 |


Documents Type Definitions (DTD)
|
|
|
|
Cпециальные символы
Для того, чтобы включить в документ символ, используемый для определения каких-либо конструкций языка (например, символ угловой скобки) и не вызвать при этом ошибок в процессе разбора такого документа, нужно использовать его специальный символьный либо числовой идентификатор. Например, <, > " или $(десятичная форма записи),  (шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут определяться в XML документе при помощи компонентов (entity), о чем мы еще поговорим немного позже.
Директивы анализатора
Инструкции, предназначенные для анализаторов языка, описываются в XML документе при помощи специальных тэгов - <? и ?>;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, <? Xml version=”1.0”?>) или создании пространства имен[11].
CDATA
Чтобы задать область документа, которую при разборе анализатор будет рассматривать как простой текст, игнорируя любые инструкции и специальные символы, но, в отличии от комментариев, иметь возможность использовать их в приложении, необходимо использовать тэги <![CDATA] и ]]>. Внутри этого блока можно помещать любую информацию, которая может понадобится программе- клиенту для выполнения каких-либо действий (в область CDATA, можно помещать, например, инструкции JavaScript). Естественно, надо следить за тем, чтобы в области, ограниченной этими тэгами не было последовательности символов ]].
Что дальше
Мы рассмотрели в общих чертах основные структурные части XML- документа, правила описания элементов XML и теперь можем создать синтаксически правильный XML- документ, содержащий каким-то образом структурированные данные(более подробный пример приведен в Приложении 1.) Однако при этом почти не коснулись вопросов практического применения XML. Как отображать содержимое XML- документов на Web- страницах, осуществлять контроль над правильностью их составления; существуют ли уже сегодня какие-либо удобные средства для создания, анализа и просмотра таких документов? В следующих разделах мы попробуем ответить на эти вопросы.
|
|
|
2. Просмотр XML - документов
Как уже отмечалось, в отличии от HTML, XML никак не определяет способ отображения и использования описываемых с его помощью элементов документа, т.е. программе-анализатору предоставляется возможность самой выбирать нужное оформление. Этого требует принцип независимости определения внутренней структуры документа от способов представления этой информации. Например, задавая в документе элемент <flower>роза</flower>, мы лишь указываем, что rose в данном случае является цветком, но информации о том, как должен выглядеть данный элемент документа на экране клиента и должен ли он отображаться вообще, в таком определении нет.
Для того, чтобы использовать данные, определяемые элементами XML, например, отображать их на экране пользователя, необходимо написать программу-анализатор, которая бы выполняла эти действия. Уже сегодня таких программ появилось достаточное количество и у разработчиков существует возможность выбора наиболее подходящей из них для решения конкретных проблем
Как уже отмечалось ранее, в общем случае, программы- анализаторы можно разделить на две группы: верифицирующие(т.е. использующие DTD- описания для определения корректности документа) и не верифицирующие. Если Вы создаете свой язык и описываете его грамматику на основе DTD, то для анализа документов, написанных на этом языке, безусловно, потребуется программа, проверяющая корректность составления документа. Но так как использование DTD в XML не является обязательным, то любой правильно оформленный документ может быть распознан и разобран программой, предназначенной для анализа XML- документов. В любом случае, используя универсальные XML- анализаторы, Вы можете быть уверенным в том, что если заданные в документе конструкции языка являются синтаксически правильными, то программа-анализатор сможет правильно извлечь определяемые ими элементы документа и передать их прикладной программе, выполняющей необходимые действия по отображению. Т.е. после разбора документа в большинстве случаев, Вам предоставляется объектная модель, отображающая содержимое Вашего документа, и средства, необходимые для работы с ней (прохода по дереву элементов). При этом в некоторых анализаторах способ представления структуры документа основывается на спецификации DOM, описанной в[4]. Поэтому у Вас появляется также возможность использовать строгую иерархическую модель DOM для построения собственных документов.
|
|
|
Если речь идет о способах отображения информации, хранящейся в XML, то необходимо упомянуть разрабатываемый в настоящее время W3C стандарт стилевых таблиц для XML, которые предназначены для описания правил отображения элементов XML. Более подробно мы поговорим об XSL чуть позже.
