 |


Способность к обучению на примерах
|
|
|
|
План лекции
Определение ИНС.
Трудноалгоритмизуемые задачи. Пример – распознавание образов.
Отличие в работе мозга и обычной вычислительной машины: способность к обучению и обобщению, параллельность обработки информации, надежность.
Строение мозга, биологический нейрон, нервный импульс.
Формальный нейрон.
Виды сетей: полносвязные, многослойные и т.д.
Многослойные сети: задача классификации.
Многослойные сети: задача аппроксимации.
Виды алгоритмов обучения.
Алгоритм обратного распространения.
Введение
 |
Начнем с определения: Искусственные нейронные сети (ИНС) – вид математических моделей, которые строятся по принципу организации и функционирования их биологических аналогов – сетей нервных клеток (нейронов) мозга. В основе их построения лежит идея о том, что нейроны можно моделировать довольно простыми автоматами (называемыми искусственными нейронами), а вся сложность мозга, гибкость его функционирования и другие важнейшие качества определяются связями между нейронами.
Рис. 1. Задача выделения и распознавания объектов на картинке (дерево, кошка) – пример трудноалгоритмизуемой задачи.
История ИНС начинается с 1943 года, когда У. Маккалок и У. Питтс предложили первую модель нейрона и сформулировали основные положения теории функционирования человеческого мозга. С тех пор теория прошла довольно большой путь, а что касается практики, то годовой объем продаж на рынке ИНС в 1997 году составлял 2 млрд. долларов с ежегодным приростом в 50%.
Спрашивается, зачем нужны нейронные сети. Дело в том, что существует множество задач, которые трехлетний ребенок решает лучше, чем самые мощные вычислительные машины. Рассмотрим, например задачу распознавания образов. Пусть у нас есть некоторая картинка (дерево и кошка). Требуется понять, что на ней изображено и где. Если вы попробуете написать программу решающую данную задачу, вам придется, последовательно перебирая отдельные пиксели этой картинки, в соответствии с некоторым критерием решить, какие из них принадлежат дереву, какие кошке, а какие ни тому, ни другому. Сформулировать же такой критерий, что такое дерево, – очень нетривиальная задача.
|
|
|
Тем ни менее мы легко распознаем деревья, и в жизни и на картинках, независимо от точки зрения и освещенности. При этом мы не формулируем никаких сложных критериев. В свое время родители показали нам, что это такое, и мы поняли. На этом примере можно сформулировать несколько принципиальных отличий в обработке информации в мозге и в обычной вычислительной машине:
Способность к обучению на примерах
Способность к обобщению. То есть мы, не просто запомнили все примеры виденных деревьев, мы создали в мозгу некоторый идеальный образ абстрактного дерева. Сравнивая с ним любой объект, мы сможем сказать, похож он на дерево или нет.
Еще одно видное на этой задаче отличие это параллельность обработки информации. Мы не считываем картинку по пикселям, мы видим ее целиком и наш мозг целиком ее и обрабатывает.
Еще, что хотелось бы добавить к этому списку отличий это поразительная надежность нашего мозга. К старости некоторые структуры мозга теряют до 40% нервных клеток. При этом многие остаются в здравом уме и твердой памяти.
Наконец еще, что хотелось отметить – это ассоциативность нашей памяти. Это способность находить нужную информацию по ее малой части.
Хотелось бы понять, какие именно особенности организации позволяют мозгу работать столь эффективно. Рассмотрим вкратце, как он устроен. Все, наверное, знают, что мозг состоит из нервных клеток (нейронов). Всего их ~1012 штук.
|
|
|

Рис. 2. Биологический нейрон.
Изобразим схематично отдельный нейрон. Он имеет один длинный, ветвящийся на конце отросток – аксон и множество мелких ветвящихся отростков – дендритов. Известно, что в ответ на возбуждение нейрон может генерировать нервный импульс, распространяющийся вдоль аксона. О его природе вам должны были рассказывать в курсе биофизики. То есть это волна деполяризации мембраны нейрона. Она является автоволной, то есть ее форма и скорость распространения не зависят от того, как и из-за чего она возникла. Доходя до конца аксона, она вызывает выделение веществ, называемых нейромедиаторами. Воздействуя на дендриты других нейронов, они могут в свою очередь вызвать появление в них нервных импульсов.
