 |


Управление сетевой нагрузкой Интернет
|
|
|
|
До сравнительно недавнего времени задача управления нагрузкой в маршрутизаторах сети Интернет состояла в сбрасывании пакетов при переполнении накопителей. При этом в оконечных системах, в особенности на уровне протокола ТСР, предусматривалось программное обеспечение, которое должно было реагировать на такие события и принимать необходимые меры. Однако в настоящее время в связи с ростом требований к межсетевому взаимодействию разрабатывается ряд новых механизмов и протоколов. В связи с этим в настоящем разделе рассматриваются задачи управления межсетевой нагрузкой.
Протокол IPv4. Начнем с рассмотрения четвертой версии протокола IP, получившей название IPv4. Удобнее всего остановиться на датаграммном варианте заголовка этого протокола, показанного на рис 3.29. Аналогично рис.3.26 здесь размечены 32 разряда, которые составляют содержание каждой строки. Рассмотрим все поля этого заголовка.
· Версия (4 разряда). Указывается номер версии протокола (в данном случае 4, или в записи по двоичной системе счисления 0100).
· Длина заголовка протокола Интернет. Указывается в виде числа 32-разрядных слов (строк на рис 3.29). Максимальная длина заголовка – 5, т.е. 20 октет.
· Тип услуги (8 разрядов). Это поле состоит из двух частей. Первая содержит 3 разряда и сообщает о ресурсах, которые маршрутизатор должен выделить для этой датаграммы. Вторая часть содержит 4 разряда и служит указанием для межсетевого уровня источника или маршрутизатора о выборе направления передачи этой датаграммы (очередного участка). Восьмой разряд принимает значение 0. Фактически первая часть указывает приоритет и расшифровывается следующим образом: 111 – сетевое управление (управляющая информация, касающаяся управления в пределах подсети); 110 – межсетевое управление; 101 – критическое сообщение; 100 – отклонение молнии; 011 – молния; 010 – немедленное сообщение; 001 – приоритетное сообщение; 000 –обычное сообщение. Четыре же разряда второй части несут непосредственную информацию о типе услуги (например, 1000 – минимизировать задержку; 0100 – максимизировать производительность; 0010 – максимизировать надежность; 0001 – минимизировать стоимость; 0000 – обычная услуга).
|
|
|
· Общая длина (16 разрядов). Указывается общая длина датаграммы в октетах.
· Указатель-идентификатор (16 разрядов). Служит для однозначной идентификации датаграммы с помощью порядкового номера (наряду с адресами источника и получателя и протоколом пользователя). В течение всего времени пребывания данного сегмента в сети этот указатель должен быть единственным.
· Флаги (3 разряда). Один из этих флагов служит для указания о фрагментации сообщения. В случае применения фрагментации другой разряд указывает на наличие продолжения.
· Смещение фрагмента (13 разрядов). Указывает место в первоначальной датаграмме, куда относится этот фрагмент (единица измерения – 64 разряда). Это значит, что фрагменты сообщения, кроме последнего, должны содержать поле данных, длина которого кратна 64 разрядам.
· Продолжительность жизни (8 разрядов, по-английски, TTL – Time to Live). Указывает время в секундах, в течение которого датаграмма может находиться в сети Интернет. Любой маршрутизатор, обрабатывающий эту датаграмму, должен уменьшить эту величину, по крайней мере, на единицу. Пакет, у которого продолжительность жизни в сети Интернет истекла, сбрасывается.
· Протокол (8 разрядов). Указывает следующий вышестоящий протокол, который должен принять эти данные в пункте назначения.
· Проверочная сумма заголовка (16 разрядов). Поскольку некоторые поля заголовка могут изменяться в пункте транзита, это поле пересчитывается в каждом маршрутизаторе.
|
|
|
· Адрес источника (32 разряда). Это поле кодируется с целью распределения его длины между адресом сети и адресом подключенного к ней источника (например, 7 и 24 разряда, 14 и 16 разрядов или 21 и 8 разрядов).
· Адрес получателя (32 разряда). Поле строится аналогично полю адреса источника.
· Опции (переменная длина). Поле сообщает об опциях, запрашиваемых передающим пользователем. Среди возможных опций – указатель зашиты, указатель маршрута, запись маршрута, временные метки о прохождении датаграммы (с точностью до миллисекунд).