Использование msxml в IE 4
Если на Вашем компьютере установлен броузер Internet Explorer 4 (или более поздняя версия), то Вы можете использовать встроенный в этот броузер XML- анализатор msxml в своих сценариях, написанных на Java Script ил VBScript,. В настоящий момент существуют две его реализации, - одна предназначена для использования в виде написанного на C++ ActiveX- объекта(реализация на базе COM- технологии) другая, написанная на Java, не зависит от платформы. Оба анализатора не сложны, имеют сравнительно небольшой размер - msxml на C++ занимает около 100k, версия на Java - 127k. Анализатор, написанный на C++, в текущей реализации не поддерживает DTD- правил, более компактный и быстрый, чем его Java-версия. Оба они имеют поддержку иностранных языков, т.е. в составе Internet Explorer C++- анализатор работает со всеми языками, "понимаемыми" броузерами, а анализатор на Java - с теми языками, с которыми может работать виртуальная Java-машина.
|
|
|
Т.к. обе версии разрабатывались параллельно, объектная модель, заложенная в основу каждой из них, внешне схожа, поэтому больших сложностей при переходе от одной версии к другой обычно не возникает.
Рассмотрим основные свойства и методы, доступные JavaScript- сценарию в процессе его выполнения на стороне броузера. В наших примерах мы будем использовать XML- анализатор в сценариях Java Script, т.к. этот способ более понятен и быстрее работает. Полное описание C++ интерфейсов анализатора доступны в документации по Internet Client SDK
Объектная модель XML в Internet Explorer 4.0
Перед тем, как использовать свойства и методы анализатора, его необходимо создать. Делается это при помощи стандартного метода, предназначенного для создания ActiveX- объектов:
var mydoc = new ActiveXObject("msxml");Если ActiveX- компонент был зарегистрирован на Вашей машине (или у Вас установлен броузер Internet Explorer 4), то в результате выполнения этой функции переменной mydoc будет присвоен объект, имеющий тип msxml, свойства и методы которого используются в дальнейшем для получения доступа к структуре XML- документа.
В Приложении 2 приведен полный текст сценария JavaScrtipt, выводящего на экран броузера Internet Explorer 4.0 XML- документ, созданный в Приложении 1. Вы можете использовать этот пример и комментарии к нему в качестве еще одного средства для более быстрого понимания принципов использования свойств и методов объектов Microsoft XML и создания собственных сценариев.
Объектная модель XML- анализатора Microsoft может быть представлена в виде следующего набора внутренних объектов: XML Document, XML Element и Element Collection. Объект XML Document содержит свойства и методы, необходимые нам для работы с XML- документом в целом. XML Element отвечает за работу с каждым из элементов XML- документа. Element Collection представляет из себя набор элементов, доступ к которым доступен при помощи имени или порядкового номера. В следующих примерах мы рассмотрим каждый из этих объектов подробнее.
Свойства и методы документа(объект XML Document)
| URL | Свойство, доступное для записи и чтения. Задает или возвращает URL обрабатываемого документа. В случае изменения этого свойства текущий документ уничтожается и начинается загрузка нового по указанному URL |
| root | Возвращает корневой элемент XML- документа |
| charset | Свойство, доступное для записи и чтения. Возвращает или устанавливает название текущее кодировочной таблицы согласно требованиям ISO. |
| version | Возвращает номер версии XML |
| doctype | Возвращает содержимое элемента!DOCTYPE |
| createElement() | Метод, позволяющий создать новый элемент, который будет добавлен в качестве дочернего для текущего элемента дерева. В качестве первого параметра задается тип элемента, в качестве второго - название элемента xml.createElement(0,"new_element") |
| fileSize | Возвращает размер XML- документа. Это свойство в C++- версии анализатора еще не реализовано |
| fileModifiedDate | Возвращает дату последнего изменения XML- документа. Это свойство в C++- версии анализатора еще не реализовано |
| fileUpdatedDate | Возвращает дату последнего обновления XML- документа. Это свойство в C++- версии анализатора еще не реализовано |
| mimeType | Возвращает MIME-тип(MIME- Multipurpose Internet Mail Extension, RFC 1341).Это свойство в C++- версии анализатора еще не реализовано |
Ниже приведен фрагмент JavaScript- сценария, использующего эти методы и свойства для вывода информации о текущем документе:
