 |


Trim-функции (функции удаления пробельных символов)
|
|
|
|
| trim() | ltrim() | rtrim() | chop() |
Это очень полезная группа функций, без которых сложно обойтись при работе со строками. К пробельным символам относятся символы "\n", "\r", "\t", "\v", "\0" и собственно пробел. Особенно часто мы с этими функциями будем работать при изучении файлового ввода-вывода.
Trim()
Эта функция принимает в качестве своего единственного аргумента строку, и удаляет из нее пробелы слева и справа.
Пример:
<? $string = trim (" Hello, world! "); ?>Давайте для того, чтобы убедиться, что эта функция нас не обманывает, выведем ее длину до и после удаления из нее пробелов. Напишем вот такой простенький скриптик:
<? $str = " Hello, world! "; $str1 = trim(" Hello, world! "); $str_len = strlen($str); $str1_len = strlen($str1); echo( " размер исходной строки '$str' = $str_len, < br > размер строки после удаления пробелов = $str1_len " ); ?>И вот результат, доказывающий, что функция ведет себя вполне прилично:
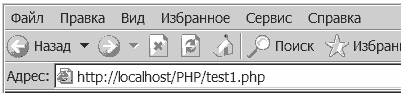
| Размер исходной строки 'Hello, world!' = 19, размер строки поле удаления пробелов = 13 |
Ltrim(), rtrim() и chop()
Функция ltrim() удаляет из строки начальные пробельные символы (т.е., те которые слева); rtrim() – конечные пробельные символы. Функция chop () является синонимом функции rtrim ().
Функции форматного вывода. Спецификаторы преобразования
| printf() | sprintf() | sscanf() |
Printf() и sprintf()
Синтаксис:
int printf ( string format [, mixed args ] ) string sprintf ( string format [, mixed args ] )Об этих функциях мы поговорим несколько подробнее, чем о предыдущих функциях работы со строками, нами рассмотренных. Сразу скажем, что эти две функции предназначены для форматного вывода и что отличаются они тем, что функция printf () производит форматирование и выводит результаты в выходной поток (браузер или консоль), а sprintf () после осуществления требуемого форматирования просто возвращает строку.
|
|
|
С одной стороны этими функциями можно пользоваться просто как функциями вывода:
<? printf ( "Hello!" ); // выводит "Hello!" sprintf ( "Hello!" ); // сама по себе ничего не выводит, $str = sprintf ( "Hello!" ); // а просто возвращает строку, printf ( $str ); // которую затем можно вывести в выходной поток ?>Но использовать их только так, как мы сейчас продемонстрировали – простое расточительство, так как эти функции способны на большее. Дело в том, что аргумент format этих функций представляет собой строку, содержащую специальные символы, использующиеся при форматировании данных, содержащихся в списке аргументов. Эти спецсимволы называются спецификаторами преобразования, а символы, которые остаются неизменными при форматировании строки, называют директивами.
Спецификация определяется символом " % ", за которым может следовать до пяти спецификаторов в следующем порядке:
1. Спецификатор заполнения
Устанавливает символ, которым строка заполняется до заданного размера. По умолчанию используется пробел. Спецификатор заполнения действует только при наличии спецификатора минимальной ширины
2. Спецификатор выравнивания
По умолчанию дополнение строки до минимальной ширины производится с левого края (т.е., строка выравнивается по правому краю). Если добавлен символ дефиса, то строка выравнивается по левому краю
3. Спецификатор минимальной ширины
Представляет собой целое число, задающее минимальный размер форматированной строки. Если переданная строка меньше, то она дополняется символами, указанными в спецификаторе заполнения
4. Спецификатор точности
Предназначен для указания количества десятичных знаков в представлении чисел с плавающей точкой. При применении этого спецификатора для форматирования строк, он определяет максимальное количество символов, которое нужно взять из переданной строки
|
|
|
5. спецификатор типа
Этот спецификатор предназначен для указания типа данных, которые переданы в качестве аргумента. Спецификатор может принимать одно из следующих значений:
o b – целое число, представляемое в двоичном виде;
o с – целое число, представляемое в виде символа с тем же ASCII кодом;
o d – целое число, представляемое в десятичном виде;
o f – число с плавающей точкой, представляемое в виде десятичной дроби;
o o – целое число, представляемое в восьмеричном виде;
o s – строка;
o x – целое число, представляемое в шестнадцатеричном виде в нижнем регистре;
o X – целое число, представляемое в шестнадцатеричном виде в верзнем регистре
Теперь, после разговора о спецификаторах типа, выведем с помощью функции printf() строку в формате даты dd/mm/yyyy. Следующий код выводит в результате строку " 02/03/2003 ":
<? $day = 2; $month = 3; $year = 2003; printf ("%02d/%02d/%04d", $day, $month, $year); ?>Результат:
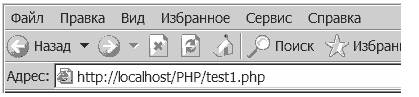
| 02/03/2003 |
В этом примере, месяц и день мы форматируем как двузначные числа, а год – как четырехзначное. При этом мы указываем, что целые числа дополняются до минимальной длины нулями слева: %04d
Первый символ – спецификатор заполнения и он равен нулю. Так как дополнение дописывается к началу числа, спецификатор выравнивания отсутствует. Спецификатор минимальной ширины равен двум. Спецификатор точности также отсутствует, так как мы форматируем целое число. Спецификатор типа представлен символом d, так как мы форматируем число как десятичное целое.
