение коэффициента b, а Beta – значение коэффициента а. В данном случае при изменении доверия к государственному телевидению (х) можно следующим образом спрогнозировать важность ценности сохранить здоровье (у):
у = 0,06х+4,586.
Также имеется возможность оценить статистическую значимость этой зависимости, исходя из значения Sig.
Иногда данные о влиянии средств массовой информации, которые можно собрать в рамках социального исследования, не отражают глубинных факторов этого влияния и могут быть связаны между собой не из-за зависимости друг от друга, но из-за связи с общей скрытой причиной. Для выявления групп переменных, связанных между собой, а также для сокращения объёмов информации, которую необходимо обрабатывать, используется факторный анализ.
«Факторный анализ - группа методов исследования структуры и снижения размерности пространства переменных Модель А.Ф. предполагает, что значение любой измеряемой переменной зависит от небольшого числа латентных (скрытых) факторов. Основной целью А.Ф. является определение латентных факторов по результатам реальных измерений, и снижение размерности за счет замены набора исходных переменных выделенными факторами. В большинстве случаев предполагается, что факторы статистически независимы, т.е. не коррелируют друг с другом» [4, c.45-46].
Для применения факторного анализа необходимо выделить группы переменных, связанных статистически наиболее сильно. Далее следует интерпретировать эту связь. Например, под воздействием продуктов медиа повышается неуверенность в себе, понижается самооценка, нарушается сон. Если эти переменные связаны между собой, можно сделать вывод, что они определяются общим фактором – степенью тревожности. SPSS позволяет создавать искусственную переменную, обозначающую этот фактор, и рассматривать его связь с другими переменными, например, можно ограничиться одной таблицей сопряжённости между частотой просмотра фильмов ужасов и переменной, обозначающей уровень тревожности и включающей в себя влияние всех заменяемых ей переменных.
Ценности, которые были важны для девушек – респондентов рассматриваемого исследования, следующим образом коррелируют между собой:
| Component | ||
| 1 | 2 | |
| получить хорошее образование | ,591 | |
| реализовать свои возможности | ,556 | |
| общаться с интересными людьми | ,693 | |
| Иметь свой бизнес | ,802 | |
| иметь престижное положение в обществе | ,805 | |
| иметь возможности для развлечений | ,586 | |
| Иметь благоустроенное жилье | ,535 | |
| быть материально обеспеченным | ||
| иметь семью и растить детей | ,521 | |
| иметь возможность сохранять здоровье | ,689 | |
| быть уверенным в себе | ,735 | |
| чувствовать собственную защищенность | ,756 | |
Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization.
a Rotation converged in 3 iterations.
Таблица2.6 – Корреляция между ценностями, объединяемыми факторами
На основании этих данных можно выделить две группы ценностей, факторы, которые объединяли переменные, их можно назвать 1-«ценность уверенности» и 2-«ценность престижности». Далее мы можем рассматривать связь переменных, обозначающих эти факторы с доверием к различным СМИ, частотой просмотра новостных сообщений, частотой использования Интернет и т.д.
Также можно выделить различные группы средств массовой информации, которые предпочитают девушки:
|
| Component | ||
| 1 | 2 | 3 | |
| Государственным газетам и журнвлам | ,813 | ||
| гос. Телевидение | ,908 | ||
| гос. Радио | ,911 | ||
| негосуд. газеты и журналы | ,631 | ||
| Негосуд. Телевидение | ,816 | ||
| Негосуд. Радио | ,765 | ||
| Российская пресса | ,672 | ||
| ОРТ | ,518 | ||
| НТВ | ,645 | ||
| Западные СМИ | ,762 | ||
| другие СМИ | ,667 | ||
Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization.
a Rotation converged in 4 iterations.
Таблица 2.7 – Корреляция между доверием СМИ, объединяемыми факторами
Факторный анализ переменных, описывающих доверие к различным СМИ, позволил выделить три группы СМИ. Факторы, объединяющие доверие к этим группам СМИ были описаны как 1-«доверие к государственным СМИ», 2-«доверие к иностранным СМИ» и 3-«доверие к негосударственным СМИ».
