 |


Формальная грамматика есть четверка
|
|
|
|
Постановка задачи
Цель работы заключается в разработке программного продукта, выполняющего синтаксический анализ кода с использованием языка C.
Язык C имеет свои существенные особенности, которые будут использоваться в дальнейшем. Язык C обеспечивает поддержку структурного программирования, содержа в своем составе полный набор операторов, отвечающих этой парадигме. Это достаточно хорошо сочетается в языке С с гибкой и элегантной нотацией операторов, позволяющей писать выразительный код.
Многие операции C соответствуют машинным командам, и поэтому допускают прямую трансляцию в машинный код. Разнообразие операций дает возможность их гибкого сочетания для оптимизации кода по различным критериям. В языке C существует механизм управления памятью, реализованный через поддержку указатели на переменные и функции. Указатель на объект программы соответствует машинному адресу этого объекта. Манипулируя указателями, можно получать доступ к тому или иному объекту, а также размещать структуры данных, могущих занимать большой объем памяти.
Функция scanf() (прототип содержится в файле stdio.h) обеспечивает форматированный ввод. Ее можно записать в следующем формальном виде:
scanf(«управляющая строка», аргумент_1, аргумент_2,...);
Аргументы scanf() должны быть указателями на соответствующие значения. Для этого перед именем переменной записывается символ &. Назначение указателей будет рассмотрено далее.
Управляющая строка содержит спецификации преобразования и используется для установления количества и типов аргументов. В нее могут включаться:
• пробелы, символы табуляции и перехода на новую строку (все они игнорируются);
|
|
|
• спецификации преобразования, состоящие из знака %, возможно, символа * (запрещение присваивания), возможно, числа, задающего максимальный размер поля, и самого символа преобразования;
• обычные символы, кроме % (считается, что они должны совпадать с очередными неизвестными символами во входном потоке).
Если в строке форматирования встретится разделитель, то функция scanf() пропустит один или несколько разделителей во входном потоке. В качестве разделителя, или пробельного символа, понимается пробельный символ(пробел), символ табуляции или разделитель строк (символ новой строки). Нахождение одного разделителя в управляющей строке изменит поведение функции ввода. В этом случае функция scanf() будет читать, не сохраняя, любое количество (возможно, даже нулевое) разделителей до первого символа, отличного от разделителя.
Если в строке форматирования встретился символ, отличный от разделителя, то функция scanf() прочитает и отбросит его. Например, если в строке форматирования встретится %d, %d, то функция scanf() сначала прочитает целое значение, затем прочитает и отбросит запятую и, наконец, прочитает еще одно целое. Если заданный символ не найден, функция scanf() завершает работу.
Все переменные, получающие значения с помощью функции scanf(), должны передаваться посредством своих адресов. Это значит, что все аргументы должны быть указателями на переменные.
Элементы входного потока должны быть разделены пробелами, символами табуляции или разделителями строк. Такие символы, как запятая, точка с запятой и т.п., не распознаются в качестве разделителей. Это означает, что оператор
scanf(«%d%d», &r, &c);
примет значения, введенные как 10 20, но откажется от последовательности символов 10, 20.
Символ *, стоящий после знака % и перед кодом формата, прочитает данные заданного типа, но запретит их присваивание. Пусть, например, задан оператор вида
|
|
|
scanf(«%d%*c%d», &x, &y);
при вводе данных в виде 10/20 поместит значение 10 в переменную x, отбросит знак деления и присвоит значение 20 переменной у.
Команды форматирования могут содержать модификатор максимальной длины поля. Он представляет собой целое число, располагаемое между знаком % и кодом формата, которое ограничивает количество читаемых для всех полей символов.
Грамматика
В основе моделирования языков программирования и ряда других приложений одним из важнейших является определение формального языка. Всякий язык программирования можно определить как множество предложений – некоторое множество цепочек или конечных последовательностей элементарных единиц из некоторого непустого конечного множества символов, называемого словарем или алфавитом. При таком рассмотрении языка программирования задается только множество символов, которые можно использовать для записи программы, а также класс допустимых или синтаксически правильных программ и при этом не затрагивается вопрос задания смысла каждой правильной программы. Чтобы отличать употребление слова «язык» в значении точно определенного множества цепочек от употребления этого слова в повседневной речи, множество цепочек иногда называют формальным языком [2,3].
Обычный подход, удовлетворяющий указанному выше требованию задания языка, состоит в том, что предложения языка образуются по определенным правилам, в совокупности составляющим то, что называют грамматикой языка. Эти грамматические правила приписывают предложениям языка некоторую синтаксическую структуру, которая может использоваться при задании и определении смысла предложений.
Синтаксис – внешнее представление предложений языка.
Семантика – смысловое содержание предложений языка.
Набор правил, определяющих синтаксис языка, образует грамматику языка.
Формальная грамматика – абстрактное обобщение грамматики естественных языков – рассматривает строки (цепочки) символов.
