 |


Структура векторного процессора
|
|
|
|
Обобщенная структура векторного процессора приведена на рис. 7.6. На схеме показаны основные узлы процессора, без детализации некоторых связей между ними.




Рис. 7.6. Упрощенная структура векторного процессора
Обработка всех n компонентов векторов-операндов задается одной век- торной командой. Элементы векторов представляются числами в форме с пла-вающей запятой (ПЗ). АЛУ векторного процессора может быть реализовано в виде единого конвейерного устройства, способного выполнять все предусмот-ренные операции над числами с ПЗ. Однако более распространена иная струк-тура, в которой АЛУ состоит из отдельных блоков сложения и умножения, а иногда и блока для вычисления обратной величины, когда операция деления  реализуется в виде
реализуется в виде 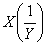 . Каждый из таких блоков также конвейеризирован. Кроме того, в состав векторной вычислительной системы обычно включается и скалярный процессор, что позволяет параллельно выполнять векторные и скалярные команды.
. Каждый из таких блоков также конвейеризирован. Кроме того, в состав векторной вычислительной системы обычно включается и скалярный процессор, что позволяет параллельно выполнять векторные и скалярные команды.
Для хранения векторов-операндов вместо множества скалярных регист- ров используются векторные регистры, представляющие собой совокупность скалярных регистров, объединенных в очередь типа FIFO, способную хранить 50–100 чисел с плавающей запятой. Набор векторных регистров (Va, Vb, Vc,…) имеется в любом векторном процессоре. Система команд векторного процес- сора поддерживает работу с векторными регистрами и обязательно включает в себя команды:
§ загрузки векторного регистра содержимым последовательных ячеек па- мяти, указанных адресом первой ячейки этой последовательности;
§ выполнения операций над всеми элементами векторов, находящихся в векторных регистрах;
§ сохранения содержимого векторного регистра в последовательности ячеек памяти, указанных адресом первой ячейки этой последовательности.
|
|
|
Примером одной из наиболее распространенных операций, возлагаемых на векторный процессор, может служить операция перемножения матриц. Рас-смотрим перемножение двух матриц А и В размерности 3×3.

Элементы матрицы результата С связаны с соответствующими элемента- ми исходных матриц A и B операцией скалярного произведения:
 .
.
Так, элемент с 11 вычисляется как
с 11 = a 11 × b 11 + a 12 × b 21 + a 13 × b 31.
Это требует трех операций умножения и после инициализации с 11 нулем – трех операций сложения. Общее число умножений и сложений для рассмат-риваемого примера составляет 9×3=27. Если рассматривать связанные операции умножения и сложения как одну кумулятивную операцию с + a × b, то для умно-жения двух матриц n × n необходимо n3 операций типа «умножение-сложение». Вся процедура сводится к получению n 2 скалярных произведений, каждое из которых является итогом n операций «умножение-сложение», учитывая, что пе-ред вычислением каждого элемента сij его необходимо обнулить. Таким образом, скалярное произведение состоит из k членов:
С = А 1 В 1+ А 2 В 2 + А 3 В 3 + A 4 B 4 + … + A k B k.
Векторный процессор с конвейеризированными блоками обработки для вычисления скалярного произведения показан на рис. 7.7.