Давайте запишем, что нейрон является типичным элементом, действующим по принципу «все или ничего». Когда суммарный сигнал, приходящий от других нейронов, превышает некоторое пороговое значение, генерируется стандартный импульс. В противном случае нейрон остается в состоянии покоя.
 |
Биологический нейрон – сложная система, математическая модель которой до конца не построена. Как я уже говорил в самом начале в основе теории ИНС лежит предположение о том, что вся эта сложность несущественна, а свойства мозга объясняются характером их соединения. Поэтому вместо точных математических моделей нейронов используется простая модель так называемого формального нейрона.
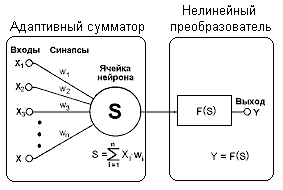
Рис. 3. Искусственный нейрон.
Он имеет входы, куда подаются некоторые числа  . Затем стоит блок, называемый адаптивным сумматором. На его выходе мы имеем взвешенную сумму входов:
. Затем стоит блок, называемый адаптивным сумматором. На его выходе мы имеем взвешенную сумму входов:
. (1)
Затем она подается на нелинейный преобразователь и на выходе мы имеем:
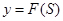 . (2)
. (2)
Функция F нелинейного преобразователя называется активационной функцией нейрона. Исторически первой была модель, в которой в качестве активационной функции использовалась ступенчатая функция или функция единичного скачка:
 (3)
(3)
То есть по аналогии с биологическим нейроном, когда суммарное воздействие на входе превысит критическое значение, генерируется импульс 1. Иначе нейрон остается в состоянии покоя, то есть выдается 0.
|
|
|
Существует множество других функций активации. Одной из наиболее распространенных является логистическая функция (сигмоид).
(4)
При уменьшении a сигмоид становится более пологим, в пределе при a=0 вырождаясь в горизонтальную линию на уровне 0.5, при увеличении a сигмоид приближается по внешнему виду к функции единичного скачка с порогом в точке x=0. Одно из ценных свойств сигмоидной функции – простое выражение для ее производной, применение которого будет рассмотрено в дальнейшем.
(5)
Теперь рассмотрим, как из таких нейронов можно составлять сети из таких нейронов. Строго говоря, как угодно, но такой произвол слишком необозрим. Поэтому выделяют несколько стандартных архитектур, из которых путем вырезания лишнего или добавления строят большинство используемых сетей. Можно выделить две базовые архитектуры: полносвязные и многослойные сети.
В полносвязных нейронных сетях каждый нейрон передает свой выходной сигнал остальным нейронам, в том числе и самому себе. Все входные сигналы подаются всем нейронам. Выходными сигналами сети могут быть все или некоторые выходные сигналы нейронов после нескольких тактов функционирования сети.
В многослойных нейронных сетях (их часто называют персептронами) нейроны объединяются слои. Слой содержит совокупность нейронов с едиными входными сигналами. Число нейронов в слое может быть любым и не зависит от количества нейронов в других слоях. В общем случае сеть состоит из нескольких слоев, пронумерованных слева на право. Внешние входные сигналы подаются на входы нейронов входного слоя (его часто нумеруют как нулевой), а выходами сети являются выходные сигналы последнего слоя. Кроме входного и выходного слоев в многослойной нейронной сети есть один или несколько так называемых скрытых слоев.
В свою очередь, среди многослойных сетей выделяют:
 |
Сети прямого распространения (feedforward networks) – сети без обратных связей. В таких сетях нейроны входного слоя получают входные сигналы, преобразуют их и передают нейронам первого скрытого слоя, и так далее вплоть до выходного, который выдает сигналы для интерпретатора и пользователя. Если не оговорено противное, то каждый выходной сигнал n-го слоя передастся на вход всех нейронов (n+1) - го слоя; однако возможен вариант соединения n-го слоя с произвольным (n+p) - м слоем. Пример слоистой сети представлен на рисунке 4.
|
|
|
2. Сети с обратными связями (recurrent networks). В сетях с обратными связями информация передается с последующих слоев на предыдущие. Следует иметь в виду, что после введения обратных связей сеть уже не просто осуществляет отображение множества входных векторов на множество выходных, она превращается в динамическую систему и
 |
возникает вопрос об ее устойчивости.
Теоретически число слоев и число нейронов в каждом слое может быть произвольным, однако фактически оно ограничено ресурсами компьютера или специализированных микросхем, на которых обычно реализуется нейросеть. Чем сложнее сеть, тем более сложные задачи она может решать.
