 |


Кодирование символьной информации
|
|
|
|
Кодирование чисел в компьютере и действия над ними
Особенность представления чисел в памяти компьютера – ячейки имеют ограниченный размер, а это вынуждает использовать при записи чисел и действиях с ними конечное число разрядов. В зависимости от типа числа определяется способ кодирования, количество отводимых под число ячеек памяти (разрядность числа) и перечень допустимых операций при обработке. Способы кодирования чисел и допустимые над ними действия различны для следующих числовых множеств:
- целые положительные числа (без знака)
- целые со знаком
- вещественные нормализованные числа. (иррац (бесконечные непериодические дроби, Пи, корень из двух..) и рацион (m/n или бесконечные периодические дроби))
Целые числа без знака.
Память в компьютере имеет байтовую структуру. Целые без знака обычно занимают один, два или более байт. В однобайтовом формате они могут принимать значения в диапазоне от 0 до 255, в двухбайтовом от 0 до 65535. Здесь попытка представить в байтовом формате число 258 будет интерпретироваться как ошибка.
Представляются целые числа без знака в своем двоичном виде.
Пример:
7210=10010002
в байтовом формате:
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Над целыми числами определены операции сложения (по правилам двоичного сложения) и умножения (по правилам двоичного умножения). Определены именно эти операции, так как они не меняют тип результата. Вычитание и деление не определены.
Целые числа со знаком
Используются три формы записи целых чисел со знаком: прямой код, дополнительный код, обратный код.
Прямой код
При кодировании прямым n-разрядным двоичным кодом один разряд (как правило самый старший) отводится для знака числа. Остальные n-1 разрядов – для значащих цифр. Значение знакового разряда равно 0 для положительных чисел, 1 – для отрицательных.
|
|
|
Пример: 1 = 0000 0001, -1 = 1000 0001
Дополнительный код
Введение дополнительного кода позволяет заменить вычитание на обычное сложение, что упрощает устройство ЭВМ. То есть, нет как такового вычитания, оно сводится к сложению.
Идея: на примере десятичного вычитания двухразрядных чисел:
предположим, то надо выполнить вычитание 84-32 /результат 52 /. Дополним 32 до 100 /это «дополнение» равно 68/. Затем выполним сложение 84+68 /результат 1 52 /. Единица «уходит», потому что рассматривает двухразрядные десятичные числа.
Для отрицательного числа дополнительный код образуется путем инвертирования всех бит и добавлением к младшему разряду единицы. Преимущество дополнительного кода в том, он позволяет свести вычитание к сложению. В самом деле 65-42=65+(-42)=01000001+(11010110)=[1] 00010111=23
Пример.
11011001 инвер: 00100110 и плюс 1 00100111!! Если сложить само число и его дополнительный код, то получится ноль.
Обратный код
Он получается инвертированием всех цифр двоичного кода абсолютной величины числа.
Например:
число: -1
код модуля: 00000001
обратный код: 11111110
Для числа -1101:
| Прямой код | Обратный код | Дополнительный код |
Замечание: для положительных чисел представление числа в прямом, обратном и дополнительном кодах совпадают. Т. образом - положительные числа всегда изображаются одинаково – двоичными кодами с цифрой 0 в знаковом разряде.
При сложении и вычитании чисел они обычно представляются в определенном коде в зависимости от типа арифметико-логического устройства.
Операции
над целыми без знака определены сложение, вычитание (сводится к сложению с дополнительным кодом), умножение, целочисленное деление и нахождение остатака от деления.
|
|
|
Вещественные числа
 Вещественных чисел континуум, а мы переходим к дискретному множеству кодов Þкод вещественного числа в компьютере – это приблизительный представитель многих чисел из интервала. То есть можно это изобразить так:
Вещественных чисел континуум, а мы переходим к дискретному множеству кодов Þкод вещественного числа в компьютере – это приблизительный представитель многих чисел из интервала. То есть можно это изобразить так:
 |
** Пояснение, что вещественные числа – в любом отрезке столько же, сколько и на всей прямой **
Таким образом, особенность:
Так как код вещественного числа – приблизительный представитель многих чисел из интервала, то и результаты вычислений будут заведомо содержать погрешности (ее оценка, вообще говоря, задача нетривиальная).
Вещественные числа в компьютерах представляются в нормализованном виде. Могут занимать 2 и более байт, в памяти размещаются следующим образом:
представление чисел в формате слова
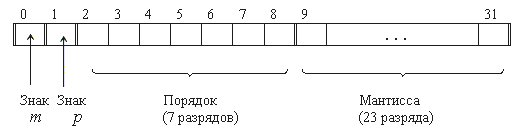
Пример.
Число А=-3.510=-11.12=-0.111·1010

Чем больше разрядов отводится под запись мантиссы, тем выше точность представления числа. Чем больше разрядов занимает порядок, тем шире диапазон от наименьшего отличного от ноля числа до наибольшего числа, представимого в машине при заданном формате.
Операции
1.Сложение.
2. Вычитание сводится к сложению с дополнительным кодом.
3. Умножение производится по правилу – мантиссы перемножаются, а порядки складываются. Если нужно, то полученное число нормализуется.
4. Деление производится по правилу – мантиссы делятся (делимое на делитель), а порядки вычитаются (порядок делителя из порядка делимого). Если нужно, то полученное число нормализуется
Кодирование символьной информации
Если каждому символу алфавита (букве, знаку) сопоставить определенное целое число (например просто порядковый номер), то текстовую информацию можно кодировать с помощью двоичного кода.
Итак, символы в компьютере хранятся в виде числового кода, причем каждому символу ставится в соответствие своя уникальная комбинация двоичных разрядов. В этом случае текст будет предстален как длинный ряд битов, в котором следующие друг за другом комбинации битов отражают последовательность символов в исходном тексте. Присвоение конкретному символу конкретного двоичного кода – это вопрос соглашения, которое фиксируется в кодовой таблице.
|
|
|
Кодовая таблица (таблица кодировки) – таблица, в которой устанавливается однозначное соответствие между символами и их порядковыми номерами.
Для разных типов ЭВМ используются различные таблицы кодировки. С распространением ПК типа IBM PC международным стандартом стала таблица кодировки под названием ASCII (American Standard Code for Information Interchange). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127 и использует код длины 7 (7-ми битное кодирование), а расширенная относится к символам от 128 до 255 (используется 8-ми битное кодирование, то есть каждый символ – это цепочка и 8-ми нулей и единиц).
Системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7.
Кодировка символов русского языка, известная как кодировка Windows-1251, была введена "извне" – компанией Microsoft, но учитывая широкое распространение операционных систем и других продуктов этой компании в России она нашла широкое распространение в России. Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) – ее происхождение относится ко времени действий Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название ISO (International Standard Organization – Международный институт стандартизации). На практике данная кодировка используется редко.
Подводя некоторый итог, можно сказать, что текст в компьютере (текстовый файл) – это файл, в котором каждый байт интерпретируется как изображаемый символ в некоторой системе кодировки. Кроме кодов изображаемых символов, текстовые файлы включают также ряд управляющих кодов, например, код перевода строки, конца файла и др.
|
|
|
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время, очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной Unicode. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65536 различных символов – этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Сегодня наблюдается постепенный переход документов и программных средств на универсальную систему кодирования.
Таким образом в интерпретации файла в формате Unicode каждые два байта интерпретируется как изображаемый символ. как и в других кодировках кроме кодов изображаемых символов, файл в формате Unicode включат ряд управляющих кодов, например, перевода строки, конца файла. и др.
|
|
|
12 |
