 |


Обзор существующих методов
|
|
|
|
Авторы работ в области классификации людей по фотографии лица обычно концентрируются на определении какого-либо одного атрибута: пола, возраста или эмоционального состояния. Детали алгоритмов классификации различных атрибутов отличаются, но можно выделить основные три этапа, которым следует большинство разработчиков методов:
· Предобработка фотографий
· Вычисление признаков
· Применение алгоритма машинного обучения
Далее каждый из этапов будет рассмотрен более подробно.
Предобработка фотографий
На вход алгоритмам классификации людей подаются фотографии, которые могут сильно отличаться друг от друга по разрешению, освещенности, положению лица на фотографии, поэтому возникает необходимость привести их к общему, нормализованному виду. Для этого требуются дополнительные входные данные, позволяющие локализовать лицо на фотографии. Такими данными могут быть координаты прямоугольника, ограничивающего лицо, найденные с помощью детектора лиц, или координаты особых точек на лице, например, зрачков. На основании этих координат лица на фотографиях с помощью поворотов и сдвигов приводятся к одному положению. В некоторых методах применяются более сложные геометрические преобразования, призванные компенсировать небольшие отклонения лица от фронтального положения. Затем фотографии масштабируются, и из них вырезается прямоугольник, содержащий область лица. Некоторые алгоритмы также используют соседние регионы: прическу, шею, область декольте. После геометрических преобразований опционально выполняется выравнивание освещенности, удаление шума.
На выходе этапа предобработки получаются нормализованные изображения лиц одинакового размера. Этот размер зависит от дальнейших этапов алгоритма и может варьироваться от 20×20 до 110×150 пикселей.
|
|
|
Признаки
Существует большое количество типов признаков, используемых в алгоритмах классификации людей по лицу, но их можно разделить на несколько групп.
Первая группа – антропометрические признаки, предложенные в самых ранних работах по данной тематике, например, в [2]. Они основаны на простых наблюдениях, позволяющих людям правильно классифицировать тот или иной атрибут. Например, для определения возраста такими признаками служат пропорции лица, которые отличаются у детей и взрослых, а также морщины, количество которых увеличивается с возрастом. Признаки такого типа не универсальны, то есть для классификации каждого атрибута нужен свой набор признаков.
Следующий тип признаков, применявшийся в работах [3],[4] – параметры статистической модели внешнего вида [5]. Для построения модели необходим набор фотографий лиц, на которых отмечены положения нескольких десятков особых точек. В процессе обучения метод главных компонент применяется к отклонениям внешнего вида каждого лица от усредненного. В результате каждое лицо описывается вектором параметров, количество которых можно регулировать в зависимости от условий задачи. Статистическая модель сопоставляет каждому лицу относительно небольшое число параметров, что удобно для дальнейшего применения в алгоритмах машинного обучения, но для своего построения требует точной разметки множества особых точек на лице, что является трудоемкой задачей.
Еще один тип признаков – значения интенсивности пикселей изображения. Его основное преимущество – простота вычисления, так как значения можно брать непосредственно из нормализованного изображения. Обычно к этим признакам дополнительно применяется один из методов понижения размерности (метод главных компонент в [6] или дискриминантный анализ в [7]). Вместо значений интенсивностей пикселей признаками могут быть результаты сравнения этих значений между собой для пар пикселей, что было предложено авторами работы [8]. Такая модификация более устойчива к изменениям освещенности на изображениях.
|
|
|
Последняя из рассматриваемых в этом обзоре групп признаков – сложные признаки, описывающие текстуру и распределение градиентов яркости на фотографии. К этой группе относятся, например, LBP (Local Binary Patterns) [9] и BIF (Biologically Inspired Features) [10]. LBP-признаки вычисляются путем применения LBP-оператора к каждому пикселю изображения. Оператор работает следующим образом: значение интенсивности в пикселе сравнивается со значениями во всех соседних пикселях из окрестности 3×3, и результаты сравнения представляются в виде нулей (если значение в центральном пикселе больше значения в соседнем) и единиц (в противном случае). Получается 8 цифр, из которых составляется двоичный вектор, который интерпретируется как двоичная запись целого числа. Это число и является результатом применения оператора к пикселю. Итоговые признаки получаются после разделения всего изображения решеткой на прямоугольные области, подсчета гистограмм результатов применения LBP-оператора и конкатенации полученных гистограмм в один вектор. Процесс вычисления LBP-признаков показан на рисунке 1.
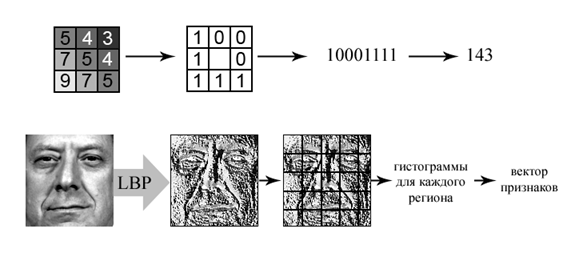
Рисунок 1. Вычисление LBP-признаков: вверху – для одного пикселя, внизу – для целого изображения.
Эти признаки толерантны к неравномерностям в освещении и небольшим сдвигам в положении лица за счет того, что подсчет ведется не индивидуально для каждого пикселя, а используются регионы значительного размера.
Методы обучения
С точки зрения методов машинного обучения, все атрибуты человека можно разделить на три типа согласно количеству возможных значений:
· Бинарные (пол, наличие очков, усов или бороды)
· Многоклассовые (возрастная группа, выражение лица)
· Непрерывные (возраст)
Для классификации бинарных признаков наиболее часто используются бустинг (например, в [8], [11]) и метод опорных векторов (в работах [3], [9]). Многоклассовая классификация осуществляется путем сведения к нескольким задачам классификации на два класса методами «один против всех» или «каждый с каждым»[12], а затем выбора итогового класса методом голосования. Рандомизированные решающие деревья (Random Forest [13]) позволяют проводить многоклассовую классификацию непосредственно, без разделения на бинарные подзадачи. Для определения возраста, являющегося непрерывным упорядоченным атрибутом, лучше всего подходят методы регрессии. Это может быть как линейная регрессия, так и регрессия, основанная на методе опорных векторов или решающих деревьях.
|
|
|
Было подмечено [7], что возрастные изменения зависят от пола, поэтому возраст обычно определяют отдельно для мужчин и женщин, предварительно разделяя выборку вручную или автоматически. Даже автоматическое разделение, произведенное с некоторой ошибкой, позволяет улучшить результаты определения возраста.
Выводы
Рассмотренные выше методы в той или иной степени успешно справляются с поставленной перед ними задачей, но большинство из них не учитывает взаимосвязи между различными атрибутами человека, влияния их друг на друга. В то же время, учет взаимосвязей путем предварительного разделения обучающей выборки на части может ухудшать итоговые результаты, так уменьшение объема выборки негативно влияет на методы машинного обучения.
Предложенный метод
Как было замечено выше, различные атрибуты человека влияют друг на друга. Возрастные изменения у мужчин и женщин проявляются немного по-разному, пожилые люди чаще носят очки, чем молодые, усы и бороды бывают только у мужчин. Существуют и другие зависимости, которые хуже поддаются явному описанию. В данной работе предлагается метод, позволяющий алгоритму автоматически учитывать эти зависимости и производить одновременную классификацию всех атрибутов. В отличие от последовательной классификации, когда обучающая выборка делится сначала по признаку пола, а потом уже определяется возраст, предложенный алгоритм сам выбирает, в какой момент по какому признаку выгоднее всего производить классификацию.
|
|
|
Общая схема предложенного алгоритма, так же как у большинства алгоритмов классификации по лицу, состоит из трех этапов – предобработка, вычисление признаков, применение машинного обучения. Рассмотрим каждый из этапов более подробно.
Предобработка фотографий
На вход алгоритму подаются фотография лица человека и координаты зрачков глаз на ней. Задача этапа предобработки – преобразовать эту фотографию к нормализованному виду. Под нормализованным видом здесь понимается изображение в градациях серого размера 60×60 пикселей, координаты зрачков – (15, 15) и (30, 15). Для приведения к такому виду исходную фотографию необходимо повернуть, масштабировать и обрезать до нужного размера. Эти преобразования представлены на рисунке 2. Затем производится выравнивание гистограммы для улучшения контраста на изображении.