Формальная грамматика есть четверка
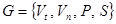 (1)
(1)
где  – алфавит терминальных символов, т.е. символов, которые могут входить в левые части правил (соответствует набору слов и знаков языка);
– алфавит терминальных символов, т.е. символов, которые могут входить в левые части правил (соответствует набору слов и знаков языка);
 – алфавит нетерминальных символов (соответствует набору обобщающих понятий языка);
– алфавит нетерминальных символов (соответствует набору обобщающих понятий языка);
|
|
|
 – набор порождающих правил вида
– набор порождающих правил вида  , где
, где  и
и  – цепочки терминальных и нетерминальных символов;
– цепочки терминальных и нетерминальных символов;
 – начальный символ грамматики.
– начальный символ грамматики.
Грамматика 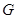 для любой цепочки
для любой цепочки  задает множество выводимых из нее цепочек, определяя их рекурсивно следующим образом: если
задает множество выводимых из нее цепочек, определяя их рекурсивно следующим образом: если  содержится в , то цепочка
содержится в , то цепочка  непосредственно выводима из
непосредственно выводима из  (обозначается
(обозначается  ), если
), если  выводима из и
выводима из и  , то
, то 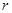 нетривиально выводима из (
нетривиально выводима из (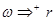 ); если или
); если или  , то выводима из (
, то выводима из ( ). Последовательность применения правил
). Последовательность применения правил 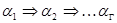 называется выводом цепочки , если
называется выводом цепочки , если  ,
, 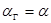 .
.
Цепочка, выводимая из , называется сентенциальной формой. Сентенциальная форма не содержащая нетерминальных символов, называется предложением. Множество предложений образует язык, порожденный грамматикой ( ).
).
Согласно Хомскому, можно выделить четыре типа грамматик. типа 0, типа 1, типа 2, типа 3. Язык, порождаемый грамматикой типа k (k=0,1,2,3), является языком типа k.
Любая порождающая грамматика является грамматикой типа 0.
На вид правил грамматик этого типа не накладывается никаких дополнительных ограничений. Класс языков типа 0 совпадает с классом рекурсивно перечислимых языков (распознаваемых машиной Тьюринга).
Грамматикой типа 1 будем называть неукорачивающую грамматику.
Грамматика называется неукорачивающей, если левая часть каждого правила из не короче правой части (т. е. для любого правила из выполняется неравенство  ).
).
В виде исключения в неукорачивающей грамматике допускается наличие правила  , при условии, что (начальный символ) не встречается в правых частях правил.
, при условии, что (начальный символ) не встречается в правых частях правил.
Грамматикой типа 2 будем называть контекстно-свободную грамматику.
Грамматика называется контекстно-свободной (КС), если каждое правило из имеет вид 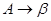 , где
, где  ,
,  .
.
В КС-грамматиках допускаются правила с пустыми правыми частями.
Язык, порождаемый контекстно-свободной грамматикой, называется контекстно-свободным языком.
Грамматика называется праволинейной, если каждое правило из имеет вид 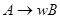 либо
либо  , где
, где  ,
,  . Здесь
. Здесь  – множество строк над алфавитом .
– множество строк над алфавитом .
Грамматика называется леволинейной, если каждое правило из если каждое правило из имеет вид  либо , где , .
либо , где , .
|
|
|
Праволинейные и леволинейные грамматики определяют один и тот же класс языков. Такие языки называются регулярными. Право- и леволинейные грамматики тоже называют регулярными. Регулярная грамматика является грамматикой типа 3.
Справедливы следующие соотношения:
· любая регулярная грамматика является КС-грамматикой;
· любая неукорачивающая КС-грамматика является КЗ-грамматикой;
· любая неукорачивающая грамматика является грамматикой типа 0.
Рассмотрим вопрос записи порождающих правил грамматики. Основным способом их представления является форма Бэкуса-Наура (БНФ). Метаязык, предложенный Бэкусом и Науром, впервые использовался для описания синтаксиса реального языка программирования Алгол 60. Наряду с новыми обозначениями метасимволов, в нем использовались содержательные обозначения нетерминалов. Это сделало описание языка нагляднее и позволило в дальнейшем широко использовать данную нотацию для описания реальных языков программирования. Были использованы следующие обозначения:
· символ «::=» отделяет левую часть правила от правой;
· нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки «<» и «>»;
· терминалы – это символы, используемые в описываемом языке;
· каждое правило определяет порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты «|».
БНФ-конструкция определяет конечное число символов (нетерминалов). В ней также задаются правила замены символа на какую-то последовательность букв (терминалов) и символов. Процесс получения цепочки букв, можно определить поэтапно. В начале имеется один символ. Затем этот символ заменяется на некоторую последовательность букв и символов, согласно одному из правил. Затем процесс повторяется (на каждом шаге один из символов заменяется на последовательность, согласно правилу). В конце концов, получается цепочка, состоящая из букв (и не содержащая символов). Это означает, что полученная цепочка может быть выведена из начального символа. Сами символы обычно заключаются в угловые скобки, а их название не несёт никакой информации.
Такая форма представления обеспечивает понятное представление и дает наглядную интерпретацию записи правил порождающей грамматики.
|
|
|