· Заполнение (переменная длина). Это поле доводит строку до 32 разрядов.
Величина поля данных должна быть кратной 8 разрядам и не превышать вместе с заголовком 216 = 64536 октет. Протокол IPv4 служит основным протоколом стека TCP/IP на протяжении десятилетий, однако в 1996 г. с учетом роста скоростей передачи и разнообразия услуг, включающих передачу графики и видеоизображений, был разработан усовершенствованный вариант этого протокола.
Протокол IPv6. Кроме перечисленных причин, необходимость в новом протоколе была вызвана необходимостью расширения поля адресов. Блок данных протокола IPv6, который часто называют пакетом, содержит заголовок IPv6 (40 октет), несколько функциональных расширений заголовка (необязательных), а после них блок данных транспортного уровня. Хотя заголовок IPv6 вдвое больше заголовка IPv4 (из-за расширения полей адресов), фактически он проще для обработки, так как содержит вместо 12 полей (в случае IPv4) только 8. Рассмотрим заголовок IPv6, показанный на рис.3.30, и остановимся на функциях его полей.
· Версия (4 разряда, в данном случае 0110).
· Приоритет (4 разряда). Характеризует приоритет данного пакета перед другими пакетами этого же источника. Фактически это поле позволяет источнику присваивать каждому пакету две отдельные характеристики приоритета. Первая относит данный пакет к потоку нагрузки, который либо управляется данным источником, либо не управляется. Вторая же часть присваивает каждому пакету, отнесенному к тому или другому потоку, один из восьми уровней приоритета.
· Метка пакета (24 разряда). Устанавливается главной ЭВМ в пакетах, требующих специальной обработки в маршрутизаторах. Если главная ЭВМ или маршрутизатор не используют этого поля, оно устанавливается при формировании пакета на нуль и не изменяется в ходе передачи по сети и на приёме. Если же это поле используется, то все пакеты, передаваемые конкретным источником и имеющие одни и те же адреса источника и назначения, одинаковые приоритеты и одинаковые дополнительные заголовки (заголовки обработки по участкам и маршрутизации, о которых говорится ниже), получают одинаковую ненулевую метку. Задача этой метки состоит в том, чтобы предоставить возможность маршрутизатору обрабатывать такие пакеты, не обращаясь к остальной части заголовка. Источник присваивает эту метку всему потоку, выбирая её случайным образом из 224 – 1 вариантов (за вычетом нулевого). При этом необходимо следить, чтобы одна и та же метка не повторилась в течение времени обработки этого потока в сети.
|
|
|
· Длина сообщения пользователя, или оплачиваемой нагрузки (16 разрядов). Длина содержимого пакета в октетах, которое следует за заголовком IPv6.
· Следующий заголовок (8 разрядов). Указывается тип заголовка, непосредственно следующего за рассматриваемым заголовком. Это может быть одно из расширений заголовка IPv6 (о которых говорится ниже) или заголовок протокола вышестоящего уровня (TCP или UDP).
· Ограничение числа участков (8 разрядов). Остающееся число участков, которые разрешается пройти данному пакету. Ограничение устанавливается источником и уменьшается на единицу в каждом транзитном узле. При исчерпании установленного лимита пакет сбрасывается. Это поле является упрощенным вариантом поля продолжительности жизни в протоколе IPv4.
· Адрес источника (128 разрядов)
· Адрес назначения (128 разрядов). Расширение этих двух полей позволяет структурировать адреса, учитывая их иерархию, доступ к поставщику услуги, географический регион, корпорацию или другие признаки. Подобные объединения позволяют упростить таблицы маршрутизации и их обработку. Новая система позволяет использовать три типа адресов: индивидуальный (unicast), любой из перечня (anycast) или групповой (multicast).
|
|
|
В дополнение к заголовку IPv6 возможны следующие расширения:
· заголовок обработки по участкам (добавляется при необходимости в такой обработке);
· заголовок маршрутизации (добавляется при необходимости расширения маршрута до нескольких адресов);
· заголовок фрагмента (содержит информацию о фрагментации и сборке сообщения);
· заголовок аутентификации (гарантирует целость пакета и аутентификацию);
· заголовок оплачиваемой защиты (обеспечивает услугу гарантии секретности);
· заголовок опций пункта назначения (содержит информацию, которая должна использоваться в пункте назначения).