|
|
|
Свойства и методы элементов документа
| type | Возвращает тип элемента. Это свойство может быть использовано для того, чтобы разделить имена тэгов и данные, содержащиеся внутри них. В данной версии анализатора определены следующие типы элементов: 0 - элемент 1 - текст 2 - комментарий 3 - Document 4 - DTD |
| tagName | Возвращает или устанавливает название тэга(в виде строки с символами, приведенными к верхнему регистру). Названия метатэгов(например, <?xml?>) начинаются с символа?. Названия тэгов комментариев начинаются с символа!. |
| text | Возвращает текстовое содержимое элементов и комментариев. |
| AddChild() | Добавление нового дочернего элемента и всех его потомков в текущую ветвь дерева. В качестве первого параметра этой функции необходимо передать объект типа Element, который затем будет помещен в список дочерних элементов. Также необходимо задать индекс нового элемента в списке и в качестве последнего параметра обязательно передать значение -1. Т.к. в данной модели любой элемент в документе может иметь ссылку только на один родительский элемент, при выполнении данной процедуры у добавляемого объекта старая ссылка на родительский элемент теряется. Используя это свойство, можно перемещать элементы из одного XML- документа в другое, но том случае, если у дочерних ссылок перемещаемого элемента существуют внешние ссылки или сами дочерние элементы ссылаются на внешние возможно возникновение ошибки elem.addChild(elem.children.item().children.item(0),0,-1) |
| removeChild() | Удаляет дочерний элемент и всех его потомков. Элементы остаются в памяти и могут быть вновь добавлены к дереву при помощи метода addChild(). elem.removeChild(elem.children.item(1)) |
| parent | Возвращает указатель на текущий родительский элемент. Ссылки на родительский элемент имеют все элементы, за исключением корневого. |
| GetAttribute() | Возвращает значение указанного атрибута в виде текстовой строки. elem.getAttribute("color") |
| SetAttribute() | Устанавливает указанный атрибут и его значение. Прежнее значение атрибута теряется elem.setAttribute("color","red") |
| removeAttribute() | Уничтожает указанный атрибут elem.removeAttribute("color") |
| children | Возвращает ассоциированный список дочерних элементов(коллекцию). Такой список позволяет приложению получать нужные элементы как по названию, так и по порядковому номеру при помощи метода item(). В том случае, если потомков у текущего элемента нет, функция возвратит null |
Пример использования
|
|
|
Вот пример использования описанных функций:
<script language="javascript"><!--var xmldoc = new ActiveXObject("msxml");var xmlsrc = "http://localhost/xml/sample.xml";function parse(root){ var i=0; if(root.type==0){ this.document.writeln('<UL>Current tag is '+root.tagName+' (parent is '+root.parent+'). '); }else if(root.type==1){ this.document.writeln('<LI>It is a text of '+root.parent.tagName+' element: <i>'+root.text+'</i></LI>'); }else{ this.document.writeln('<br><br>Error'); } if(root.children!=null){ this.document.writeln('It consist of '+root.children.length+' elements:'); for(i=0;i<root.children.length;i++){ parse(root.children.item(i)); } }else{ this.document.writeln('</UL>'); }}function viewDocument(){xmldoc.URL = xmlsrc;this.document.writeln('<body bgcolor="white">');this.document.writeln('<p><center><hr width=80%>XML sample page<hr width=80%></center><p>');parse(xmldoc.root);this.document.writeln('</body>');}viewDocument();//--></script>Как видно из примера, в процессе обработки XML- документа необходимо рекурсивно обходить все ветви создаваемого анализатором дерева, причем, на каждом шаге возможны следующие ситуации:
- Встретился новый элемент. В этом случае его название(задаваемое тэгом) доступно при помощи свойства tagName, а содержимое - свойством text. У любого непустого элемента существует хотя бы один потомок, представляющий собой содержимое этого элемента(в этом отличие представленной объектной модели msxml от реальной структуры документа - в XML под элементом понимается как название тэга, так и текстовое содержимое его)
- Встретилось текстовое поле. Это поле может быть либо комментарием, либо просто текстом, содержащемся в текущем элементе
Для обработки потомков текущего элемента используется метод item(), который вызывается в цикле столько раз, сколько потомков у текущего элемента. Обработка каждого дочернего элемента осуществляется вызовом этой же функции, в чем и заключается рекурсия.