И далее, мы можем проверять корреляцию не между только двумя переменными, принимающими, с одной стороны, 2, а с другой – три значения. Корреляция между ними и её статистическая значимость также определяется таким образом, что можно проверить гипотезу о наличии связи.
Таким образом, мы можем определить влияние СМИ на аудиторию подтвердить его результатами анализа. Но на примере факторного анализа мы также видим необходимость совмещения количественного анализа с качественной интерпретацией с точки зрения исследователя.
ГЛАВА 3 ПРОБЛЕМНЫЕ ВОПРОСЫ ИСПОЛЬЗОВАНИЯ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ В ИЗУЧЕНИИ АУДИТОРИИ СМИ
Изучение аудитории СМИ является очень важным аспектом изучения влияния средств массовой информации. «Самым распространённым направлением исследований массовой информации является исследования массовой аудитории. Востребованность этих исследований определяется потребностью субъектов массово-коммуникативной деятельности в знании аудитории, то есть, общественного мнения, с целью наиболее полной реализации возможностей воздействия на него».[3, c. 258] Во-первых, исследования аудитории позволяют собирать данные о потреблении тех или иных медиа-продуктов, что можно потом сопоставлять с эффектами СМИ и делать выводы о влиянии. С другой стороны, изучение аудитории позволяет описывать важнейшие её характеристики. А свойства аудитории являются очень важными факторами влияния СМИ. Например, очень часто возникают исследовательские программы, связанные с влиянием насилия в СМИ на детей. С другой стороны, различные категории населения являются целевыми для различных рекламных кампаний. Необходимо учитывать социально-демографические, культурные и психографические особенности аудитории для изучения воздействия и его прогнозирования.
Однако, существуют различные технологии, в том числе, информационные технологии, сбора и анализа данных об аудитории СМИ, и предпочтение тех или иных является проблемным вопросом изучения влияния СМИ. Традиционно в Беларуси исследования потребления СМИ и медиа-аудиторий проводились методом панельного опроса, при котором одни и те же респонденты в течение продолжительного времени заполняют анкеты о потреблении ими продуктов электронных и печатных СМИ. Для обработки данных анкетных исследований в Беларуси используется программный продукт PaloMARS. С другой стороны, существует способ сбора данных о телесмотрении с использованием технологии пиплметрии, которые позволяют автоматически собирать данные о включении и выключении той или иной программы различными членами домохозяйства. Программный продукт, обрабатывающий данные пиплметрии в Беларуси, комплексное программное приложение МедиаКлиент и МедиаСервер.
Преимущество анкетного опроса состоит в том, что в нём отображаются действительно те продукты медиа, которые человек видел, обратил на них внимание и помнит об этом. С другой стороны, некоторые исследователи критикуют возможности человеческой памяти, а также ответственность и правдивость респондентов. Ещё одним недостатком подобного способа сбора данных об аудитории является отсутствие необходимой точности: респоденты заполняют анкеты с точки зрения больших временных промежутком (в Беларуси – 15 минут для радио и телевидения), что не позволяет программе, обрабатывающей данные, предлагать информацию от поминутном телесмотрении (хотя, это может быть важно для изучения аудитории коротких рекламных блоков). Кроме того, люди могут отказываться фиксировать игнорирование ими рекламы и переключения с канала на канал, из-за чего данные об аудитории рекламных блоков могут быть завышены.
При использовании пиплметров точность сильно повышается, можно отслеживать аудиторию телеканалов поминутно. Однако, есть вероятность того, что включённый телевизор не является гарантией присутствия в том же помещении кого бы то ни было, а тем более внимания к телепередаче, что искажает представления о характере и численности аудитории и затрудняет изучения влияния медиа.