Указанные расширения могут добавляться к заголовку IPv6 в порядке их перечисления. Исключение составляет последнее расширение, которое может быть вставлено дважды: после заголовка обработки по участкам и в конце. Это делается в случае, если предусмотрен заголовок маршрутизации. Тогда первый заголовок опций используется в первом и всех промежуточных пунктах назначения, а второй – в последнем пункте назначения пакета. При применении каждого из перечисленных расширений заголовка перед ним вставляется небольшое поле, указывающее тип следующего заголовка. Такое поле мы видели в заголовке IPv6.
Интернет-телефония. В заключение рассмотрим работу описанных протоколов при организации телефонной связи по сети Интернет. Традиционная схема телефонной связи предусматривает предоставление разговаривающим абонентам двустороннего канала, который в случае связи на большие расстояния является четырехпроводным. А поскольку в каждый момент времени обычно говорит только один из двух абонентов, использование каждого двухпроводного канала, служащего для передачи речи в одном направлении, оказывается не выше 40%. В сети же Интернет передаются речевые пакеты независимо в каждом направлении, и формируются такие пакеты только в моменты речевой активности абонента.
Важнейшими отличительными особенностями телефонных соединений по сети Интернет являются следующие.
1. Нагрузка в сети Интернет более трудно предсказуема, чем в традиционной телефонной сети. Это объясняется не только тем, что нагрузка сети Интернет более разнообразна, но и тем, что даже телефонная нагрузка определяется не просто количеством установленных телефонных соединений, а количеством пакетов, которые передаются только в моменты речевой активности.
2. Маршрутизаторы и каналы в сети Интернет не столь надежны, как коммутаторы и телефонные каналы, поэтому поддержание телефонной связи в сети Интернет является более трудной задачей.
|
|
|
3. В различных доменах сети Интернет могут существовать свои принципы работы, а это затрудняет измерение нагрузки и выбор стратегии управления.
4. Разговорное соединение требует гарантий качества обслуживания. В сети же Интернет для гарантии качества недостаточно принять заявку на обслуживание. Это еще не обеспечивает уверенности в том, что на всем пути передачи пакетов будут доступны необходимые ресурсы.
В дополнение к сказанному заметим, что под Интернет-телефонией часто имеют в виду даже более широкий набор речевых услуг, к которым относятся:
1. Обычная телефонная связь между пользователями ЭВМ, включенными в сеть Интернет, с возможностью найти нужный номер в справочнике через сеть Интернет и осуществить его автоматический набор;
2. Телефонная связь с мобильной ЭВМ через сеть Интернет, например, для получения нужных справок с возможностью обмена сообщениями по электронной почте;
3. Связь через шлюз телефонной сети с традиционным абонентом телефонной сети общего пользования; при этом можно выйти в телефонную сеть общего пользования как можно ближе к вызываемому абоненту и тем самым избежать оплаты междугородного разговора;
4. Доступ к информационному центру, позволяющий получить одновременно с телефонным разговором самую разнообразную информацию.
Обычно один пакет содержит сегмент речевого сигнала продолжительностью 20 мс. При цифровой передаче речи с ИКМ за это время проходят 160 отсчетов речевого сигнала. Каждый отсчет кодируется с помощью восьми двоичных разрядов, и в этом случае всего в пакете должно быть передано 1280 двоичных разрядов, или 160 октет. Таким образом, полезная информация, которая должна быть передана с помощью одного пакета, содержит 1280 двоичных разрядов, или 160 октет. Для передачи по сети Интернет эта информация должна пройти обработку от прикладного до физического уровня, и на каждом уровне к ней добавляется заголовок соответствующего протокола. Например, на транспортном уровне сети Интернет наибольшее распространение получили протоколы ТСР и UDP. Первый из них, как мы видели, работает с установлением соединений и является более сложным, а второй работает без установления соединений (в режиме передачи датаграмм) и более прост. Однако оба эти протокола недостаточно гарантируют качество обслуживания при передаче речи и, кроме того, не поддерживают многоадресную передачу (например, при конференц-связи). Поэтому в современной сети Интернет находит применение протокол RTP, который, строго говоря, не является полным протоколом транспортного уровня. Он включает некоторые функции прикладного уровня и рассчитан на работу без установления соединения с помощью протокола UDP. Следующим нижестоящим уровнем является уровень межсетевого взаимодействия, на котором работает протокол IP.
