 |


Пример проведения цикла экспериментов на кластерной вычислительной системе.
|
|
|
|
Лабораторная работа № 1
Создание параллельной программы с использованием интерфейса MPI и проведение экспериментов с ней на вычислительной системе.
Цель работы
Знакомство с MPI – средством параллельного программирования многопроцессорных систем с распределенной памятью в модели передачи сообщений. Постановка экспериментов на системе с несколькими процессорными ядрами и исследование изменения коэффициента ускорения выполнения программы в зависимости от числа задействованных процессорных ядер и объема обрабатываемых данных.
Условия выполнения работы
Лабораторная работа выполняется на многоядерной вычислительной системе, которая содержит несколько процессорных ядер в рамках одного или нескольких процессоров. При этом, система может содержать один или несколько вычислительных узлов, а также иметь общую или распределенную между процессорными ядрами или комбинированную память. На системе должна быть установлена среда программирования C и/или C++ с транслятором в ее составе. Также должна быть установлена и адаптирована к среде программирования реализация интерфейса стандарта MPI [1] с загрузчиком приложений.
Порядок выполнения работы
Лабораторная работа выполняется в три этапа. На первом этапе, студенты (распределенные по одиночке или по бригадам) получают от преподавателя задания на создание программы (по вариантам), которую реализуют средствами языка С в последовательном виде. Программа создается таким образом, чтобы в процессе работы с ней можно было изменять объем обрабатываемых ею данных. Также в созданную программу вставляются функции замера времени, которые дают возможность определять длительность выполнения программы в целом или ее фрагментов. Для достижения наглядности результата и во избежание излишних трудностей и программировании, студентам задается создание простых программ, реализующих поэлементные операции с одномерными векторами.
|
|
|
На втором этапе студенты, на основе своей последовательной программы (не уничтожая ее) создают параллельную программу. Параллельная программа создается в силе MPI, то есть текст исходной программы на языке C модернизируется и в него, для взаимодействия между параллельными процессами, включаются функции интерфейса стандарта MPI. Обе программы – исходная последовательная и вновь созданная параллельная – запускаются на исполнение для проверки их функциональной эквивалентности.
На третьем этапе, студенты ставят на многоядерной вычислительной системе эксперименты со своей параллельной программой. В ходе экспериментов они изменяют объем, обрабатываемых в своих программа данных, а также изменяют объем, обрабатываемых в своих программах данных, а также изменяют число задействованных для выполнения параллельной программы процессорных ядер. Времена выполнения параллельной программы на множестве процессорных ядер. Времена выполнения параллельной программы на множестве процессорных ядер они сопоставляют с временами выполнения программы на одном ядре и вычисляют коэффициенты ускорения. Исследуя эти коэффициенты, студенты выбирают лучшие варианты выполнения программы из опробованных ими.
Пример программы
Пусть, по заданию требуется создать программу, реализующую выполнение операций над элементами массивов A, B и C по следующей формуле:

где A – двухмерный массив размерностью  , а массивы B и C одномерные размерностью N1. Сначала создается последовательная программа, а потом на основе ее, используя средства интерфейса стандарта MPI, создается параллельная программа (MPI-программа) в модели SPMD Single Program, Multiple Data – один программный код для всех параллельных процессов, множество наборов данных [1], для каждого процесса свой набор данных). В этой программе надо предусмотреть возможность ее выполнения любым (в пределах от 1 до 16) числом процессов.
, а массивы B и C одномерные размерностью N1. Сначала создается последовательная программа, а потом на основе ее, используя средства интерфейса стандарта MPI, создается параллельная программа (MPI-программа) в модели SPMD Single Program, Multiple Data – один программный код для всех параллельных процессов, множество наборов данных [1], для каждого процесса свой набор данных). В этой программе надо предусмотреть возможность ее выполнения любым (в пределах от 1 до 16) числом процессов.
|
|
|
Итак, создадим сначала обычную последовательную программу на языке C (см. программу 1.1).