Приведем еще один пример.
<? $value = 19; printf ("%.3f", $value); ?>Этот скрипт выводит число 19 в виде 19.000
Еще одна форматная функция
функция sscanf()
Синтаксис:
mixed sscanf ( string str, string format [, string var1...] )Эта функция является полной противоположностью функции printf(). Она интерпретирует строку str согласно формату format, аналогично спецификации printf(). При указании только двух аргументов полученные значения возвращаются как массив.
Давайте рассмотрим такой пример. Пусть у нас есть строка, в которой находится информация о названии и серийном номере изделия в виде "maxtor/203-5505" и нам надо вытащить из нее серийный номер. Пишем вот такой скриптик:
<? $product = "maxtor/203-5505"; $str = sscanf($product,"maxtor/%3d-%4d"); echo ( " $str [0]- $str [1]" ); ?>Результат:
|
|
|
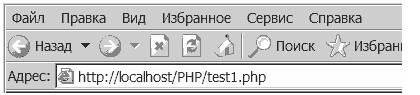
| 203-5505 |
Не забывайте, что если не указываете в функции необязательные аргументы, то на выходе получите массив, и поэтому при выводе мы работаем со значениями массива.
Давайте поработаем еще с датой изготовления этого изделия, которая нам явилась в виде " august 10 2003 ", а нам надо чтоб она выводилась в виде " 10 aug 2003 ". Работаем.
<? $date = " august 10 2003 "; list ( $month, $day, $year ) = sscanf($date, "%s %d %d" ); echo ( "Date: $day -". substr ( $month,0,3)."- $year " ); ?>Результат:

| Date: 10-aug-2003 |
Важное замечание: при указании необязательных параметров их надо передавать по ссылке (ссылка обозначается указанием символа " & " перед переменной).
Пример, в котором используются дополнительные необязательные параметры:
<? $book = "1\tThinking in PHP"; $str = sscanf ( $book,"%d\t%s %s %s", & $id, & $first, & $second, & $last ); echo ( "book number $id - $first $second $last " ); ?>Результат:
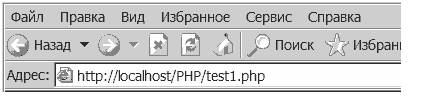
book number 1 - Thinking in PHP>
Функции преобразования кодировки
| convert_cyr_string() | bin2hex() |
Convert_cyr_string()
Синтаксис:
string convert_cyr_string ( string str, string from, string to )Функция преобразует строку из одной кодировки кириллицы в другую. Она переводит строку str из кодировки from в кодировку to. Значения from и to это одиночные символы, определяющий кодировку:
· k - koi8-r;
· w - windows-1251;
· i - iso8859-5;
· a - x-cp866;
· d - x-cp866;
· m - x-mac-cyrillic;
Давайте для примера перекодируем слово "определяющий" из кодировки windows-1251 в koi8-r и обратно:
<? $str1 = "определяющий"; $str2 = convert_cyr_string ( $str1,"w","k" ); echo ( "result of translate '$str1' to koi8-r is '$str2'" ); echo ( "< br >" ); $str3 = convert_cyr_string ( $str2,"k","w" ); echo ( "result of translate ' $str2 ' to win is ' $str3 '" ); ?>И вот результат:

Bin2hex()
Производит побайтовое преобразование символьных данных в шестнадцатеричный вид.