В качестве примера на рис.3.31 показан один из возможных процессов формирования речевого пакета. В рассматриваемом случае к блоку данных, несущему речевой сигнал в цифровой форме, последовательно добавляются заголовки протоколов RTP, UDP и IP. Как показывает разметка в верхней части рисунка, каждая строка содержит по 32 двоичных разряда, т.е. по четыре октета. Заголовки трех упомянутых протоколов и функции их полей были рассмотрены выше. Здесь обратим внимание на поле типа нагрузки заголовка протокола RTP, которое содержит информацию о среде передачи и формате данных, а также о сжатии и шифровании информации. Код этого поля берется из утвержденной таблицы, в которой перечислены 128 наименований различных режимов работы. В этот список включены, в частности, такие виды передачи, как звук ИКМ (рассматриваемый здесь случай, код 0000000), звук GSM, неоговоренная передача звука, и многие другие. Всю вторую строку занимает поле метки времени(32 разряда), которая указывает момент появления первого октета данных пользователя. Эта метка контролирует в маршрутизаторах время пребывания пакета в сети. При превышении допустимого времени пребывания в сети пакет сбрасывается вследствие его бесполезности. После заголовка протокола RTP добавляется заголовок протокола UDP, а затем заголовок протокола IP (в данном случае версия IPv4). Что касается информационного поля, содержащего отрезок речевого сигнала продолжительностью 20 мс, то в нем, в случае применения кодирования GSM, вместо 160 октет придется передать всего 20 октет.
Функции выбора маршрутов
Функция выбора маршрута является важной задачей сетевого уровня любой архитектуры управления сетью, поэтому его рассмотрению посвятим специальный раздел. Путь следования пакетов может быть ограничен установленным виртуальным каналом или же пакеты могут передаваться в датаграммном режиме. В любом случае для связи заданного источника с заданным получателем должен быть установлен маршрут или набор маршрутов. Обычно подходящий маршрут фиксируется в каждом узле, находящемся на пути следования данного маршрута, с помощью записи в маршрутной таблице, которая показывает, по какому исходящему каналу должен быть направлен данный пакет. В результате пакет с идентифицирующей информацией (это могут быть адреса источника и получателя, номер виртуального канала, для некоторых процедур – только адрес получателя, и т.д.) направляется на основании записи в маршрутной таблице по соответствующему исходящему каналу. В настоящем разделе рассматриваются некоторые алгоритмы, применяемые для выбора необходимых путей и формирования маршрутных таблиц в каждом узле по ходу этих путей. В литературе можно найти очень много описаний различных алгоритмов управления процессами выбора маршрутов и их классификации. Например, алгоритмы могут классифицироваться по тому, устанавливаются ли пути централизованно или децентрализованно. Они могут классифицироваться по свойствам адаптации (например, статический алгоритм или динамический алгоритм, реагирующий на изменения нагрузки). Большинство алгоритмов основано на учете меры «стоимости», приписываемой каждой линии. Эта мера может учитывать такие характеристики, как длина линии, скорость передачи (или ширина полосы), безопасность, оцениваемая задержка при передаче сигнала, причем могут учитываться и некоторые сочетания перечисленных характеристик. Стоимость может также отражать среднюю нагрузку в определенные часы, и т.д. Наконец, алгоритмы могут классифицироваться на основании объективных характеристик.