Программа 1.1. Последовательная программа
#include <stdio.h>
#define N1 32
#define N2 64
void main(int argc, char ** argv)
{
float A[N1][N2], B[N1], C[N1];
int i,j,k;
// Инициализация исходных данных
for (i=0;i<N1;i++)
{
for (j=0;j<N2;j++) A[i][j]=i+j;
B[i]=j;
}
// Вычисления
for (i=0;i<N1;i++)
{
C[i] = 0;
for(j=0;j<N2;j++) C[i] += B[i]*A[i][j];
}
// Вывод результатов
for(i = 0; i < N1; i++) printf("%f ", C[i]);
}
Поскольку в задании не указаны конкретные значения исходных данных, в программе они задаются произвольно. Потом по представленной программе осуществляются вычисления. И на экран выводятся результаты.
Теперь на основе этой программы создадим параллельную программу, которая могла бы выполняться произвольным числом процессов. В созданную программу включим функции определения времени, также специальный цикл (назовем его «Цикл кратности»). Который позволит выполнить основную часть программы многократно и таким образом искусственно увеличить время ее выполнения. Последнее делается для того, чтобы снизить влияние погрешностей в работе функций определения времени.
Поскольку в тексте программы описываются статические переменные, то у каждого процесса (в модели SPMD) будет свой экземпляр этих переменных. Хотя составы статических переменных у процессов будут одинаковые, но содержимое переменных у каждого процесса будет свое. Например, если в тексте программы описана статическая переменная, то у каждого процесса будет свой экземпляр этой переменной, но ее содержимое у каждого процесса будет свое. Если данные одного процесса нужны в другом, то они передаются с помощью вставленных в текст программы функций MPI.
#include <stdio.h>
#include "mpi.h" // Заголовочный файл интерфейса MPI
#define N1 32
#define N2 64
void main(int argc, char **argv)
{
float A[N1][N2], B[N1], C[N1];
int rank, size, cicle, i,j,k;
double time, time1,time2;
MPI_Status status; // Переменная-структура в которую будут
// сохранятся параметры принимаемых
|
|
|
// сообщений с данными
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf("Hello(%d)-%d\n", rank, size);
if (rank==0) // Если процесс нулевой
{
for (i=0;i<N1;i++)
{ for (j=0; j<N2; j++) A[i][j]=i+j; // Инициализация массива А
B[i]=i; // Инициализация массива B
}
time1=MPIWtime(); // Определение времени начала обработки
for (cicle=0;cicle<10000;cicle++) // "Циклкратности"
{
for(i=1;i<size;i++) // Распределение элементов массива B
// между процессами
MPI_Send(&B[(int)i*N1/size],(int)N1/size,MPI_FLOAT,i,0,MPI_COMM_WORLD);
for(i=0;i<N1/size;i++) // Цикл вычислений
{ C[i] = 0;
for(i=1;i<size;i++) // Сбор результатов в массив C
MPI_Recv(&C[(int)i*N1/size],(int)N1/size,MPI_FLOAT,i,0,MPI_COMM_WORLD, &status);
} // Конец цикла кратности
time2 = MPI_Wtime(); // Определение времени конца обработки
time=time2-time1;
for (i=0;i<N1;i++) printf("%f ", C[i]); // Вывод результатов
if (rank==0) printf("\nTIME=%f\n",time); // Вывод времени
// выполнения
}
else // Если процесс не нулевой
{
for (i=0;i<N1;i++)
for (j=0;j<N2;j++ A[i][j]=i+j; // Инициализация массива A
// во всех процессах
for (cicle=0;cicle < 10000; cicle++) // "Цикл кратности"
{
MPI_recv(&B[(int)rank*N1/size,(int)N1/size,MPI_FLOAT,0,0,
MPI_COMM_WORLD, &status); // Прием элементов массива B
// от нулевого процесса
for (i=rank*N1/size;i<(rank+1)*N1/size;i++)
{ C[i]=0;
for (j=0;j<N2;j++)
C[i]+=B[i]+A[i][j];
}
// Передача результатов нулевому процессу
MPI_Send(&C[(int(rank*N1/size],(int)N1/size,MPI_FLOAT,0,0,NPI_COMM_WORLD);
}
}
MPI_Finalize();
}
Число процессов, которые будут выполнять параллельную программу, указывается при ее запуске на вычислительной системе. Каждому процессу при запуске присваивается числовой идентификатор (рэнк), то есть его индивидуальный номер, который он может получить с помощью функции MPI_Comm_rank (синтаксис этих и других функций см. Приложение). Процессы нумеруются с нулевого до size – 1, где size – число запущенных процессов при выполнении программы. Для хранения числа запущенных процессов в программе использована целочисленная переменная size, значение которой задает функция MPI_Comm_size. Для хранения номера процесса в программе использована переменная rank.