Использование ASP
Доступ к свойствам XML- анализатора возможен также из сценариев ASP(Active Server Pages), выполняющихся на стороне сервера. Если при написании ASP-модуля используется язык VBscript, то для создания объекта, представляющего XML- документ, необходимо включить следующее выражение:
Set myxml=Server.CreateObject("msxml")Однако необходимо учитывать, что в качестве сервера в этом случае надо использовать Web- сервер, поддерживающий ISAPI, и так же на компьютере должны быть установлены или броузер Internet Explorer версии 4 и выше, или зарегистрированный в реестре ActiveX- компонент msxml.
Вот пример использования свойств XML-документа в ASP- программе:
<%Set myxml=Server.CreateObject("msxml")myxml.url = "http://localhost/xml/sample1.xml"url=myxml.urlSet root=myxml.rootversion=myxml.versioncharset=myxml.charset%><html><body bgcolor="white"><center><table width=80%><tr> <td align="center" bgcolor="silver">URL</td> <td align="center"><%=url%></td></tr><tr> <td align="center" bgcolor="silver">Version</td> <td align="center"><%=version%></td></tr><tr> <td align="center" bgcolor="silver">Root element</td> <td align="center"><%=root.tagName%></td></tr><tr> <td align="center" bgcolor="silver">Charset</td> <td align="center"><%=charset%></td></tr></table></body></html>Создавая msxml - объект при помощи CreateObject, мы в дальнейшем вызываем его методы и свойства привычным нам способом. Отличается лишь способ вставки полученной информации в HTML- страницу - она генерируется не на стороне клиента, а приходит к нему в уже готовом виде.
В заключение хотелось бы отметить, что рассмотренные способы работы с XML- документами могут применяться для отображения их элементов на экране броузера. Не всегда они являются наиболее эффективными для форматирования текста - для каждого нового документа с измененной структурой требуются частично или полностью переписывать обработчик(в следующем разделе мы попробуем использовать для этих же целей стилевые таблицы XSL). Однако использование Java Script позволяет уже сегодня разрабатывать реальные Интернет- приложения, использующие встроенный в броузер клиента анализатор в качестве средства для доступа к структурированной информации XML.
3. Стилевые таблицы XSL
В предыдущем разделе для вывода элементов XML- документа на экран броузера мы применяли Java Script-сценарии Однако, как уже отмечалось, для этих целей предпочтительней использование специально предназначенного для этого средства - стилевых таблиц XSL(Extensible Stylesheet Language).
Стилевыми таблицами (стилевыми листами) принято называть специальные инструкции, управляющие процессом отображения элемента в окне программы-клиента(например, в окне броузера). Предложенные в качестве рекомендация W3C, каскадные стилевые таблицы(CSS- Cascading Style Sheets [7]) уже больше года используются Web- разработчиками для оформления Web- страниц. Поддержка CSS наиболее известными на сегодняшний день броузерами Netscape Navigator(начиная с версии 4.0) и Microsoft Explorer(начиная с версии 3.0), позволила использовать стилевые таблицы для решения самого широкого спектра задач - от оформления домашней странички до создания крупного корпоративного Web-узла. Слово каскадные в определении CSS означает возможность объединения отдельных элементов форматирования путем вложенных описаний стиля. Например, атрибуты текста, заданные в тэге <body>, будут распространяться на вложенные тэги до тех пор, пока в них не встретятся стилевые описания, отменяющие или дополняющие текущие параметры. Таким образом, использование таблиц CSS в HTML было весьма эффективно - отпадала необходимость явного задания тэгов форматирования для каждого из элементов документа.
Являясь очень мощным средством оформления HTML- страниц, CSS- таблицы, тем не менее, не могут применяться в XML-документах, т.к. набор тэгов в этом языке не ограничен и использование статических ссылок на форматируемые объекты документа в этом случае невозможно.
Поэтому для форматирования XML- элементов был разработан новый язык разметки, являющийся подмножеством XML, и специально был предназначен для форматирования XML- элементов.