Функция bin2hex() принимает в качестве единственного параметра строку и возвращает строковое шестнадцатеричное представление символов, содержащихся в этой строке.
Для примера давайте перекодируем тоже самое слово "определяющий":
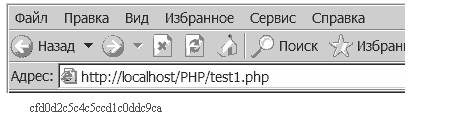
<? $str1 = "определяющий"; $str2 = bin2hex ( $str1 ); echo( $str2 ); ?>И вот какая абракадабра из этого получилась:
|
|
|
Результат:
Функции работы с бинарными данными
| pack() | unpack() |
Собственно, таких функций две – pack() и unpack(). Первая осуществляет пакетирование данных в двоичную строку, а вторая – распаковывает данные из двоичной строки. Лично у меня пока не было необходимости пользоваться этими функциями, кроме как при подготовке примеров их использования для этой главы. Но кто знает, может быть кому-то они очень нужны, поэтому мы с ними чуть-чуть повозимся.
Итак, функция:
Pack()
Синтаксис:
string pack ( string format [,mixed $args,...] )Функция pack() упаковывает заданные в ее параметре аргументы в бинарную строку. Формат параметров и их количество задается при параметром $format, при помощи тех же спецификаторов форматирования, о которых мы говорили, только без знака %. После каждого спецификатора может стоять число, которое говорит о том, сколько информации будет обработано данным спецификатором. Для форматов a, A, h и H это число задает количество символов, которые будут помещены в бинарную строку из тех, что находятся параметре-строке при вызове функции (то есть, фактически определяется размер поля вывода строки). Если мы используем спецификатор " @ ", то мы определяем абсолютную позицию, в которую будут помещены данные. Для всех остальных спецификаторов следующие за ними числа задают количество аргументов, на которые распространяется действие данного формата. Вместо числа можно указать *, в этом случае спецификатор действует на все оставшиеся данные. Заметим, что функция возвращает упакованные данные в шестнадцатеричном формате.
Список спецификаторов формата:
· a - строка, свободные места в поле заполняются символом с кодом 0;
· A - строка, свободные места заполняются пробелами;
· h - шестнадцатеричная строка, младшие разряды в начале;
· H - шестнадцатеричная строка, старшие разряды в начале;
· c - знаковый байт (символ);
· C - беззнаковый байт;
· s - знаковое короткое целое;
· S - беззнаковое короткое число;
· n - беззнаковое целое (16 битов, старшие разряды в конце);
· v - беззнаковое целое (16 битов, младшие разряды в конце);
· i - знаковое целое (размер и порядок байтов определяется архитектурой);
· I - беззнаковое целое;
· l - знаковое длинное целое (32 бита, порядок знаков определяется архитектурой);
· L - беззнаковое длинное целое;
· N - беззнаковое длинное целое (32 бита, старшие разряды в конце);
· V - беззнаковое целое (32 бита, младшие разряды в конце);
· f - число с плавающей точкой;
· d - число двойной точности;
· x - символ с нулевым кодом;
· X - возврат назад на 1 байт;
· @ - заполнение нулевым кодом до заданной абсолютной позиции.
Функция
Unpack()
Как уже говорилось выше, Распаковывает данные из двоичной строки согласно формату. Функция возвращает массив, содержащий распакованные элементы.
|
|
|
Синтаксис:
array unpack ( string $format, string $data )Давайте попробуем что-нибудь запаковать. К примеру, так.
<? $bin = pack ( "nvn*",0x5722,0x1148, 65, 66 ); // запаковываем, согласно формату $var = bin2hex ( $bin ); // перекодируем из шестнадцатеричного формата echo( $var ); ?>Итак, что мы увидели: функция вернула 6 байтов, причем в такой последовательности:
0х57, 0х22, 0х48, 0х11, 0х00, 0х41, 0х00, 0х42. Понятно, почему так. Согласно заданному нами формату (nvn*), первое число мы возвращаем как беззнаковое целое со старшими разрядами в конце, второе тоже как беззнаковое целое, только в конце – младшие разряды (поэтому нам вернулось 0х48, 0х11, а не 0х11, 0х48), и все остальное до конца мы возвращаем как беззнаковое целое со старшими разрядами в конце.
