 |


Тема 3. Структура и организация баз данных
|
|
|
|
Оглавление
| Тема 1. История развития баз данных ………………………………… | |
| Тема 2. Основные понятия и определения БД ……………………… | |
| Тема 3. Структура и организация баз данных ………………………... | |
| Тема 4. Реляционная модель баз данных ……………………………… | |
| Тема 5. Объектная модель баз данных…………………………………. | |
| Тема 6. Программно-аппаратный уровень процесса накопления данных | |
| Перечень вопросов для подготовки к экзамену по всему курсу…….. | |
| Рекомендуемая литература………………………………………..……… |
Тема 1. История развития баз данных
История возникновения и развития технологий баз данных может рассматриваться как в широком, так и в узком аспекте.
В широком аспекте понятие истории баз данных обобщается до истории любых средств, с помощью которых человечество хранило и обрабатывало данные. В таком контексте упоминаются, например, средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.), узелковая письменность инков — кипу, клинописи, содержащие документы Ассирийского царства и т. п. Следует помнить, что недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».
История баз данных в узком аспекте рассматривает базы данных в традиционном (современном) понимании. Эта история начинается с 1955 г., когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой DBTG (Data Base Task Group), разработавшей стандартный язык определения данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
|
|
|
В это же время в сообществе баз данных COBOL была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Ф. Кодда. Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику Эдгар Ф. Кодд также получил премию Тьюринга.
Сам термин database (база данных) появился в начале 1960-х гг., и был введён в употребление на симпозиумах, организованных фирмой SDC (System Development Corporation) в 1964 и 1965 гг.
Тема 2. Основные понятия и определения БД
Ба́за да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ) (Гражданский кодекс РФ, ст. 1260).
Другие определения из авторитетных монографий и стандартов:
База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей.
База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.
|
|
|
База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия.
База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
Существует множество других определений, отражающих скорее субъективное мнение тех или иных авторов о том, что означает база данных (БД) в их понимании, однако общепризнанная единая формулировка отсутствует. Наиболее часто используются следующие отличительные признаки:
БД хранится и обрабатывается в вычислительной системе.
Таким образом, любые внекомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются.
Данные в БД логически структурированы (систематизированы) с целью обеспечения возможности их эффективного поиска и обработки в вычислительной системе.
Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика и допустимые операции.
БД включает метаданные, описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью).
В соответствии с ГОСТ Р ИСО МЭК ТО 10032-2007, «постоянные данные в среде базы данных включают в себя схему и базу данных. Схема включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных. База данных включает в себя набор постоянных данных, определенных с помощью схемы. Система управления данными использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных».
Классификации БД
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям (например, в «Энциклопедии технологий баз данных» определяются свыше 50 видов БД).
Укажем только основные классификации.
Классификация БД по модели данных:
Примеры:
иерархические,
сетевые,
реляционные,
объектные и объектно-ориентированные,
объектно-реляционные.
|
|
|
Классификация БД по среде физического хранения:
БД во вторичной памяти (традиционные): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск. В оперативную память СУБД помещает лишь кеш и данные для текущей обработки.
БД в оперативной памяти (in-memory databases): все данные находятся в оперативной памяти.
БД в третичной памяти (tertiary databases): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков. Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кеш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация БД по содержимому:
Примеры:
географические;
исторические;
научные;
мультимедийные.
Классификация БД по степени распределённости:
централизованные (сосредоточенные);
распределённые.
Тема 3. Структура и организация баз данных
База данных определяется как совокупность взаимосвязанных данных, характеризующихся возможностью использования для большого количества приложений, возможностью быстрого получения и модификации необходимой информации, минимальной избыточностью информации, независимостью от прикладных программ, общим управляемым способом поиска.
Возможность применения баз данных для многих прикладных программ пользователя упрощает реализацию комплексных запросов, снижает избыточность хранимых данных и повышает эффективность использования информационной технологии. Минимальная избыточность и возможность быстрой модификации позволяют поддерживать данные на одинаковом уровне актуальности. Независимость данных и использующих их программ является основным свойством баз данных. Независимость данных подразумевает, что изменение данных не приводит к изменению прикладных программ и наоборот.
Модели баз данных базируются на современном подходе к обработке информации, состоящем в том, что структуры данных обладают относительной устойчивостью. Действительно, типы объектов предприятия, для управления которым создается информационная технология, если и изменяются во времени, то достаточно редко, а это приводит к тому, что и структура данных для этих объектов достаточно стабильна. Поэтому возможно построение информационной базы с постоянной структурой и изменяемыми значениями данных. Каноническая структура информационной базы, отображающая в структурированном виде информационную модель предметной области, позволяет сформировать логические записи, их элементы и взаимосвязи между ними. Взаимосвязи могут быть типизированы по следующим основным видам:
|
|
|
• "один к одному", когда одна запись может быть связана только с одной записью;
• "один ко многим", когда одна запись взаимосвязана со многими другими;
• "многие ко многим", когда одна и та же запись может входить в отношения со многими другими записями в различных вариантах.
Здесь необходимо ввести понятие записи и поля:
Запись – собрание взаимосвязанной информации, которая рассматривается как единое целое в файле или базе данных компьютера. Например, файл о заработной плате персонала компании может быть подразделен на отдельные записи о каждом работнике. Записи обычно делятся на поля по именам, размеру заработной платы, коду налога и т.д.