Некоторые его отличия от CSS:
Во-первых, стилевые таблицы XSL позволяют определять оформление элемента в зависимости от его месторасположения внутри документа, т.е. к двум элементам с одинаковым названием могут применяться различные правила форматирования.
Во-вторых, языком, лежащем в основе XSL, является XML, а это означает, что XSL более гибок, универсален и у разработчиков появляется возможность использования средства для контроля за корректностью составления таких стилевых списков(используя DTD или схемы данных)
В-третьих, таблицы XSL не являются каскадными, подобно CSS, т.к. чрезвычайно сложно обеспечить "каскадируемость" стилевых описаний, или, другими словами, возможность объединения отдельных элементов форматирования путем вложенных описаний стиля, в ситуации, когда структура выходного документа заранее неизвестна и он создается в процессе самого разбора. Однако в XSL существует возможность задавать правила для стилей, при помощи которых можно изменять свойства стилевого оформления, что позволяет использовать довольно сложные приемы форматирования
В настоящий момент язык XSL находится на стадии разработки в W3C[3] и в будущем, видимо, станет частью стандарта XML. Это означает, что использование этого механизма является наиболее перспективным способом оформления XML- документов. В текущем рабочем варианте W3C, XSL рассматривается не только как язык разметки, определяющий стилевые таблицы - в него заложены средства, необходимые для выполнения действий по фильтрации информации, выводимой в окно клиента, поиска элементов, сложного поиска, основанного на зависимостях между элементами и т.д. На сегодняшний день единственным броузером, поддерживающим некоторые из этих возможностей, является бэта-версия Internet Explorer 5.0, однако в самом ближайшем будущем, безусловно, XSL будет использоваться также широко, как сегодня стандартные тэги HTML
В этом разделе мы рассмотрим упрощенную объектную модель XSL- документа, используемую в текущей версии XSL-конвертора Microsoft msxsl, и поэтому информацию, изложенную далее, нельзя считать описанием стандарта языка. Полный рабочий вариант спецификации XSL в последней его редакции доступен на сервере [3].
Все примеры, приводимые далее, могут быть проверены при помощи XSL- конвертора, свободно доступного на странице Mcrosoft [ www.microsoft.com/xml/xsl/ ]
С чего начать
Принцип обработки XML- документов стилевыми таблицами заключается в следующем: при разборе XSL-документа программа-анализатор обрабатывает инструкции этого языка и каждому элементу, найденному в XML- дереве ставит в соответствие набор тэгов, определяющих форматирование этого элемента. Другими словами, мы задаем шаблон форматирования для XML- элементов, причем сам этот шаблон может иметь структуру соответствующего фрагмента XML-документа. Инструкции XSL определяют точное месторасположение элемента XML в дереве, поэтому существует возможность применять различные стили оформления к одинаковым элементам, в зависимости от контекста их использования. На рисунке 3.1 представлена схема, иллюстрирующая этот процесс.
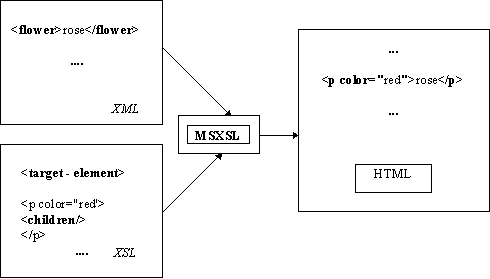
Рис 1
В общем случае, XSL позволяет автору задавать параметры отображения элемента XML, используя любые языки, предназначенные для форматирования - HTML, RTF и т.д. В этом разделе мы будем использовать в качестве такого языка HTML, т.к. документы, созданные при помощи этого языка разметки могут просматриваться любой подходящей программой просмотра Web-страниц
Структура XSL- таблиц
Рассмотрим основные структурные элементы XSL, используемые, в частности, в конверторе msxsl, для создания оформления XML-документов.
Правила XSL
XSL- документ представляет собой совокупность правил построения, каждое из которых выделено в отдельный блок, ограниченный тэгами <rule> и </rule>;. Правила определяют шаблоны, по которым каждому элементу XML ставится в соответствие последовательность HTML- тэгов, т.е. внутри них содержатся инструкции, определяющие элементы XML- документа и тэги форматирования, применяемые к ним.