Что касается исходных данных в параллельной программе, то пусть изначально, согласно заданию, исходные данные считаются распределенными следующим образом:
|
|
|
· Необходимые для расчетов значения элементов массива A уже имеются в памяти всех запущенных процессов;
· Необходимые для расчетов значения элементов массива B находятся только в памяти нулевого процесса.
Пусть, согласно заданию, необходимо собрать результаты вычислений в массиве С в памяти нулевого процесса.
Действия, выполняемые процессами, разделены на две группы. Первая группа – это действия, выполняемые нулевым процессом. Условием перехода к этим действиям является нулевое значение переменой rank. Вторая группа – это действия, выполняемые остальными процессами. Если для выполнения программы был запущено только один процесс, то выполнены будут действия только нулевого процесса.
Нулевой процесс задает исходные значения элементам массивов A и B. Далее, если программа выполняется несколькими процессами, то он в цикле посылает этим процессам значения элементов массива В. Потом он осуществляет вычисление значений N1/size элементов массива С. По окончании работы, нулевой процесс принимает с других процессов вычисленные ими значения элементов массива С и выводит их на стандартный вывод. Если при выполнении программы был запущен только один процесс (т.е. size – 1), то им будут вычислены значения всех N1 элементов массива С. Следует заметить, что для корректной работы этой программы, желательно подобрать N1 и size таким образом, чтобы при делении N1/size не оставалось остатка.
Для определения времени начала и конца обработки, нулевым процессом дважды вызывается функция MPI_Wtime. Для искусственного увеличения времени обработки, в программу вставлен «цикл кратности».
Все процессы, у которых значение переменной rank не равно нулю, выполняют одинаковый набор действий. Сначала задаются исходные значения элементов массива А, а после этого в цикле кратности происходит прием от нулевого процесса значений элементов массива В, вычисление своих (для каждого процесса) N1/size элементов массива С и передача их значений нулевому процессу.
Пример проведения цикла экспериментов на кластерной вычислительной системе.
Для проведения экспериментов с разработанной программой используем кластерную вычислительную систему НИУ «МЭИ» (кластер МЭИ, его описание см. [2] гл. 3). Эта кластерная вычислительная система (на момент написания данного текста) имеет 16 вычислительных узлов и один управляющий. Каждый вычислительный узел имеет два двухъядерных процессора AMD Opteron 275. Таким образом, на одном вычислительном узле имеется четыре процессорных ядра.
Система управления заданиями на кластерной системе построена таким образом, что на каждое процессорное ядро назначается только один вычислительный процесс. Чтобы поставить программу в очередь на выполнение необходимо указать число процессов, назначаемое для выполнения на один узел (не более четырех (по числу ядер)) и число задействованных узлов. Произведение этих двух значений равно общему числу процессов, задаваемых для выполнения программы. Таким образом, максимальное число процессов, которое можно задать для выполнения программы равно  .
.
|
|
|
Наш цикл экспериментов будет состоять из нескольких серий. Каждая серия экспериментов будет проводиться со своим фиксированным значением размерностей массивов. В ходе проведения серии экспериментов будет варьироваться число процессов, запускаемых для выполнения программы, а также их распределение по узлам кластера.
Проведем пять серий по 9 экспериментов. Положим, что размерность N1 во всех сериях будет фиксированной N1 = const = 32, а размерность N2 будет выбрана из множества {8,64,256,1024,4096}.