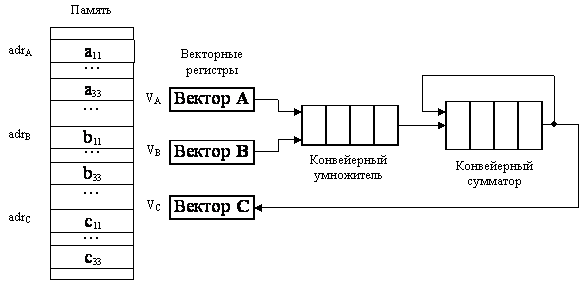
Рис. 7.7. Векторный процессор для вычисления скалярного произведения
Векторы А и В, хранящиеся в памяти начиная с адресов adrA и adrB, за-гружаются в векторные регистры VA и VB соответственно. Предполагается, что конвейерные умножитель и сумматор состоят из четырех сегментов, которые вначале инициализируются нулем, поэтому в течение первых восьми циклов, пока оба конвейера не заполнятся, на выходе сумматора будет 0. Пары (A i, B i) подаются на вход умножителя и перемножаются в темпе одна пара за цикл. После первых четырех циклов произведения начинают суммироваться с дан- ными, поступающими с выхода сумматора. В течение следующих четырех цик-лов на вход сумматора поступают суммы произведений из умножителя с нулем. К концу восьмого цикла в сегментах сумматора находятся четыре первых про-изведения A 1 B 1, …, A 4 B 4, а в сегментах умножителя – следующие четыре про- изведения: A 5 B 5, …, A 8 B 8. К началу девятого цикла на выходе сумматора будет A 1 B 1, а на выходе умножителя – А 5 В 5. Таким образом, девятый цикл начнется со сложения в сумматоре А 1 В 1 и А 5 В 5. Десятый цикл начнется со сложения A 2 B 2 + A 6 B 6 и т.д. Процесс суммирования в четырех секциях выглядит так:
|
|
|
C = A 1 B 1 + A 5 B 5 + A 9 B 9 + A 13 B 13 + …
+ A 2 B 2 + A 6 B 6 + A 10 B 10 + A 14 B 14 + …
+ A 3 B 3 + A 7 B 7 + A 11 B 11 + A 15 B 15 + …
+ A 4 B 4 + A 8 B 8 + A 12 B 12 + A 16 B 16 + …
Когда больше не остается членов для сложения, система заносит в умно-житель четыре нуля. При этом в четырех сегментах конвейера сумматора со-держатся четыре скалярных произведения, соответствующие четырем суммам, приведенным в четырех строках показанного выше уравнения. Далее четыре частичных суммы складываются для получения окончательного результата.
Программа для вычисления скалярного произведения векторов А и В, хра-нящихся в областях памяти с начальными адресами adrA и adrB, имеет вид:
V_load VA, adrA
V_load VB, adrB
V_multiply VC, VA, VB
Первые две векторные команды V_load загружают векторы из памяти в векторные регистры VA и VB. Векторная команда умножения V_multiply вычисляет произведение для всех пар одноименных элементов векторов и записывает полученный вектор в векторный регистр VC.
Важным элементом векторного процессора (ВП) является регистр длины вектора. Этот регистр определяет, сколько элементов фактически содержит об-рабатываемый в данный момент вектор, то есть сколько индивидуальных опе-раций с элементами нужно сделать. В некоторых ВП присутствует также ре- гистр максимальной длины вектора, определяющий максимальное число эле-ментов вектора, которое может быть одновременно обработано аппаратурой процессора. Этот регистр используется при разделении очень длинных векторов на сегменты, длина которых соответствует максимальному числу элементов, обрабатываемых аппаратурой за один прием.
Часто приходится выполнять такие операции, в которых участвуют не все элементы векторов. Векторный процессор обеспечивает данный режим с помо-щью регистра маски вектора. В этом регистре каждому элементу вектора со-ответствует один бит. Установка бита в единицу разрешает запись соответст-вующего элемента вектора результата в выходной векторный регистр, а сброс в ноль – запрещает.
|
|
|
Элементы векторов в памяти расположены регулярно и при выполнении векторных операций достаточно указать значение шага по индексу. Существу- ют случаи, когда необходимо обрабатывать только ненулевые элементы век- торов. Для поддержки подобных операций в системе команд ВП предусмот- рены операции упаковки/распаковки (gather/scatter). Операция упаковки форми-рует вектор, содержащий только ненулевые элементы исходного вектора, а опе-рация распаковки производит обратное преобразование. Обе этих задачи век-торный процессор решает с помощью вектора индексов, для хранения кото- рого используется регистр вектора индексов, по структуре аналогичный ре-гистру маски. В векторе индексов каждому элементу исходного вектора со-ответствует один бит. Нулевое значение бита свидетельствует, что соответст-вующий элемент исходного вектора равен нулю.