Элементы XML, к которым будет применяться форматирование, обозначаются в XSL дескриптором <target-element/>;. Для указания элемента с конкретным названием (название элемента определяется тэгами, его обозначающими), т.е. определения класса элемента, можно использовать атрибут type ="<имя_элемента>"
Вот пример простейшего XSL-документа, определяющего форматирование для фрагмента <flower>rose</flower>:
<xsl><rule><target-element type="flower"/><p color="red" font-size="12"><children/></p></rule></xsl>Уже на этом примере можно проследить особенность использования стилевых таблиц: в любых правилах при помощи соответствующих элементов декларативно задается область, которая определяет фрагмент XML-документа, как мы чуть позже увидим, программа-анализатор заново проходит все элементы, начиная с текущего, всякий раз, когда в структуре XML- документа обнаруживаются новые вложенные элементы.
Инструкция <target-element> указывает на то, что данное правило определяет элемент. Параметром type="flower" задается название XML-элемента, для которого будет использоваться это правило. Программа-конвертор будет использовать HTML-тэги, помещенные внутри блока <rule></rule> для форматирования XML-элемента, которому "предназначался" текущий блок. В том случае, если для какого-то элемента XML шаблон не определяется, в выходной документ будут добавлены тэги форматирования по умолчанию (например, <DIV></DIV>)
Процесс разбора XSL-правил является рекурсивным, т.е. если у элемента есть дочерние элементы, то программа будет искать определения этих элементов, расположенных "глубже" в дереве документа. Указанием на то, что необходимо повторить процесс разбора XML документа, теперь уже для дочерних элементов, является инструкция <children/>. Дойдя до нее, анализатор выберет из иерархического дерева XML- элементов нужную ветвь и найдет в XSL-шаблонах правила, определяющие форматирование этих нижележащих элементов. В том случае, если вместо <children> мы укажем инструкцию <empty/>;, программа закончит движение по данной ветви и возвратится назад, в родительское правило. При этом текущее правило никакой информации в выходном HTML-документе изменять не будет, т.к. <empty/> в данном случае означает, что содержимое элемента отсутствует.
Если в одном правиле <target-element> используется несколько раз, то инструкции по форматированию будут распространены на все описываемые внутри него XML-элементы, т.е. можно задавать единый шаблон форматирования для нескольких элементов одновременно:
<xsl><rule><target-element type="item1"/><target-element type="item2"/><target-element type="item3"/><hr><children/><hr></rule></xsl>Ниже приведен пример более сложного XSL- описания, некоторые фрагменты которого будут пояснены позже.
XML-документ:
<?XML Version="1.0"?><documents><books><book id="Book1"><title>Макроэномические показатели экономики Римской Империи в период ее расцвета</title><author>Иван Петров</author><date>21.08.98</date></book><book id="Book2"><title>Цветоводство и животноводство. Практические советы</title><author>Петр Сидоров</author><date>10.10.98</date></book></books><articles><article id="Article1"><author>Петр Иванов</author><title>Влияние повышения тарифов оплаты за телефон на продолжительность жизни населения</title><date>12.09.98</date></article></articles></documents>Содержимое XSL-документа:
<xsl> <rule> <root/> <HTML> <BODY bgcolor="white"> <center><hr width="80%"/><b>Library</b><hr width="80%"/><br/> <table width="80%" border="2"> <children/> </table></center> </BODY> </HTML> </rule> <rule> <element type="book"> <target-element type="author"/> </element> <td align="center"> <p color="red" font-size="14"> <b> <children/> </b></p></td> </rule> <rule> <element type="article"> <target-element type="author"/> </element> <td align="center"> <p color="red" font-size="14" font-style="italic"><children/></p></td> </rule> <rule> <target-element type="book"/> <tr><children/></tr> </rule> <rule> <target-element type="article"/> <tr><children/></tr> </rule> <rule> <target-element/> <td align="center"><p><children/></p></td> </rule> <rule> <target-element type="books"/> <tr><td colspan="3" bgcolor="silver" >Books</td></tr> <children/> </rule> <rule> <target-element type="articles"/> <tr><td colspan="3" bgcolor="silver" >Articles</td></tr> <children/> </rule></xsl>Корневое правило
Разбор любого XSL- документа всегда начинается с правила для корневого элемента, в котором определяется область всего разбираемого XML документа и поэтому тэги форматирования, помещенные сюда, будут действовать на весь документ в целом. Для обозначения корневого правила необходимо включить в него элемент <root/>;. Например, для того, чтобы задать тэг <body> для формируемой нами выходной HTML- страницы, мы можем использовать следующий фрагмент:
<xsl><rule><root/><html><head><title> Flowers</title></head><body bgcolor="white" link="blue" alink="darkblue" vlink="darckblue"><children/></body></html></rule></xsl>В этом примере при помощи инструкций <root/> и <children/> мы определили ряд начальных и конечных HTML-тэгов для нашей страницы, между которыми затем в процессе рекурсивного обхода XSL- анализатора будут помещены остальные элемента документа.