Для анализа данных панельных опросов телеаудитории в Беларуси используется программа PaloMARS. «PaloMARS v2.0 – это система анализа данных о поведении телеаудитории, предназначенная для использования телевизионными компаниями, рекламными агентствами и независимыми компаниями, работающими в области рекламы.
PaloMARSv2.0 использует данные TB-метрии и историческое расписание телепередач в формате, принятом в конкретной стране. Используя PaloMARS v2.0 вы имеете возможность анализировать следующие телевизионные или медиа события:
Программы;
Споты – единичные выходы рекламы;
Брейки – блоки рекламных объявлений. Существуют два вида брейков:
-внутренние, когда реклама выходит во время программы
-внешние, когда реклама выходит между программами
Пользовательские программы – это программы из расписания, создаваемого приложением прогнозирования Shedule Builder, загруженные в базу данных». [6, c. 13]
С помощью этого программного продукта, на основании имеющейся базы данных (среди которых выделяется телесмотрение респондентов по каналам и временным промежуткам, а также база выходивших в эфир программ и рекламных блоков) можно формировать различные отчёты. «В PaloMARS v2.0 существуют следующие типы отчетов:
Time Band Report, Ranker, Simple Report, Multidimentional Report, Channel Report, Curves Report, Postcampaign Report by Breaks». [6, c. 38]
Эти отчёты дают возможность анализировать статистики, описывающие телесмотрение по временным промежуткам, отдельным программам, телеканалам, а также предоставляют возможность анализировать результаты рекламных кампаний с точки зрения рейтингов, охватов и др.
Очень важной характеристикой программного продукта является возможность формирования отчётов для различных аудиторий. Целевые аудитории определяются с точки зрения пола, возраста, населённого пункта или типа населенного пункта, дохода, а также могут быть взвешены в разных долях по отношению к каждому признаку (например, можно определить целевую аудиторию, в которой 70% будут составлять женщины, а 30% - мужчины).
Среди статистик, вычисляемых программой, стоит отметить: размер аудитории, рейтинг (доля аудитории среди целевой группы), охват (отношение всех, кто сталкивался с передачей или роликом заданное количество раз, к целевой аудитории), средняя частота контакта, количество контактов, среднее время просмотра передачи и др.
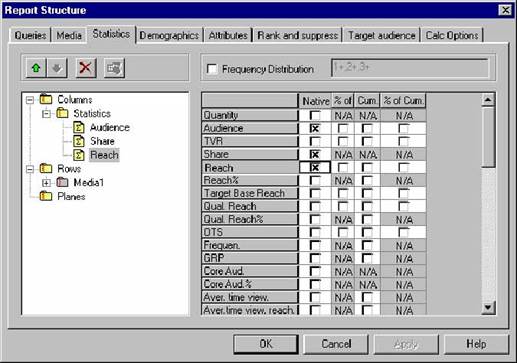 |
Рисунок 3.1 – Окно выбора статистик PaloMARS
Программа предоставляет возможность рассчитывать как средние за период, так и суммарные показатели телесмотрения. Эти возможности отражены в диалоговом окне параметров отчёта Calc Options.
С помощью этого диалогового окна можно выбирать также определение зрителя (те, кто смотрели передачу в течение определённого времени или определённый процент времени от длительности передачи). Кроме того, есть возможность определять базовую дату для расчета. Из-за того, что заполнение анкет-дневников телесмотрения для респондентов является трудоёмким и утомительным занятием, чередуются две выборки. Для статистических же расчетов, нужно, чтобы выборка респондентов была одна и та же, поэтому определяется базовая дата. «В идеале, для получения независимых результатов анализа, должна использоваться одна и та же выборка респондентов для всего периода. Это не всегда возможно на практике. Для решения этой проблемы PaloMARSv2.0 предлагает вам выбрать базовую дату.