В каждой серии проведем эксперименты для числа процессов равного 1,2,4 и 8. Распределять процессы будем следующим образом:
· Один процесс на одном узле (1/1) – всего один процесс;
· Два процесса на одном узле (1/2) – всего два процесса;
· По одному процессу на двух узлах (2/1) – всего два процесса;
· Четыре процесса на одном узле (1/4) – всего четыре процесса;
· По два процесса на двух узлах (2/2) – всего четыре процесса;
· По одному процессу на четырех узлах (4/1) – всего четыре процесса;
· По четыре процесса на двух узлах (2/4) – всего восемь процессов;
· По два процесса на четырех узлах (4/2) – всего восемь процессов;
· По одному процессу на восьми узлах (8/1) – всего восемь процессов;
В табл. 1.1 приведены результаты экспериментов – времена выполнения параллельной программы на узлах «кластерной системы МЭИ» при числе повторов цикла кратности, равном 10000.
Теперь рассчитаем коэффициенты ускорения. Коэффициент ускорения равен отношению времени выполнения программы одним процессом (на одном процессорном ядре) к времени выполнения программы несколькими процессами. Оба значения времени должны быть получены при одинаковой размерности массивов. Коэффициенты ускорения приведены в табл. 1.2
Таблица 1.1.
Времена выполнения программы при N1 = 32
| N2 | Время выполнения (c/10000) | ||||||||
| (1,1) | (1,2) | (2,1) | (1,4) | (2,2) | (4,1) | (2,4) | (4,2) | (8,1) | |
| 0.004 | 0.019 | 0.100 | 0.037 | 0.110 | 0.131 | 0.242 | 0.260 | 0.305 | |
| 0.041 | 0.037 | 0.117 | 0.045 | 0.120 | 0.131 | 0.242 | 0.261 | 0.305 | |
| 0.154 | 0.093 | 0.176 | 0.073 | 0.149 | 0.153 | 0.253 | 0.260 | 0.303 | |
| 0.602 | 0.320 | 0.402 | 0.186 | 0.260 | 0.263 | 0.307 | 0.262 | 0.304 | |
| 2.790 | 1.410 | 1.420 | 0.734 | 0.752 | 0.768 | 0.537 | 0.472 | 0.463 |
Таблица 1.2.
Коэффициенты ускорения выполнения вычислений
| N2 | Коэффициенты ускорения ((1,1)/(X,X)) | ||||||||
| (1,1) | (1,2) | (2,1) | (1,4) | (2,2) | (4,1) | (2,4) | (4,2) | (8,1) | |
| 0.246 | 0.048 | 0.130 | 0.044 | 0.037 | 0.020 | 0.018 | 0.016 | ||
| 1.111 | 0.349 | 0.913 | 0.342 | 0.313 | 0.170 | 0.157 | 0.135 | ||
| 1.652 | 0.875 | 2.098 | 1.034 | 1.005 | 0.609 | 0.591 | 0.508 | ||
| 1.879 | 1.497 | 3.239 | 2.317 | 2.290 | 1.961 | 2.299 | 1.982 | ||
| 1.978 | 1.965 | 3.801 | 3.710 | 3.633 | 5.192 | 5.911 | 6.026 |
Как можно заметить, на коэффициент ускорения выполнения вычислений значительно влияет не только размерность массивов и число запущенных процессов, но и характер распределения процессов по узлам кластера.
По данным из табл. 1.2, для каждого рассмотренного значения набора N1 и N2, можно построить графики зависимости наибольшего коэффициента ускорения от числа запущенных процессов (см. рис. 1.1).
Домашняя подготовка.
1. Ознакомьтесь с программным интерфейсом передачи сообщений стандарта MPI [1] и правилами построения программ, использующих этот интерфейс.
2. Изучите разделы методических указаний, посвященные организации двухточечных передач средствами MPI. В частности необходимо изучить использование функций MPI_Send и MPI_Recv (синтаксис этих и других функций смотрите в Приложении и в [1]).

3. Ознакомьтесь (по указанию преподавателя) со структурами вычислительных систем, на которых будут ставиться эксперименты с программой. Изучите процедуры подготовки и выполнения параллельных программ на этих системах.
4. Познакомьтесь со своим вариантом задания на лабораторную работу (см. табл. 1.3 с. 13).
