 |


Проектирование многотабличной базы данных
|
|
|
|
Рассмотрим на конкретном примере методику проектирования многотабличной базы данных. Для этого снова вернемся к задаче моделирования работы с информацией, выполняемой приемной комиссией при поступлении абитуриентов в университет (см. "Пример структурной модели предметной области").
Табличная форма модели данных
В §3 "Пример структурной модели предметной области" была построена модель данных, состоящая из трех взаимосвязанных таблиц. Воспроизведем ее еще раз.

Эти три таблицы можно рассматривать как модель данных в реляционной СУБД. Но работать с БД в таком виде неудобно. Помимо того что реляционная БД должна состоять из таблиц, к ней предъявляется еще ряд требований.
Одним из главных требований является требование отсутствия избыточности (или минимизация избыточности) данных. Избыточность приводит к лишнему расходу памяти. Память нужно экономить. Это не только увеличивает информационную плотность базы данных, но и сокращает время поиска и обработки данных.
Очевидный недостаток описанных таблиц — многократное повторение длинных значений полей в разных записях. Например, название специальности «Радиофизика и электроника» будет повторяться в 100 записях для 100 абитуриентов, которые на нее поступают. Проще сделать так. В таблице СПЕЦИАЛЬНОСТИ для каждой специальности ввести свой короткий код. Тогда полное название запишется в БД только один раз, а в анкетах абитуриентов будет указываться только код. Точно так же можно закодировать названия факультетов.
Внесем изменения в таблицы ФАКУЛЬТЕТЫ и СПЕЦИАЛЬНОСТИ.
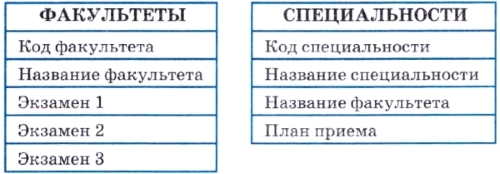
Здесь предполагаются два упрощающих допущения: пусть на разных специальностях одного факультета сдаются одни и те же экзамены, а число экзаменов на всех факультетах равно трем (это вполне разумно).
|
|
|
Очень неудобной для работы является таблица АБИТУРИЕНТЫ. В ней слишком много полей. В частности, такую таблицу неудобно будет просматривать на экране, легко запутаться в полях. Поступим следующим образом. Разделим «большую» таблицу АБИТУРИЕНТЫ на четыре таблицы поменьше:
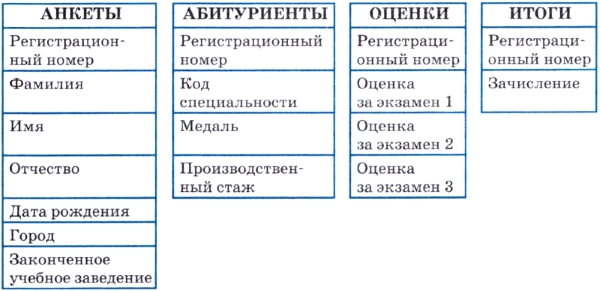
С такими таблицами работать гораздо проще. На разных этапах работы приемной комиссии каждая из этих таблиц будет иметь самостоятельное значение.
Таблица АНКЕТЫ содержит анкетные данные, не влияющие на зачисление абитуриента в вуз. В таблице АБИТУРИЕНТЫ содержатся сведения, определяющие, куда поступает абитуриент, а также данные, которые могут повлиять на его зачисление (предположим, что это может быть производственный стаж и наличие медали). Таблица ОЦЕНКИ — это ведомость, которая будет заполняться для всех абитуриентов в процессе приема экзаменов. Таблица ИТОГИ будет содержать результаты зачисления всех абитуриентов.
Схема базы данных
Для явного указания связей между таблицами должна быть построена схема базы данных. В схеме указывается наличие связей между таблицами и типы связей. Схема для нашей системы представлена на рис. 1.11.
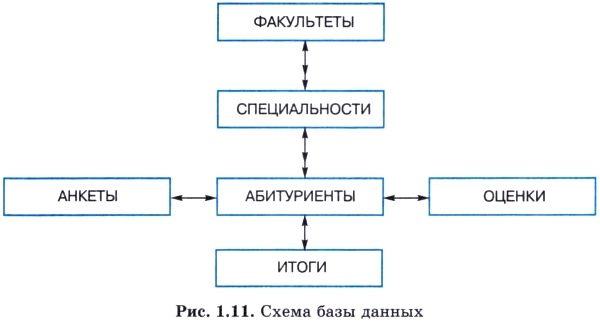
В схеме использованы два типа связей: один к одному и один ко многим. Первый обозначен двунаправленной одинарной стрелкой, второй — одинарной стрелкой в одну сторону и двойной в другую. При связи «один к одному» с одной записью в таблице связана одна запись в другой таблице. Например, одна запись об абитуриенте связана с одним списком оценок. При наличии связи «один ко многим» одна запись в некоторой таблице связана с множеством записей в другой таблице. Например, с одним факультетом связано множество специальностей, а с одной специальностью — множество абитуриентов, поступающих на эту специальность.
|
|
|
Связь «один ко многим» — это связь между двумя соседними уровнями иерархической структуры. А таблицы, связанные отношениями «один к одному», находятся на одном уровне иерархии. В принципе все они могут быть объединены в одну таблицу, поскольку главный ключ у них один — РЕГ_НОМ. Но чем это неудобно, было объяснено выше.
|
|
|