Наиболее часто в литературе обсуждаются два класса алгоритмов. Первый класс, называемый классом алгоритмов кратчайшего пути, обеспечивает выбор для каждой пары «источник-получатель» пути наименьшей стоимости. Второй класс алгоритмов обеспечивает выбор маршрутов, минимизирующих среднюю задержку в целом по сети на основании оценки средней нагрузки в сети. Применение такого критерия обычно приводит к многообразию маршрутов для пакетов, передаваемых между заданной парой «источник-получатель». Поэтому второй класс алгоритмов часто называют альтернативным выбором маршрутов. Современная техника связи в процессе её интенсивного развития может востребовать любой из методов, рассмотренных в литературе. Для систематизированного изучения работы маршрутизаторов удобно начать с фиксированной маршрутизации. Рассмотрим сначала два широко применяемых алгоритма выбора кратчайших путей. Действие обоих алгоритмов рассмотрим на примере сети, структура которой и стоимости участков показаны на рис. 3.32. Для простоты будем предполагать, что стоимости передачи в обоих направлениях одинаковы, хотя в общем случае могут быть заданы разные стоимости для каждого направления. Ограничимся рассмотрением только процесса нахождения кратчайших путей для узла 1, так как для всех остальных узлов повторяется аналогичная процедура.
Алгоритмы выбора кратчайших путей. Каждый из двух рассматриваемых алгоритмов состоит из начального этапа и последовательности итераций. Первый из них носит название алгоритма Дейкстры (по имени его автора голландца E.W. Dijkstra). Этот алгоритм позволяет найти кратчайшие пути от узла-источника ко всем другим узлам сети путем последовательного выявления кратчайших путей в порядке возрастания их длины. Для этого требуется знать глобальную структуру сети (т.е. список всех узлов сети и их взаимосвязей), а также стоимости всех линий. Алгоритм может служить для централизованных вычислений с полной информацией о структуре сети, имеющейся в центральной базе данных. Но этот же алгоритм может служить основой и для децентрализованных вычислений, которые применялись в сети ARPA, где каждый узел поддерживал собственную глобальную базу данных. Алгоритм решает задачу выбора путей поэтапно, строя дерево кратчайших путей с корнем в узле-источнике, пока не будет охвачен самый удаленный узел. Обозначим через D(v) расстояние (сумму стоимостей линий вдоль данного пути) от узла-источника 1 до узла v. Пусть l(i,j) – заданная стоимость пути между узлами i и j. Алгоритм состоит из начального шага и итераций, повторяющихся до завершения алгоритма.
1. Начальный этап. Устанавливаем множество узлов N = {1}. Для каждого узла v, не принадлежащего множеству N, устанавливаем D(v) = l(1,v). При этом расстояния до узлов, не имеющих соединения с узлом 1, принимаем равным 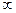 (практически можно принять любое достаточно большое число).
(практически можно принять любое достаточно большое число).
2. Отдельная итерация (на каждом последующем этапе). Находим не принадлежащий множеству N узел w, для которого D(w) минимально, и включаем узел w в множество N. После этого обновляем значения D(w) для всех остальных узлов, не принадлежащих множеству N путем вычисления по следующей формуле
D(v) Min [ D(v), D(w) + l(w,v)].
Второй этап повторяется до тех пор, пока в множество N не войдут все узлы сети. В качестве примера в таблице 3.9 приводятся результаты вычислений по приведенному
алгоритму для сетевого узла 1. Полужирные цифры в столбцах обозначают минимальные значения D(w) на каждом этапе, причем при наличии одинаковых значений выбор производится случайным образом. После каждого этапа соответствующий узел w добавляется в множество N. Затем величины D(v) обновляются. Например, после начального этапа во время этапа 1 к множеству N добавляется узел 4, имеющий минимальное значение D(4) = 1. На этапе 2 в множество N включается узел 5 при D(5) =
2, хотя на этом этапе можно было бы включить вместо узла 5 узел 2, для которого также
Таблица 3.9. Применение алгоритма Дейкстры к первому узлу сети рис. 3.30.
| Этап | Множество N | D(2) | D(3) | D(4) | D(5) | D(6) |
| Начальный | {1} |
|
| |||
| {1,4} |
| |||||
| {1,4,5} | ||||||
| {1,2,4,5} | ||||||
| {1,2,3,4,5} | ||||||
| {1,2,3,4,5,6} |
D(2) = 2. Выбор сделан случайным образом, но это не повлияет на окончательный результат. После шага 5 все узлы оказываются включенными в множество N, и алгоритм завершается. Таким образом, в ходе каждой итерации к множеству N добавляется один узел v, а величина D(v) в это время указывает длину кратчайшего пути от узла 1 до узла v, который проходит только через узлы, уже включенные во множество N.