Рассмотрим более подробно свойства многослойных нейронных сетей прямого распространения. Зададимся вопросом, какие задачи может решать подобная нейросеть?
1. Задача классификации.
 |
Рассмотрим более подробно, что делает один формальный нейрон в самом простом случае, когда его функцией активации является ступенька.
Рис. 5. Нейрон с пороговой функцией активации разделяет пространство входов гиперплоскостью на две части.
Он дает на выходе 1 если 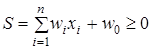 и 0 если
и 0 если  . Таким образом, он разбивает пространство входов на две части с помощью некоторой гиперплоскости. Если у нас всего два входа, то это пространство двухмерно и нейрон будет разбивать его с помощью прямой линии. Это разбиение определяется весовыми коэффициентами
. Таким образом, он разбивает пространство входов на две части с помощью некоторой гиперплоскости. Если у нас всего два входа, то это пространство двухмерно и нейрон будет разбивать его с помощью прямой линии. Это разбиение определяется весовыми коэффициентами  нейрона.
нейрона.
 |
Если мы теперь составим из N таких нейронов слой, то получим разбиение пространства входов N гиперплоскостями. Каждой области в этом пространстве будет соответствовать некий набор нулей и единиц, формирующийся на выходе нашего слоя.
Рис. 6. Кошка, характеризуемая ее линейными размерами.
Таким образом, такая нейронная сеть пригодна для решения задачи многомерной классификации или распознавания образов. Допустим у нас есть некий объект, имеющий набор свойств  . Это может быть, скажем, кошка, характеризуемая ее линейными размерами. Мы можем подать эти параметры на вход нашей сети и сказать, что определенная комбинация нулей и единиц на выходе соответствует объекту «кошка». Таким образом, наша сеть способна выполнять операцию распознавания.
. Это может быть, скажем, кошка, характеризуемая ее линейными размерами. Мы можем подать эти параметры на вход нашей сети и сказать, что определенная комбинация нулей и единиц на выходе соответствует объекту «кошка». Таким образом, наша сеть способна выполнять операцию распознавания.
Рис. 7. Простая задача распознавания – линейно разделимые множества.
|
|
|
 |
Однако очевидно, что не для всякой задачи распознавания, существует однослойная сеть ее решающая. Хорошо, если у нас, например, стоит задача различения кошек и собак, причем распределение точек в пространстве параметров такое, как показано на рисунке, когда достаточно провести одну линию (или гиперплоскость) чтобы разделить эти два множества. Тут достаточно одного нейрона.
 |
В более общем случае такое невозможно, например, как на рис.7. В этом случае мы можем использовать слой нейронов, но одному множеству (скажем, кошка) будет соответствовать уже не одна, а множество комбинаций нулей и единиц.
Рис. 8. Задача распознавания с линейно неразделимыми множествами.
Если мы теперь выходы нашего первого слоя нейронов используем в качестве входов для нейронов второго слоя, то нетрудно убедиться, что каждая комбинация нулей и единиц на выходе второго слоя может соответствовать некоему объединению, пересечению и инверсии областей, на которые пространство входов разбивалось первым слоем нейронов. Двухслойная сеть, таким образом, может выделять в пространстве входов произвольные выпуклые односвязные области.
В случае еще более сложной задачи, когда требуется различать многосвязные области произвольной формы, всегда достаточно трехслойной сети.
Мы видим, что нейронные сети с пороговыми функциями активации способны решить произвольную задачу многомерной классификации.
2. Аппроксимация функций.
Вторая задача, которую мы рассмотрим это задача аппроксимации функций. Рассмотрим теперь сеть, нейроны которой в качестве функции активации имеют не ступеньку, а некоторую непрерывную функцию, например, сигмоид. В этом случае выход сети будет некоторой непрерывной функцией ее входов. Конкретный вид этой функции определяется весовыми коэффициентами каждого из нейронов.
Возникает вопрос, какие функции могут быть аппроксимированы с помощью нейронной сети? Ответ дается обобщенной теоремой Стоуна. Не вдаваясь в математические тонкости ее можно интерпретировать как утверждение об универсальных аппроксимационных возможностях произвольной нелинейности: с помощью линейных операций и каскадного соединения можно из произвольного нелинейного элемента получить устройство, вычисляющее любую непрерывную функцию с любой наперед заданной точностью.
То есть нейросеть с произвольной функцией активации может аппроксимировать произвольную непрерывную функцию. При этом, как оказывается всегда достаточно трехслойной сети. Нужна большая точность – просто добавь нейронов.