Применение векторных команд окупается по двум причинам. Во-первых, вместо многократной выборки одних и тех же команд достаточно произвести выборку только одной векторной команды, что позволяет сократить издержки за счет устройства управления и уменьшить требования к пропускной способ-ности памяти. Во-вторых, векторная команда обеспечивает процессор упорядо-ченными данными. Когда инициируется векторная команда, ВС знает, что ей нужно извлечь n пар операндов, расположенных в памяти регулярным образом. Таким образом, процессор может указать памяти на необходимость начать изв-лечение таких пар. Если используется память с чередованием адресов, эти пары могут быть получены со скоростью одной пары за цикл процессора и направ- лены для обработки в конвейеризированный функциональный блок. При отсут-ствии чередования адресов или других средств извлечения операндов с высо- кой скоростью преимущества обработки векторов существенно снижаются.
|
|
|
4. Структуры типа “память-память” и “регистр-регистр”
Принципиальное различие архитектур векторных процессоров проявля- ется в том, каким образом осуществляется доступ к операндам. При организа- ции «память-память» элементы векторов поочередно извлекаются из памяти и сразу же направляются в функциональный блок. По мере обработки полу- чающиеся элементы вектора результата сразу же заносятся в память. В архи-тектуре типа «регистр-регистр» операнды сначала загружаются в векторные регистры, каждый из которых может хранить сегмент вектора (например 64 элемента). Векторная операция реализуется путем извлечения операндов из векторных регистров и занесения результата в векторный регистр.
Преимущество ВП с режимом «память-память» состоит в возможности обработки длинных векторов, в то время как в процессорах типа «регистр-регистр» приходится разбивать длинные векторы на сегменты фиксированной длины. К сожалению, за гибкость режима «память-память» приходится рас- плачиваться относительно большим временем запуска, представляющим собой временной интервал между инициализацией команды и моментом, когда пер- вый результат появится на выходе конвейера. Большое время запуска в про-цессорах типа «память-память» обусловлено скоростью доступа к памяти, кото-рая намного меньше скорости доступа к внутреннему регистру. Однако когда конвейер заполнен, результат формируется в каждом цикле. Модель времени работы векторного процессора имеет вид:
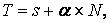
где s – время запуска, α – константа, зависящая от команды (обычно 1/2, 1 или 2) и N – длина вектора.
Архитектура типа «память-память» реализована в векторно-конвейерных ВС Advanced Scientific Computer фирмы Texas Instruments Inc., семействе вы-числительных систем фирмы Control Data Corporation, прежде всего, Star 100, серии Cyber 200 и ВС типа ETA-10. Все эти вычислительные системы появи- лись в середине 70-х прошлого века после длительного цикла разработки, но к середине 80-х годов от них отказались. Причиной послужило слишком большое время запуска – порядка 100 циклов процессора. Это означает, что операции с короткими векторами выполняются очень неэффективно, и даже при длине векторов в 100 элементов процессор достигал только половины потенциальной производительности.
В вычислительных системах типа «регистр-регистр» векторы имеют срав-нительно небольшую длину (в ВС семейства Cray – 64), но время запуска зна-чительно меньше, чем в случае “память-память». Этот тип векторных систем гораздо более эффективен при обработке коротких векторов, но при операциях над длинными векторами векторные регистры должны загружаться сегментами несколько раз. В настоящее время ВП типа «регистр-регистр» доминируют на компьютерном рынке. Это вычислительные системы фирмы Cray Research Inc., в частности модели Y-MP и C-90. Аналогичный подход заложен в ВС фирм Fujitsu, Hitachi и NEC. Время цикла в современных ВП варьируется от 2,5 нс (NEC SX-3) до 4,2 нс (Cray C-90), а производительность, измеренная по тесту LINPACK, лежит в диапазоне от 1000 до 2000 MFLOPS (от 1 до 2 GFLOPS).
|
|
|
|
|
|