Рисунок 2. Преобразования фотографии на стадии предобработки
BIF
BIF (biologically inspired features) моделируют процессы, происходящие в коре головного мозга при распознавании объектов, представляя изображение в виде иерархии последовательно усложняющих представлений. В предложенном алгоритме использована версия этих признаков, описанная в статье [10], где с их помощью определялся возраст. Выбор BIF-признаков обусловлен тем, что именно с их помощью на настоящий момент достигнуты наилучшие результаты в классификации возраста и пола [7], [10].

Рисунок 3. Вычисление BIF-признаков
Исходное изображение размера 60×60 пикселей подвергается свертке с фильтрами Габора 16-ти масштабов (от 5×5 до 35×35) и четырех ориентаций. Получается 64 изображения. Для улучшения инвариантности к масштабу каждая пара изображений, являющаяся выходом фильтров двух соседних размеров, объединяется в одно изображение с помощью операции MAX (взятие максимума). После этого получаются 32 изображения, к которым применяется операция STD. Эта операция представляет собой вычисление стандартного отклонения интенсивностей пикселей в пределах квадратного окна, размер которого зависит от масштаба фильтра. Окна берутся так, чтобы они покрывали все изображение и перекрывались между собой на ½ размера по горизонтали и вертикали. Результаты применения операции STD объединяются в вектор признаков, размерность которого для одной фотографии – около 3700. На рисунке 3 проиллюстрированы этапы вычисления признаков для одного из масштабов фильтров.
|
|
|