По ходу работы алгоритма строится дерево кратчайших путей, показанное на рис. 3.33а. Цифры в скобках у каждого узла указывают шаг, на котором этот узел был включен в дерево. С помощью дерева кратчайших путей для узла 1 можно получить таблицу маршрутов для этого узла, показывающую исходящий путь, по которому нужно направлять пакеты к узлу назначения. (рис. 3.33б). Подобная таблица составляется для каждого узла. При этом в случае централизованных вычислений каждая таблица затем направляется в соответствующий узел. В случае же децентрализованного, или распределенного, выбора маршрутов, каждый узел выполняет вычисления, используя ту же самую глобальную информацию и генерируя собственное дерево и соответствующую таблицу маршрутов.
Перейдем к рассмотрению второго алгоритма, известного под названием алгоритма Форда-Фалкерсона (или Беллмана-Форда). Этот алгоритм находит кратчайшие пути от данной вершины-источника при последовательно применяемом ограничении, которое требует, чтобы пути содержали самое большее один участок, самое большее два участка, и т.д. Он также состоит из двух частей: начального этапа и отдельных итераций, которые повторяются до завершения алгоритма и в ходе которых вычисляются кратчайшие расстояния. Рассмотрим применение этого алгоритма на том же примере сети рис. 3.32. Здесь кратчайшее расстояние представляет собой расстояние до данного узла от узла 1, рассматриваемого как узел назначения. Алгоритм заканчивается, когда для всех узлов фиксируется их расстояние до узла 1 (узла получателя) и отмечаются следующие узлы по направлению к узду назначения по кратчайшему пути. Построение таблицы маршрутов с использованием алгоритма Форда-Фалкерсона требует повторного или параллельного применения этого алгоритма для каждого узла назначения, что даёт в результате набор меток для каждого узла. Метка содержит информацию о маршруте (т.е. следующем узле) и расстоянии до конкретного узла назначения. Иначе говоря, каждый узел v имеет метку {n, D(v)}, где D(v) представляет текущую величину кратчайшего расстояния от рассматриваемого узла до узла получателя, а n – номер следующего узла по текущему рассчитанному кратчайшему пути. Ниже дается описание алгоритма.
1. Начальный этап. Если узлом назначения является узел 1, то устанавливаем значение D(1) = 0 и метки для всех остальных узлов в виде (×, ).
2. Отдельная итерация (отметка кратчайшего расстояния для всех узлов).
Для каждого узла v ¹ 1 выполняется следующее: обновляются величины
D(v) путем использования текущего значения D(w) для каждого соседнего
узла w и вычисления величины D(v)+l(w,v) с последующим выполнением
операции

Таблица 3.10. Применение алгоритма Беллмана-Форда
| Этап | |||||
| Начальный | (×, )
| (×, )
| (×, )
| (×, )
| (×, )
|
| (1,2) | (1,5) | (1,1) | (4,2) | (5,4) | |
| (1,2) | (5,3) | (1,1) | (4,2) | (5,4) |
Метка v обновляется путем замены n номером смежного узла, что минимизирует приведенное выражение, и путем замены D(v) вновь полученным значением. Операция повторяется для каждого узла, пока не прекратятся дальнейшие изменения. В результате во всех узлах фиксируются метки как об их кратчайших расстояниях от узла 1, так и до следующего соседнего узла по кратчайшему пути. В таблице 3.10 приводятся пример расчета меток для узлов 2 – 6 сети, представленной на рис. 3.32, согласно описанному алгоритму. Обращаясь ко второй части алгоритма и применяя её в циклическом порядке 2-6, находим, что алгоритм завершается после двух циклов, причем любой порядок обхода узлов приводит к одному и тому же окончательному результату. Отметим, что на этапе 1 «ближайшим» к узлу 1 является узел 2, для которого новая результирующая стоимость равна D(v) = D(1) + l(1.2) = 2. Поэтому метка, как указано в таблице, имеет вид (1.2).