5. Перед началом экспериментов согласовать с преподавателем начальное значение размерностей массивов (по умолчанию массивы одномерные)
6. Напишите на языке C последовательную программу, реализующую вычисления согласно варианту лабораторного задания для размеров массивов (8,64,256,1024,4096).
7. На основании созданной последовательной программы, путем включения в нее функций MPI, создать параллельную программу для выполнения вычислений двумя процессами в модели SPMD.
8. Сделайте заготовку протокола выполнения лабораторной работы с таблицами, куда будут заноситься условия и результаты проведенных экспериментов.
Лабораторное задание
1. Необходимо отладить программы пп. 6 и 7 домашней подготовки (табл. 1.3) и получить экспериментальные подтверждения их работоспособности и функциональной эквивалентности.
2. Переработайте параллельную программу таким образом, чтобы она могла быть выполнена по возможности любым числом процессов, включая один.
3. Проверьте функциональную адекватность параллельной программы (т.е. то, что она выдает одинаковый результат, при одинаковых входных данных в любых вариантах исполнения).
4. Вставьте в программу функции определения времени (MPI_Wtime) и использовать их для замера начального и конечного времени эксперимента.
5. Выполните на экспериментальной вычислительной системе программу одним процессом. Результирующее время вычислений занести в таблицу протокола. Если время вычислений слишком мало (менее 10 миллисекунд) то между начальным и конечным замерами времени можно вставить цикл кратности (например: 10000 раз) для многократного повторения эксперимента.
6. Выполните на экспериментальной вычислительной системе программу поочередно двумя, четырьмя и более процессами, времена выполнения занести в таблицу протокола. Выполняя процессы программы на вычислительной системе, необходимо позаботиться, чтобы каждый процесс выполнялся на своем выделенном процессоре (или процессорном яре) если это не делается автоматически.
7. Если в системе имеется возможность указывать распределение процессов по процессорам (по ядрам), то дополнительно можно поставить эксперименты с разным распределением процессов (например: все процессы на процессорах одного вычислительного узла или на процессорах разных узлов).
8. Изменяя размер массивов (8, 64, 256, 1024, 4096) повторить для каждого размера эксперименты с п. 5 по п. 7.
9. Для каждого из поставленных экспериментов рассчитать коэффициент ускорения, поделив время выполнения программы одним процессом (для каждого размера массива) на время выполнения программы несколькими процессами.
Таблица 1.3
Варианты задания (операции с каждый i-м элементом)
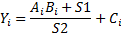
| 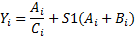
| ||
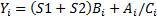
| 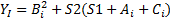
| ||
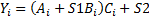
| 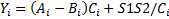
| ||

| 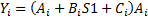
| ||

| 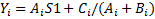
|
Примечания: A,B,C и Y – массивы: S1 и S2 - скаляры
10. Если коэффициент ускорения получился около или меньше единицы, можно часть исходных данных (некоторые массивы) инициализировать во всех процессах (а не передавать из нулевого) и повторить эксперименты с п. 6.
11. В случае, если в ходе постановки экспериментов так и не удалось получить ускорений вычислений, то необходимо выявить и ликвидировать «узкие места» или ошибки в структуре программы.
12. При наличии второй экспериментальной вычислительной системы, проделать на ней те же эксперименты с пп. 5 по 9. Результаты, полученные на разных системах сравнить.
13. На основе таблиц результатов проведенных экспериментов постройте графики, подготовить отчет о работе.
Контрольные вопросы
1. Что такое MPI?
2. Что такое модель SPMD, как взаимодействуют процессы в такой модели?
3. Какова структура MPI-программы?
4. Что такое двухточечные передачи данных в MPI, как и какими средствами их организуют?
5. Какие коэффициенты ускорения у вас получились и почему?
6. Каким образом коэффициент ускорения зависит от размера массивов и почему?
7. Что вы сделали в программе, чтобы увеличить коэффициенты ускорения?
8. Какие варианты выполнения (среди использованных вами) вашей программы на вычислительной системе для каждого значения N вы считаете лучшим и почему?
|
|
|