В том случае, если мы не определяем правило для корневого элемента, разбор документа начнется с первого правила с инструкцией <target-element>(для оформления же заголовка документа будет использован образец форматирования, применяющийся по умолчанию).
Отношения между элементами
Дочерние элементы в XML-документе всегда находятся внутри области, определяемой тэгами родительского по отношению к ним элемента. Для того, чтобы точно указать месторасположение обрабатываемого элемента в дереве XML, в XSL используется дополнительный тэг <element>;. При помощи него можно указать, какие элементы должны предшествовать текущему, а какие - следовать после него. Например, в следующем фрагменте определяется, что форматирование элемента <title> будет зависеть от его месторасположения внутри XML-документа:
<xsl><rule><element type="journal"> <target-element type="title"/> </element><center><hr width=80%><children/><hr width=80%></center> </rule><rule><element type="article"> <target-element type="title"/> </element><td align="center"><p color="blue" font-size="14" font-style="italic"><children/></td></rule></xsl>Как видно из примера, если в XML- документе будет найден элемент <title>, являющийся дочерним по отношению к элементу <article> (название статьи), то его форматирование будет несколько отличаться от элемента <title>, расположенного внутри тэгов <journal>
Приоритеты правил
В том случае, если внутри XSL- документа встречается несколько правил для одного и того же элемента, то msxsl будет использовать то из них, которое более точно определяет позицию данного элемента. Т.е. если XSL- документ содержит следующие правила:
<rule><element type="journal"> <target-element type="title"/> </element><center><hr width=80%><children/><hr width=80%></center></rule><rule> <target-element type="title"/><b><children/></b> </rule>, то при использовании этой стилевой таблицы в случае, когда элемент <title> является потомком <journal>, к нему будет применено первое правило. Для любых же других элементов будет действовать правило без тэга <element>
В общем случае приоритет правил определяется следующим образом (в порядке убывания приоритета):
- правила, помеченные специальным тэгом <importance>
- правила с наибольшим значением атрибута id, если он определен
- правила с наибольшим значением атрибута class, если он определен
- правила, имеющие наибольшую вложенность, определяемую тэгом <element>
- правила, использующие атрибут type совместно с <target-element>
- правила, в которых отсутствует атрибут type в <target-element> или <element>
- правила с более высоким приоритетом, задаваемым атрибутом priority тэга <rule>
- правила с наибольшим значением квалификаторов <only>, <position>, <attribute>
Использование атрибутов элементов
Применительно к <target-element> и <element> в правилах также могут использоваться специальные элементы <attribute>;, при помощи которых можно уточнять характеристики обрабатываемых элементов, задавая различные инструкции форматирования для одинаковых элементов с различными атрибутами. Указываемые в <attribute> параметры name и value определяют атрибут XML, который должен иметь текущий обрабатываемый элемент. Например, в следующем фрагменте все элементы с атрибутом free_lance ="true" будут выделены в выходном HTML- документе серым цветом
<rule><target-element type="author"> <attribute name="free_lance" value="true"> </target-element><p color="gray"><children/></p> </rule>Фильтрация элементов
Одним из самых мощных средств XSL является возможность сортировки и выборки элементов, выделяемых из общего дерева элементов документа. Для этого используется элемент <select-elements>;, который заменяет <children/> в правилах, определяя те элементы, которые следует обработать в процессе рекурсивного обхода. Например, в следующем примере будут обработаны только элементы <author>:
<rule><target-element type=" staff"/><div><select-elements><target-element type = "author"/></select-elements></div></rule>Элемент <select-elements> сам по себе не определяет шаблон форматирования, он лишь управляет работой анализатора, обозначая, подобно <children/>, "нижележащие" элементы. В приведенном примере элемент <author> должен быть расположен внутри элемента <staff>
Для того, чтобы в шаблоне выделить не только собственные дочерние элементы, но и дочерние элементы потомков, т.е. использовать несколько уровней вложенности, необходимо задать параметр from = "descendants". Если параметр имеет значение "children", что указывает на то, что выбор должен производится из списка собственных дочерних элементов, то атрибут from может опускаться, т.к. "children" является значением по умолчанию.