Функции работы с блоками текста
| wordwrap() str_replace() substr_replace() | strtr() stripslashes() stripcslashes() | addslashes() addcslashes() quotemeta() | strrev() |
Wordwrap()
Синтаксис:
string wordwrap ( string str [, int width [, string break [, int cut ]]] )Функция wordwrap() разбивает исходный текст на строки с определенными завершающими символами. Согласно синтаксису, эта функция разбивает блок текста str на несколько строк, которые завершаеются символами break, так, чтобы в одной строке было не более width букв. Поскольку разбиение происходит по границам слов, текст остается вполне читаемым.
К примеру:
<? $str = "Вставай, страна огромная"; $mod_str = wordwrap ( $str,5,"\t" ); echo( $mod_str ); ?>Str_replace()
Синтаксис:
string str_replace ( string from, string to, string str )Функция str_replace() заменяет в исходной строке str одни подстроки на другие. Т.е. функция заменяет в строке str все вхождения подстроки from на to и возвращает результат. Эта функция может работать с двоичными строками.
Функция, вообще говоря, нужная. К примеру, если Вы пишите что-то типа гостевой книги, форума, и хотите, чтобы в форме ввода для выделения теста можно было пользоваться стандарными тегами HTML, Вы можете с помощью этой функции заменить символы, которые Вы выбрали для форматирования на стандартные теги НТML. К примеру:
$txt = str_replace ( "[B]","<B>", $txt );Т.е. если Вы используете для отображения текста полужирным шрифтом символы "[B]", Вы должны их заменить на символ "<B>", используемые в НТМL.
Позже, при написании реального проекта, мы обязательно будем использовать как эту, так и многие другие, рассмотренные нами функции.
Substr_replace()
Синтаксис:
string substr_replace ( string str, string replacement, int start [, int length ] )Эта функция заменяет в исходной строке одни подстроки на другие. Она возвращает строку str, в которой часть от символа с позицией start и длиной length заменяется строкой replacement. Если аргумент длины length не указан, замена проводится до конца.
Если значение аргумента start положительно, то отсчет производится от начала строки str, в противном случае - от конца. В случае неотрицательного значения length, оно указывает длину заменяемого фрагмента. Если же оно отрицательно, то это - число символов от конца строки str до последнего символа заменяемого фрагмента.
Strtr()
Синтаксис:
string strtr ( string str, string from, string to )string strtr ( string str, array from )
Эта функция предназначена для комплексной замены в строке и имеет два вида синтаксиса. В первом случае функция strtr() возвращает строку str, в которой каждый символ, присутствующий в строке from, заменяется на символ из строки to. Если строки from и to различной длины, то лишние конечные символы у той строки, которая длинее, игнорируются. Во втором случае функция strtr() возвращает строку, в которой фрагменты строки str заменяются на фрагменты, соответствующие индексам значений элементов массива from. Сначала функция пытается заменить наибольшие фрагменты исходной строки, при этом не выполняя замену в уже модифицированных частях строки. Таким образом, можно выполнить несколько замен сразу:
<? $str = array ( "" => "M.Kuznetsov", "<name2>" => "I.Simdyanov" ); $str_out = "Авторы этого учебника и приветствуют вас!"; echo strtr ( $str_out, $str ); ?>А вот как можно при помощи этой функции отменить действие функции htmlspecialchars():
<? $var = array_flip ( get_html_translation_table () ); $str = strtr ( $str, $var ); ?>Т.е., из строки, в которой все спецсимволы заменены на их HTML-эквиваленты, мы получаме исходную строку.
Stripslashes()
Синтаксис:
string stripslashes ( string str )Функция удаления обратных слешей. Т.е. производится замена в строке str предваренных слешем символов на их кодовые эквиваленты. Функция работает с символами: ", ", \.
Stripcslashes()
Синтаксис:
string stripcslashes ( string str )А эта функция преобразует спецсимволы в их двоичное представление.
Она возвращает строку, в которой закомментированные обратным слешем спецсимволы, (с целью визуального отображения), преобразуются в их двоичное представление. Функция распознает C-подобные записи (восьмеричные и шестнадцатеричные последовательности \n, \r и т.д.).
Addslashes()
Синтаксис:
string addslashes ( string str )Функция добавления слешей перед символами строки "," и \. Эту функцию удобно использовать при вызове функции eval().