Переходя к узлу 3, приходим к необходимости выбора стоимости между D(2) + l(2,3) = 5 и D(1) + l(1,3) = 5. Выбирая произвольно D(1)+ l(1,3), получим (1,5), что и показано в таблице (при другом выборе получится то же самое). Аналогично получаются другие результаты. На этапе 2 узел 3 имеет пять соседних узлов с конечными значениями D(w), между которыми и нужно произвести выбор. Минимальное значение D(w) + l(w,3) равно D(5) + l(5,3) = 3, и метка узла 3, как показано в таблице, меняется на (5,3). Другие узлы не меняют своих меток, и алгоритм завершается. Дерево кратчайших путей, показанное на рис. 2.33, может быть получено путем обхода меток каждого узла. В результате, узел 2 соединяется с узлом 1, узел 3 – с узлом 5, узел 4 – с узлом 1, узел 5 – с узлом 4 и узел 6 – с узлом 5. Иначе говоря, таблица маршрутов, или значение следующего узла, в каждом узле по направлению к узлу 1 в точности является первым числом каждой двузначной метки. Для получения полной таблицы маршрутов в каждом узле алгоритм Форда-Фалкерсона должен быть повторен для каждого узла, принимаемого в качестве узла назначения.
В заключение интересно провести сравнение между двумя рассмотренными алгоритмами по объёму используемой ими информации. Рассмотрим сначала алгоритм Форда-Фалкерсона. Чтобы вычислить метку для узла v, необходимо знать стоимости всех участков к соседним узлам, т.е. l(w,v), плюс общие стоимости путей к каждому соседнему узлу. Каждый узел должен поддерживать информацию о путях к каждому другому узлу сети и их стоимостях, а также время от времени обмениваться этой информацией со своими непосредственными соседями. Таким образом, каждый узел для обновления информации о путях и их стоимостях использует на этапе 2 формулу алгоритма Форда-Фалкерсона, основываясь только на информации от соседних узлов и знании стоимостей соответствующих участков. С другой стороны, рассматривая алгоритм Дейкстры, видим, что здесь на этапе 3 в каждом узле должна быть известна полная информация о структуре сети. Иначе говоря, каждый узел должен располагать информацией обо всех участках сети. Следовательно, при использовании этого алгоритма узел должен осуществлять обмен информацией со всеми остальными узлами сети.
В общем случае при оценке относительных достоинств двух рассмотренных алгоритмов должно учитываться время работы алгоритма и количество информации, которая должна собираться от других узлов сети или целой группы взаимодействующих сетей. Эта оценка будет зависеть от используемых подходов и конкретной реализации. И, наконец, последнее замечание. Оба алгоритма сходятся при поддержании статического режима работы сети и стоимостей участков к одному и тому же решению. Если же стоимости участков изменяются во времени, алгоритм будет пытаться учитывать эти изменения. Однако если стоимости участков зависят от нагрузки, которая, в свою очередь, зависит от выбора маршрутов, тогда возникает обратная связь, в результате чего возможна нестабильная работа сети.
Практические протоколы маршрутизации. Архитектура современной сети Интернет строится как объединение небольшого числа магистральных сетей. Таких сетей в мире порядка 10 - 12. В свою очередь, каждая магистральная сеть состоит из сетей с коммутацией пакетов, которые обслуживаются региональными или местными поставщиками информационных услуг. Исходя из этого представления, целесообразно ввести понятие автономной системы. Так называется сеть, содержащая группу маршрутизаторов, которые обмениваются информацией по единому протоколу. Эта сеть управляется одной администрацией и является связной (если не говорить о случаях повреждений). Протокол, работающий внутри автономной системы, называется протоколом внутренней маршрутизации. Протокол же, обеспечивающий установление маршрутов через разные автономные системы, называется протоколом внешней маршрутизации. При такой организации можно рассчитывать на то, что протокол внешней маршрутизации потребует передачи меньшего объёма информации, чем протокол внутренней маршрутизации, так как первый имеет дело не с конкретными главными ЭВМ, а с целыми автономными системами.
К протоколам внутренней маршрутизации относятся протокол маршрутной информации RIP (по-английски Routing Information Protocol) и протокол, первоочередно выбирающий свободный кратчайший путь OSPF (Open Shortest Path First). К протоколам же внешней маршрутизации относится протокол пограничного шлюза DGP (по-английски Border Gateway Protocol) и протокол маршрутизации между доменами IDRP (Inter-Domain Routing Protocol). Остановимся на кратком рассмотрении перечисленных протоколов.