Поле – элемент данных. К примеру, в записи о покупателях имя является одним полем, а адрес - другим. Набор полей, относящихся к одному предмету, представляет собой запись.
Применение того или иного вида взаимосвязей определило три основные модели баз данных: иерархическую, сетевую, реляционную.
Для пояснения логической структуры основных моделей баз данных рассмотрим такую простую задачу: необходимо разработать логическую структуру БД для хранения данных о трех поставщиках: П1, П2 и П3, которые могут поставлять товары Т1, Т2 и Т3 в следующих комбинациях: поставщик П1 - все три вида товаров, поставщик П3 - товары Т1, и Т3, поставщик П3 - товары Т2 и Т3.
Сначала построим логическую модель БД, основанную на иерархическом подходе. Иерархическая модель представляется в виде древовидного графа, в котором объекты выделяются по уровням соподчиненности (иерархии) объектов (рис. 1).
На верхнем, первом уровне находится информация об объекте "поставщики" (П), на втором - о конкретных поставщиках П1, П2 и П3, на нижнем, третьем, уровне - о товарах, которые могут поставлять конкретные поставщики.
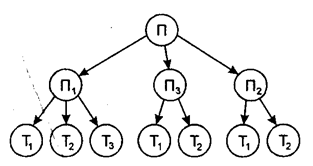
Рис. 1. Иерархическая модель БД
В иерархической модели должно соблюдаться правило: каждый порожденный узел не может иметь больше одного порождающего узла (только одна входящая стрелка); в структуре может быть только один непорожденный узел (без входящей стрелки) - корень. Узлы, не имеющие входных стрелок, носят название листьев. Узел интегрируется как запись. Для поиска необходимой записи нужно двигаться от корня к листьям, т.е. сверху вниз, что значительно упрощает доступ.
|
|
|
Достоинство иерархической модели данных состоит в том, что она позволяет описать их структуру как на логическом, так и на физическом уровне.
Недостатками данной модели являются жесткая фиксированность взаимосвязей между элементами данных, вследствие чего любые изменения связей требуют изменения структуры, а также жесткая зависимость физической и логической организации данных. Быстрота доступа в иерархической модели достигнута за счет потери информационной гибкости (за один проход по дереву невозможно, например, получить информацию о том, какие поставщики поставляют, скажем, товар Т1). Указанные недостатки ограничивают применение иерархической структуры.
В иерархической модели используется вид связи между элементами данных "один ко многим". Если применяется взаимосвязь вида "многие ко многим", то приходят к сетевой модели данных.
Сетевая модель базы данных для поставленной задачи представлена в виде диаграммы связей (рис. 2).

Рис. 2. Сетевая модель БД
На диаграмме указаны независимые (основные) типы данных П1, П2 и П3, т.е. информация о поставщиках, и зависимые - информация о товарах Т1, Т2 и Т3. В сетевой модели допустимы любые виды связей между записями и отсутствует ограничение на число обратных связей. Но должно соблюдаться одно правило: связь включает основную и зависимую записи.
Достоинство сетевой модели БД - большая информационная гибкость по сравнению с иерархической моделью. Однако сохраняется общий для обеих моделей недостаток -достаточно жесткая структура, что препятствует развитию информационной базы системы управления. При необходимости частой реорганизации информационной базы (например, при использовании настраиваемых базовых информационных технологий) применяют наиболее совершенную модель БД - реляционную, в которой отсутствуют различия между объектами и взаимосвязями.
В реляционной модели базы данных взаимосвязи между элементами данных представляются в виде двумерных таблиц, называемых отношениями. Отношения обладают следующими свойствами: каждый элемент таблицы представляет собой один элемент данных (повторяющиеся группы отсутствуют); элементы столбца имеют одинаковую природу, и столбцам однозначно присвоены имена; в таблице нет двух одинаковых строк; строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания. Преимуществами реляционной модели БД являются простота логической модели (таблицы привычны для представления информации); гибкость системы защиты (для каждого отношения может быть задана правомерность доступа); независимость данных; возможность построения простого языка манипулирования данными с помощью математически строгой теории реляционной алгебры (алгебры отношений). Собственно, наличие строгого математического аппарата для реляционной модели баз данных и обусловило ее наибольшее распространение и перспективность в современных информационных технологиях.
Для приведенной выше задачи о поставщиках и товарах логическая структура реляционной БД будет содержать три таблицы (отношения): R1, R2, R 3, состоящие соответственно из записей о поставщиках, о товарах и о поставках товаров поставщиками (рис. 3).
| R1 (поставщики) | R2 (товары) | |
| П1 | Т1 | |
| П2 | Т2 | |
| П3 | Т3 |
| R3 (поставка товара) | |
| П1 | Т1 |
| П1 | Т2 |
| П1 | Т3 |
| П2 | Т1 |
| П2 | Т3 |
| П3 | Т2 |
| П3 | Т3 |
Рис. 3. Реляционная модель БД
Учитывая широкое применение реляционных моделей баз данных в информационных технологиях (особенно экономических), дадим более подробное описание этой структуры.
|
|
|