Addcslashes()
Синтаксис:
string addcslashes ( string str, string charlist )Функция добавление слешей перед специальными символами строки.
Возвращает строку str, в которую вставлены символы обратного слеша перед перечисленными в списке charlist символами. Это позволяет преобразовывать символы, которые не печатаются в их визуальное С-представление.
Quotemeta()
Синтаксис:
string quotemeta ( string str )Функция цитирования метасимволов. Возвращает строку, в которую добавлены обратные слеши перед каждым из следующих символов:. \\ + *? [ ^ ] ($). Функцию можно использовать для подготовки шаблонов в регулярных выражениях.
Strrev()
Синтаксис:
string strrev ( string str )Функция производит реверс строки.
Функции объединения/разделения строк
| str_repeat() str_pad() | chunk_split() strtok() | explode() implode() | join() |
Str_repeat()
Синтаксис:
string str_repeat ( string str, int number )Функция повторения строки. Повторяет строку str то количество раз, которое указано в параметре number.
К примеру:
<? echo str_repeat(" Hello! ",3 ); // выводит Hello! Hello! Hello! ?>Str_pad()
Синтаксис:
string str_pad ( string strinput, int pad_length [, string pad_string [, int pad_type ]] )Эта функция дополняет строку другой строкой до определенной длины. Аргумент strinput задает исходную строку. Аргумент pad_length задает длину возвращаемой строки. Если он имеет меньшее значение, чем исходная строка, то добавления не производится. Необязательный аргумент pad_string указывает на то, какую строку использовать в качестве дополнения. По умолчанию используются пробелы. Необязательный аргумент pad_type указывает, с какой стороны следует дополнять строку: справо, слево или с обеих сторон. Аргумент pad_type может принимать следующие значения:
· STR_PAD_RIGHT (по умолчанию)
· STR_PAD_LEFT
· STR_PAD_BOTH
Chunk_split()
Синтаксис:
string chunk_split ( string str [, int chunklen [, string end ]] )Эта функция возвращает фрагмент строки. Функция chunk_split () возвращает строку, в которой между каждым блоком строки str длиной chunklen (по умолчанию chunklen = 76) вставляется последовательность из разделителей end (по умолчанию: end = " \r\n ").
Strtok()
Синтаксис:
string strtok ( string arg1, string arg2 )Фунция возвращает строку по частям. Она возвращает часть строки arg1 до разделителя arg2. При последующих вызовах функции возвращается следующая часть до следующего разделителя, и так до конца строки. При первом вызове функция принимает два аргумента: исходную строку arg1 и разделитель arg2. Обратите внимание, что при каждом последующем вызове arg1 указывать не надо, иначе будет возвращаться первая часть строки.
Пример:
<? $str = "I am very glad to see%you% adhahjasdad"; $tok = strtok ( $str, " " ); while( $tok ) { echo ( $tok ); echo ( " " ); $tok = strtok ( " %" ); }; // выведет: "I" "am" "very" "glad" "to" "see" "you": ?>
Т.е., видите, что абракадабра, которую мы написали в конце строки, не выводится. Это результат того, что когда в строке последовательно встречаются два или более разделителей, функция возвращает пустую строку, что, к примеру, может прекратить цикл обработки, как в этом примере.
Explode()
Синтаксис:
string explode ( string arg, string str [, int maxlimit ] )Функция explode () производит разделение строки в массив. Она возвращает массив строк, каждая из которых соответствует фрагменту исходной строки str, находящемуся между разделителями, указанными аргументом arg. Необязательный параметр maxlimit указывает максимальное количество элементов в массиве. Оставшаяся неразделенная часть будет содержаться в последнем элементе.
Пример:
<? $str = "one two three for five"; $str_exp = explode ( " ", $str ); /* теперь $str_exp = array([0] => one, [1] => two, [2] => three, [3] => for, [4] => five) */ ?>Implode()
Синтаксис:
string implode ( string var, array param )Функция implode () является обратной функции explode () и производит объединение массива в строку. Функция возвращает строку, которая последовательно содержит все элементы массива, заданного в параметре param, между которыми вставляется значение, указанное в параметре var. Для примера выведем все то, что мы только что "умассивили" функцией explode (), используя пробел в качестве разделителя:
Пример:
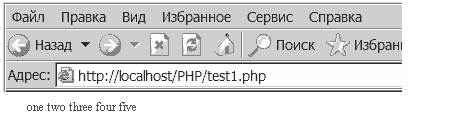
<? $str = "one two three four five"; $str_exp = explode ( " ", $str ); /* $str_exp = array([0] => one, [1] => two, [2] => three, [3] => four, [4] => five) */ $str_imp = implode ( " ", $str_exp ); echo( $str_imp );Результат:
Join()
Синтаксис:
string join ( string var, array param )Аналог функции implode () - производит объединение массива в строку.