Сравнительно простым протоколом внутренней маршрутизации является протокол RIP, получивший широкое распространение в небольших сетях. Этот протокол работает по принципу дистанционно-векторной маршрутизации. Каждый узел сети обменивается с соседними узлами векторами расстояний. Алгоритм дистанционно-векторной маршрутизации предусматривает хранение и обновление в каждом узле x трех векторов. Во-первых, это вектор стоимостей участков
Wx =  ,
,
где М – число подсетей, с которыми узел х имеет непосредственную связь. Если главная ЭВМ связана только с одной подсетью, этот вектор превращается в одно число.
Во-вторых, это вектор расстояний до узла х
Lx =  ,
,
где N – общее число подсетей в рассматриваемой структуре, и, в-третьих,
вектор следующих участков для узла х
Rx =  ,
,
где R(x,j) – следующий маршрутизатор в текущем маршруте с минимальной задержкой от узла x до сети j. Периодически (каждые 30 секунд) каждый узел обменивается векторами расстояний со всеми узлами-соседями. На основе получаемой информации узел х обновляет оба вектора с помощью алгоритма Форда-Фалкерсона. С увеличением размеров и скоростей передачи в сети Интернет недостатки протокола RIP становятся очевидны, поэтому на его смену приходит протокол OSPF, основанный на учете состояния участков.
При запуске маршрутизатора протокол OSPF определяет стоимость участков на каждом интерфейсе. После этого стоимости передаются всем маршрутизаторам рассматриваемой сети (не только соседям!). Каждый маршрутизатор проверяет имеющиеся у него стоимости участков. Если произошло изменение (существенно изменилась стоимость, возник новый участок, оказался недоступным существовавший участок), маршрутизатор снова сообщает стоимости участков всем маршрутизаторам сети. Поскольку в рассматриваемом случае каждый маршрутизатор получает информацию о стоимости всех участков сети, он может самостоятельно построить структуру сети и рассчитать кратчайшие пути к каждой сети назначения. Выполнив эту работу, маршрутизатор строит таблицу маршрутов. Поскольку в маршрутизаторе оказывается представленной вся сеть, он может определить кратчайшие пути, воспользовавшись алгоритмом Дейкстры.
Протокол маршрутизации, учитывающий состояния участков, работает по так называемому волновому методу. Этот метод не требует никакой предварительной информации о структуре сети и работает следующим образом. Маршрутизатор источника направляет пакет всем своим соседям. Каждый соседний маршрутизатор, получив пакет, ретранслирует его по всем исходящим участкам, кроме того, по которому поступил данный пакет. При этом каждый узел запоминает ретранслированные им пакеты, и при повторном получении такого пакета сбрасывает его. В результате оказываются опробованными все возможные маршруты между пунктами отправления и назначения. При этом в пункт назначения поступит, по крайней мере, одна копия пакета, поступившая по пути с минимальной задержкой.
Если по протоколу RIP каждый маршрутизатор передает маршрутную информацию только своим соседям, то по протоколу OSPF эта информация передаётся всем маршрутизаторам сети. В протоколе RIP передаваемая информация содержит данные о стоимости путей до всех подсетей. Протокол же OSPF предусматривает передачу только стоимостей участков до смежных подсетей. По протоколу RIP обмен информацией между маршрутизаторами происходит регулярно с конкретной периодичностью. Протокол же OSPF предусматривает обмен информацией лишь при возникновении изменений в сети. Ни дистанционно-векторный протокол, ни протокол, учитывающий состояния участков, не могут эффективно работать при внешней маршрутизации. Дистанционно-векторный протокол рассчитан на то, что каждый маршрутизатор работает с единой системой метрик и едиными приоритетами, которые действуют во всей сети. В крупной же сети ни то ни другое условие могут не соблюдаться. Протокол же, учитывающий состояния участков, также ориентирован на единую систему меток и, кроме того, волновой метод распространения информации в большой сети может стать неуправляемым.
Особенностью протоколов внешней маршрутизации является то, что они работают с векторами путей. Вектор пути перечисляет автономные системы, через которые должна пройти датаграмма, следующая по конкретному маршруту. К этому типу протоколов относится протокол BGP, разработанный для сети Интернет, в ко
|
|
|