Правила стилей
В отличие от CSS, в XSL невозможно использование каскадных стилевых определений(т.е. нельзя использовать несколько правил для определения стиля одного того же элемента), т.к. такие ограничения вводит рекурсивный алгоритм работы программы - анализатора. Однако использование правил определения стиля(Style Rules) элемента позволяет каким-то образом скомпенсировать этот недостаток.
Для определения правила стилевого оформления необходимо воспользоваться элементом <style-rule>;, который используется точно также, как и <rule>, но инструкции, содержащиеся в нем, никак не влияют на структуру выходного документа. Поэтому все команды внутри этого правила должны описываться в рамках элемента <apply>. Вот как будет выглядеть, например, определение стиля для элемента <flower>rose</flower>;:
<style-rule><target-element type ="flower"/><apply color ="red"/></style-rule> <rule><target-element type="flower"/><div font-style="italic";><children/></div></rule>Если бы мы не определили правила <rule>, то в выходной документ не было бы помещено никакой информации, т.к. элемент <style-rule> только определяет параметры стилевого оформления, не предпринимая никаких других действий.
Также надо учитывать, что XSL- анализатор использует CSS для определения задаваемого правилами <style-rule> стиля в выходном HTML-документе, тем самым предоставляя нам возможность использования этого мощного средства при оформлении HTML-страниц После обработки приведенного в примере фрагмента в выходной документ будут помещены следующие элементы:
<div style= "font-style: italic; color: red;">rose</div>Еще один пример:
Стили в формате CSS:
issue {font-weight=bold; color=blue;}.new {font-weight=bold; color=red;}Фрагмент XSL- документа, позволяющего использовать подобные стилевые определения:
<style-rule><target-element type ="issue"/><apply color ="blue"/></style-rule> <style-rule><target-element type ="issue"><attribute name ="class" value ="new" /></target-element><apply color ="red"/></style-rule> <rule><target-element type="issue"/><div><children/></div></rule>Сценарии
Сценарии могут использоваться в документах XSL точно также, как и в HTML. Кроме того, сценарии, содержащиеся внутри XSL-документа и запускаемые броузером в процессе обработки документа могут динамически создавать HTML-документы, извлекая необходимую для этого информацию непосредственно из элементов XSL-документа.
Для написания сценариев XSL использует специальный скриптовый язык - ECMAScript. Однако в msxsl для этих целей можно применять Microsoft JavaScript,- язык, который объединил в себе некоторые элементы стандартного JavaScript и ECMAScript.
Вычисление выражений
Наиболее простым примером использования сценариев в XSL -документе является вычисление значений параметров описываемых элементов. Для этого надо просто поставить знак равенства в качестве первого символа параметра, что заставит XSL-процессор вычислить значение выражения(синтаксис этого выражения должен отвечать требованиям JavaScript). Например, после разбора этого правила:
<rule><target-element type="header"><hr width="=100-20+'%'"><children/><hr width="80%"></rule>, в выходном документе окажутся следующие инструкции:
<hr width=80%>...<hr width=80%>Очень часто в правилах XSL необходимо использовать атрибуты описываемого в них элемента. Для этого мы должны воспользоваться методом getAttribute(), описанным в объектной модели XML (мы рассматриваем объектную модель XML-документов, предложенную Microsoft, список этих функций приведен в конце раздела). Т.к. каждому элементу XSL доступен указатель на соответствующий ему объект, сценарий может обращаться к внутренним функциям и свойствам этих элементов, при помощи которых и осуществляются необходимые действия.
В следующем фра
|
|
|