Вообще говоря, как Вы увидели, последние три функции имеют прямое отношение как к массивам, так и строкам, и многие авторы рассматривают их в разделе, где рассказывается о массивах. Мы решили их рассмотреть в этой главе, поскольку официально эти функции все же считаются строковыми, а о массивах мы будем говорить в следующей главе.
Функции сравнения строк
| strcmp() strncmp() | strcasecmp() strncasecmp() | strnatcmp() strnatcasecmp() | similar_text() levenshtein() |
Strcmp()
Синтаксис:
int strcmp ( string str1, string str2 )Эта функция сравнения строк. Она сравнивает две строки и возвращает:
· 0 - если строки полностью совпадают;
· 1 - если, строка str1 лексикографически больше str2;
· 1 – если, наоборот, строка str1 лексикографически меньше str2
Функция является чувствительной к регистру, т.е. регистр символов влияет на результаты сравнений (поскольку сравнение происходит побайтово).
Пример:
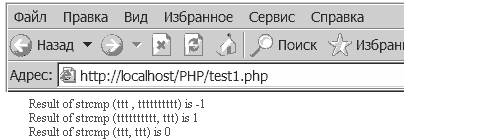
<? $str1 = "ttt"; $str2 = "tttttttttt" ; echo( "Result of strcmp ($str1, $str2) is "); echo( strcmp ( str1, str2 )); echo( "< br >" ); echo( "Result of strcmp ($str2, $str1)> is "); echo( strcmp ( str2, str1 )); echo( "< br >" ); echo( "Result of strcmp ($str1, $str1) is "); echo( strcmp (str1, str1 )); ?>Результат:
Strncmp()
Синтаксис:
int strncmp ( string str1, string str2, int len )Эта функция отличается от strcmp () тем, что сравнивает начала строк, а точнее первые len байтов. Если len меньше длины наименьшей из строк, то строки сравниваются целиком.
В остальном функция ведет себя аналогично strcmp (), т.е. возвращает:
· 0 - если строки полностью совпадают;
· 1 - если, строка str1 лексикографически больше str2;
· 1 – если, наоборот, строка str1 лексикографически меньше str2
Сравнение также проводится побайтово, поэтому функция чувствительна к регистру.
Strcasecmp()
Синтаксис:
int strcasecmp ( string str1, string str2 )Функция работает аналогично strcmp (), только при работе не учитывается регистр букв.
Strncasecmp()
Синтаксис:
int strncasecmp ( string str1, string str2, int len )Функция strncasecmp () cравнивает начала строк без учета регистра.
Strnatcmp()
Синтаксис:
int strnatcmp ( string str1, string str2 )Производит так называемое "естественное" сравнение строк.
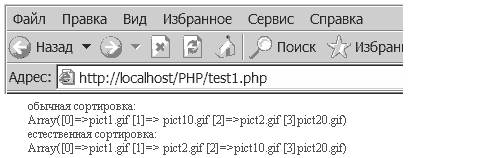
Об этой функции поговорим поподробнее. Данная функция является имитатором сравнение строк человеком, т.е. она сравнивает строки так, как их сравнивал бы человек. Т.е., если, к примеру, мы будем сравнивать файлы с названиями pict1.gif, pict20.gif, pict2.gif, pict10.gif, то обычное сравнение приведет к следующему их расположению: pict1.gif, pict10.gif, pict2.gif, pict20.gif. Естественная же сортировка даст результат, который нам более привычен: pict1.gif, pict2.gif, pict10.gif, pict20.gif.
В примере использования этой функции мы опять забежим вперед и прибегнем к функциям работы с массивами. Поэтому мы советуем Вам после прочтения главы о массивах еще раз взглянуть на этот пример, и использовать его, когда Вам надо отсортировать все то, что связано со строками, к примеру, названия файлов.