Как частный случай задачи аппроксимации можно рассмотреть задачу предсказания временных рядов. На вход сети мы подаем некоторое количество предыдущих значений, затем, а на выходе ожидаем получить значение в следующий момент времени.
Мы рассмотрели некоторые возможности только многослойных сетей прямого распространения. Ясно, что они могут практически все, что угодно. Возникает вопрос, как подобрать такие весовые коэффициенты, чтобы сеть решала задачу распознавания или аппроксимировала некоторую функцию? Замечательное свойство нейронных сетей состоит в том, что их этому можно научить.
Алгоритмы обучения бывают 3-х видов:
Обучение с учителем. При этом сети предъявляется набор обучающих примеров. Каждый обучающий пример представляют собой пару: вектор входных значений и желаемый выход сети. Скажем, для обучения предсказанию временных рядов это может быть набор нескольких последовательных значений ряда и известное значение в следующий момент времени. В ходе обучения весовые коэффициенты подбираются таким образом, чтобы по этим входам давать выходы максимально близкие к правильным.
Обучение с поощрением. При этом сети не указывается точное значение желаемого выхода, однако, ей выставляется оценка хорошо она поработала или плохо.
Обучение без учителя. Сети предъявляются некоторые входные векторы и в ходе их обработки в ней происходят некоторые процессы самоорганизации, приводящие к тому, что сеть становиться способной решать какую-то задачу.
Рассмотрим один из самых популярных алгоритмов обучения, так называемы, алгоритм обратного распространения. Это один из вариантов обучения с учителем. Пусть у нас имеется многослойная сеть прямого распространения со случайными весовыми коэффициентами. Есть некоторое обучающее множество, состоящее из пар вход сети – желаемый выход  . Через Y обозначим реальное выходное значение нашей сети, которое в начале практически случайно из-за случайности весовых коэффициентов.
. Через Y обозначим реальное выходное значение нашей сети, которое в начале практически случайно из-за случайности весовых коэффициентов.
Обучение состоит в том, чтобы подобрать весовые коэффициенты таким образом, чтобы минимизировать некоторую целевую функцию. В качестве целевой функции рассмотрим сумму квадратов ошибок сети на примерах из обучающего множества.
 (6)
(6)
где  реальный выход N-го выходного слоя сети для p-го нейрона на j-м обучающем примере,
реальный выход N-го выходного слоя сети для p-го нейрона на j-м обучающем примере,  желаемый выход. То есть, минимизировав такой функционал, мы получим решение по методу наименьших квадратов.
желаемый выход. То есть, минимизировав такой функционал, мы получим решение по методу наименьших квадратов.
Поскольку весовые коэффициенты в зависимость  входят нелинейно, воспользуемся для нахождения минимума методом наискорейшего спуска. То есть на каждом шаге обучения будем изменять весовые коэффициенты по формуле
входят нелинейно, воспользуемся для нахождения минимума методом наискорейшего спуска. То есть на каждом шаге обучения будем изменять весовые коэффициенты по формуле
 (7)
(7)
где  весовой коэффициент j-го нейрона n-го слоя для связи с i-м нейроном (n-1) - го слоя. Параметр
весовой коэффициент j-го нейрона n-го слоя для связи с i-м нейроном (n-1) - го слоя. Параметр  называется параметром скорости обучения.
называется параметром скорости обучения.
Таким образом, требуется определить частные производные целевой функции E по всем весовым коэффициентам сети. Согласно правилам дифференцирования сложной функции
 (8)
(8)
где  - выход, а
- выход, а  - взвешенная сума входов j-го нейрона n-го слоя. Заметим, что, зная функцию активации, мы можем вычислить
- взвешенная сума входов j-го нейрона n-го слоя. Заметим, что, зная функцию активации, мы можем вычислить  . Например, для сигмоида в соответствии с формулой (5) эта величина будет равняться
. Например, для сигмоида в соответствии с формулой (5) эта величина будет равняться
 . (9)
. (9)
Третий сомножитель  /
/ 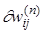 есть ни что иное, как выход i-го нейрона (n-1) - го слоя, то есть
есть ни что иное, как выход i-го нейрона (n-1) - го слоя, то есть
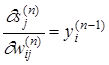 . (10)
. (10)
Частные производные целевой функции по весам нейронов выходного слоя теперь можно легко вычислить. Производя дифференцирование (6) по  и учитывая (8) и (10) будем иметь
и учитывая (8) и (10) будем иметь
 (11)
(11)
Введем обозначение
 . (12)
. (12)
Тогда для нейронов выходного слоя
 . (13)
. (13)
Для весовых коэффициентов нейронов внутренних слоев мы не можем сразу записать, чему равен 1-й сомножитель из (9), однако его можно представить следующим образом:
 (14)
(14)
Заметим, что в этой формуле 1-е два сомножителя есть не что иное, как  . Таким образом, с помощью (14) можно выражать величины
. Таким образом, с помощью (14) можно выражать величины  для нейронов n-го слоя через
для нейронов n-го слоя через 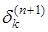 для нейронов (n+1) - го. Поскольку для последнего слоя
для нейронов (n+1) - го. Поскольку для последнего слоя  легко вычисляется по (13), то можно с помощью рекурсивной формулы
легко вычисляется по (13), то можно с помощью рекурсивной формулы
 (15)
(15)
получить значения  для вех нейронов всех слоев.