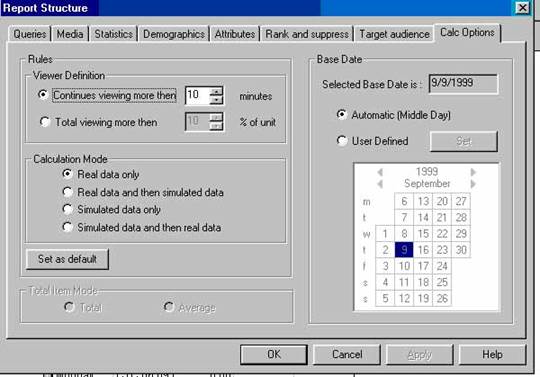
Рисунок 3.2 – Окно определения параметров расчётов в PaloMARS
Наиболее часто используемый способ задания базовой даты – это метод Middle Day. В нем используется выборка среднего дня (с учетом весов). PaloMARSv2.0 автоматически определяет средний день. Вы можете задать любую другую дату в качестве базовой для проведения расчетов». Однако, с другой стороны, при этом используются прогнозные показатели для второй части выборки, что также может искажать данные. Это является ещё одним недостатком панельного метода сбора данных и обработки его в PaloMARS, который снимается в пиплметрических исследованиях, где труднее договорится об установке пиплметра, но нет необходимости чередовать выборки и выборка остаётся постоянной.
Для решения проблем, связанных с недостатками использования панельного дневникового опроса, в Беларуси начали использовать пиплметрию и на базе Института Социологии НАН был разработан комплексный программный продукт МедиаКлиент и МедиаСервер. Если программа Паломарс предполагает загрузку данных и их обработку в рамках одной организации, то подробный оперативный сбор данных пиплметрии не даёт возможности загрузки данных для всех использующих их организаций. Организации используют МедиаКлиент для формирования структуры отчётов и посылают запрос на МедиаСервер, который предоставляет отчёт, сформированный по запросу.
Пиплметрия – технология сбора данных о телесмотрении. «Базируется она на использовании специализированного оборудования (пиплметров), которое подключается к телевизорам, имеющимся в квартире, и в автоматическом режиме с посекундной точностью фиксирует время включения и выключения различных телеканалов. Также каждому члену семьи на пульте дистанционного управления назначается «своя кнопка», которую он один раз нажимает, когда начинает смотреть телевизор и еще раз, когда заканчивает. Сложение данных счетчика о работе телевизора и записей индивидуального просмотра дает точное знание о фактической аудитории каждого телеканала, передачи или рекламного ролика». Выделяют следующие преимущества такого сбора данных: «Его основными преимуществами, благодаря которым он заменил опросные методы (в том числе и дневниковый) в большинстве развитых стран Европы и Америки еще в конце 20-го века, являются:
запись информации происходит полностью автоматически, а не по памяти, что значительно упрощает работу участников и, как следствие, улучшает качество данных;
исключена возможность умышленного или неумышленного искажения информации участником исследования, так как нет необходимости «от руки» записывать «что смотрелось»;
посекундная фиксация смотрения позволяет учитывать очень важный момент оттока зрителей во время выхода рекламы, что дает возможность рассчитать реальное количество контактов зрителей именно с рекламным роликом, а не с передачей, внутри которой он выходил и показатели которой, как правило, намного выше;
высокая оперативность передачи данных в аналитический центр: с утра уже известны данные за вчерашний день, что позволяет вовремя реагировать на различные промежуточные результаты в ходе рекламной кампании.
появляется возможность использовать так называемую систему «продаж по рейтингам». Суть заключается в том, что рекламодатель платит не за время на телеканале (которое может оказаться с низкими рейтингами), а сразу за нужный ему результат – гарантированное количество контактов зрителей с его рекламным сообщением. И уже задача телеканала это обеспечить, выпуская рекламу в передачах с соответствующими рейтингами». [7, c. 1]
Данные, собранные с помощью приборов «Телемер» заносятся в базу данных и обрабатываются. «Программное обеспечение предназначено для совместного анализа данных о телепросмотре, которые собираются методом пиплметрии, и выходах эфирных событий (пере
|
|
|