<? $array1 = $array2 = array("pict10.gif", "pict2.gif", "pict20.gif", "pict1.gif"); echo( "обычная сортировка:" ); echo ( "< br >" ); usort ( $array1, strcmp ); print_r ( $array1 ); echo ( "< br >" ); echo( "естественная сортировка:" ); echo( "< br >" ); usort ( $array2, strnatcmp ); print_r ( $array2 ); ?>Этот скрипт выведет следующее:
Strnatcasecmp()
Синтаксис:
int strnatcasecmp ( string str1, string str2 )Производит "естественное" сравнение строк без учета регистра. Функция выполняет то же самое, что и strnatcmp (), только без учета регистра.
Similar_text()
Синтаксис:
int similar_text ( string str_first, string str_second [, double percent ] )Эта функция производит определение схожести двух строк.
Функция similar_text () определяет схожесть двух строк по алгоритму Оливера. Функция возвращает число символов, совпавших в строках str_first и str_second. Третий необязательный параметр передается по ссылке и в нем сохраняется процент совпадения строк.
Вместо стека, как в алгоритме Оливера, эта функция использует рекурсивные вызовы. Сложность алгоритма этой функции равна O((max(n,m))3), что делает эту функцию медленной. (Грубо говоря, скорость выполнения этой функции пропорциональна N3, где N – длина наибольшей строки.
Пример:
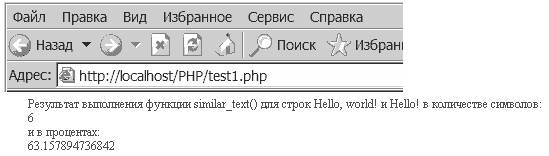
<? $str1 = "Hello, world!"; $str2 = "Hello!"; $var = similar_text ( $str1, $str2 ); $var1 = similar_text ( $str1, $str2, & $tmp ); // параметр $tmp передаем по ссылке echo( "Результат выполнения функции similar_text() для строк $str и $str1 в количестве символов:" ); echo( "< br >" ); echo( "$var"); echo( "< br >" ); echo( "и в процентах:" ); echo( "< br >" ); echo( $tmp ); // для вывода информации в процентах обращаемся к $tmp ?>Результат:
Levenshtein()
Функция выполняет определение различия Левенштейна двух строк.
Синтаксис:
int levenshtein ( string str1, string str2 ) int levenshtein ( string str1, string str2, int cost_ins, int cost_rep, int cost_del ) int levenshtein ( string str1, string str2, function cost )Под понятием " различие Левенштейна " понимается минимальное число символов, которое требовалось бы заменить, вставить или удалить для того, чтобы превратить строку str1 в str2.
Сложность алгоритма этой функции равна O(m*n), т.е. пропорциональна произведению длин строк str1 и str2, поэтому эта функция намного более быстрая, чем функция similar_text ().
Как видим, у функции три вида синтаксиса. В первом случае функция возвращает число необходимых операций над символами строк для преобразования str1 в str2:
<? $str1 = "Hello, world!"; $str2 = "Hello!"; $var = levenshtein ( $str1, $str2 ); echo( $var ); // вернет 7 ?>Во втором случае добавляется три дополнительных параметра: стоимость операции вставки cost_ins, замены cost_rep и удаления cost_del. Естественно, функция в этом случае становится менее быстродействующей. Возвращается интегральный показатель сложности трансформации (ИПСТ).
<? $str1 = "Hello, world!"; $str2 = "Hello!"; $var = levenshtein ( $str1, $str2,3,3,3 ); echo( $var ); // вернет 21 ?> Число 21, между прочим, это 7*3:). Т.е. ИПСТ равен произведению количества символов, необходимых для замены (а как мы посчитали в предыдущем примере их надобно 7) на стоимость, в этом случае, одной из операций. В этом примере, поскольку стоимость одинакова, не имеет значения, какую операцию брать. В случае, если стоимости различны, при вычисления ИПСТ берется наибольший. Т.е., если мы напишем в этом примере $var = levenshtein ( $str1, str2,2,3,6 );то функция вернет нам значение 42.
Третий вариант позволяет указать функцию, используемую для расчета сложности трансформации.
Функции работы с URL
| parse_url() parse_str() | rawurlencode() rawurldecode() | base64_encode() base64_decode() |
Parse_url()
Функция обрабатывает URL и возвращает его компоненты.
Синтаксис:
array parse_url ( string url )Эта функция возвращает ассоциативный массив, включающий множество различных сущест
|
|
|