для вех нейронов всех слоев.
Окончательно формулу (7) для модификации весовых коэффициентов можно записать в виде
 . (16)
. (16)
Таким образом, полный алгоритм обучения нейронной сети с помощью алгоритма обратного распространения строиться следующим образом.
Присваиваем всем весовым коэффициентам сети случайные начальные значения. При этом сеть будет осуществлять какое-то случайное преобразование входных сигналов и значения целевой функции (6) будут велики.
Подать на вход сети один из входных векторов из обучающего множества. Вычислить выходные значения сети, запоминая при этом выходные значения каждого из нейронов.
Рассчитать по формуле (13)  . Затем с помощью рекурсивной формулы (15) подсчитываются все остальные и, наконец, с помощью (16) изменение весовых коэффициентов сети.
. Затем с помощью рекурсивной формулы (15) подсчитываются все остальные и, наконец, с помощью (16) изменение весовых коэффициентов сети.
Скорректировать веса сети:
 .
.
Рассчитать целевую функцию (6). Если она достаточно мала, считаем сеть успешно обучившейся. Иначе возвращаемся на шаг 2.
Перечислим некоторые проблемы, возникающие при применении этого метода.
Локальные минимумы
Алгоритм обратного распространения реализует градиентный спуск по поверхности ошибки в пространстве весовых коэффициентов и поэтому может застревать в локальных минимумах. При этом рядом может иметься другой, значительно более глубокий минимум.
Для преодоления этой трудности обучение сети проводят несколько раз и затем выбирают тот вариант обученной сети, который дает наилучшие результаты. Другой метод заключается в том, что сеть можно вывести из локального минимума, на короткое время, увеличив скорость обучения. Иногда, к изменению весовых коэффициентов, вычисленному по алгоритму, добавляют шум. Это также позволяет сети «выпрыгивать» из локальных минимумов.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших аргументах функции активации  , в области, где производная функции очень мала (как, например для сигмоидной функции активации). Так как величина коррекции весов пропорциональна этой производной, то процесс обучения может практически замереть. Для преодоления такой ситуации существуют модификации алгоритма, учитывающие лишь направление антиградиента и не учитывающие его величину.
, в области, где производная функции очень мала (как, например для сигмоидной функции активации). Так как величина коррекции весов пропорциональна этой производной, то процесс обучения может практически замереть. Для преодоления такой ситуации существуют модификации алгоритма, учитывающие лишь направление антиградиента и не учитывающие его величину.
Таким образом, мы подробно рассмотрели один из нейронных сетей. Разобрали задачи, решаемые такими сетями (многомерная классификация, аппроксимация функций). Получили один из алгоритмов обучения такой сети. Разумеется, это все лишь малая часть того обширного направления, которое представляют собой нейронные сети.
Хотя многие задачи успешно решаются с помощью нейронных сетей, нужно понимать, что путь от нынешнего состояния работ в этой области к глубокому пониманию принципов работы мозга, по-видимому, очень длинен. Модели в виде нейросетей скорее отвечают на вопрос, как могли бы работать те или иные системы, в каких-то чертах согласующиеся с данными об архитектуре, функциях и особенностях мозга. Тем ни менее исследования в нейронауке уже открыли пути для создания новых компьютерных архитектур и наделению вычислительных систем своеобразной интуицией, способностью к обучению и обобщению поступающей информации, то есть возможностями, которые раньше считались прерогативами живых систем.
|
|
|
