 |


Лексический анализ и его задачи
|
|
|
|
Формальные грамматики. Основные понятия и определения
Алфавит - это конечное множество символов.
Цепочкой символов в алфавите V называется любая конечная последовательность символов этого алфавита.
Цепочка, которая не содержит ни одного символа, называется
пустой цепочкой. Для ее обозначения обычно используется символ ε.
Если α и β - цепочки, то цепочка αβ называется конкатенацией
(или сцеплением) цепочек α и β.
Обращением (или реверсом) цепочки α называется цепочка,
символы которой записаны в обратном порядке. Обозначается αR.
n-ой степенью цепочки α (αn) наз-ся конкатенация n цепочек α.
α0 = ε; α2 = αα.
Длина цепочки - это число составляющих ее символов. Обознач. - |α|.
Язык в алфавите V - это подмножество цепочек конечной
длины в этом алфавите.
Декартовым произведением A ×B множеств A и B называется
множество { (a,b) | a ∈ A, b ∈ B}.
Порождающая грамматика G - это четверка (VT, VN, P, S), где VT - алфавит терминальных символов (терминалов), VN - алфавит нетерминальных символов (нетерминалов), не пересекающийся с VT, P - конечное подмножество множества (VT ∪ VN)+ ×(VT ∪ VN)*; Элемент (α, β) множества P называется правилом вывода и записывается в виде α → β, S - начальный символ (цель) грамматики, S ∈ VN.
Грамматики G1 и G2 называются эквивал., если L(G1) = L(G2) (порождают один и тот же язык).
Грамматики G1 и G2 почти эквивалентны, если
L(G1) ∪ {ε} = L(G2) ∪ {ε}.
Другими словами, грамматики почти эквивалентны, если языки, ими порождаемые, отличаются не более, чем на ε.
Нужно знать!
Сентенциальной формой грамматики G называется цепочка, выводимая из начального нетерминала грамматики G.
Сентенцией грамматики G называется сентенциальная форма, состоящая только из терминальных символов.
|
|
|
Язык, поражденный граматикой, есть множество всех ее сентенций.
Классификация грамматик и языков по Хомскому
Иерархия Ноама Хомского — классификация формальных языков и формальных грамматик, согласно которой они делятся на 4 типа по их условной сложности.
ТИП 0:
Грамматика G = (VT, VN, P, S) называется грамматикой типа 0, если на правила вывода не накладывается никаких ограничений (кроме тех, которые указаны в определении грамматики).
ТИП 1:
Грамматика G = (VT, VN, P, S) называется неукорачивающей грамматикой, если каждое правило из P имеет вид α → β, где α ∈ (VT ∪ VN)+, β ∈ (VT ∪ VN)+ и |α| Ì |β|.
Грамматика G = (VT, VN, P, S) называется контекстно-зависимой (КЗ), если каждое правило из P имеет вид α → β, где α = ξ1Aξ2; β = ξ1γξ2; A ∈ VN; γ ∈ (VT ∪ VN)+; ξ1,ξ2 ∈ (VT ∪ VN)*.
Грамматику типа 1 можно определить как не укорачивающую либо как контекстно-зависимую.
Выбор определения не влияет на множество языков, порождаемых
грамматиками этого класса, поскольку доказано, что множество языков, порождаемых неукорачивающими грамматиками, совпадает с множеством языков, порождаемых КЗ-грамматиками.
ТИП 2:
Грамматика G = (VT, VN, P, S) называется контекстно-свободной (КС), если каждое правило из Р имеет вид A → β, где A ∈ VN, β ∈ (VT ∪ VN)+.
Грамматика G = (VT, VN, P, S) называется укорачивающей контекстно-свободной (УКС), если каждое правило из Р имеет вид A → β, где A ∈ VN, β ∈ (VT ∪ VN)*.
Грамматику типа 2 можно определить как контекстно-свободную либо как укорачивающую контекстно-свободную.
Возможность выбора обусловлена тем, что для каждой УКС-грамматики существует почти эквивалентная КС-грамматика.
ТИП 3:
Грамматика G = (VT, VN, P, S) называется праволинейной, если каждое
правило из Р имеет вид A → tB либо A → t, где A ∈ VN, B ∈ VN, t ∈ VT.
|
|
|
Грамматика G = (VT, VN, P, S) называется леволинейной, если каждое правило из Р имеет вид A → Bt либо A → t, где A ∈ VN, B ∈ VN, t ∈ VT.
Грамматику типа 3 (регулярную, Р-грамматику) можно определить как праволинейную либо как леволинейную.
Выбор определения не влияет на множество языков, порождаемых
грамматиками этого класса, поскольку доказано, что множество языков, порождаемых праволинейными грамматиками, совпадает с множеством языков, порождаемых леволинейными грамматиками.
Задача разбора
Цепочка принадлежит языку, порождаемому грамматикой, только в том случае, если существует ее вывод из цели этой грамматики. Процесс построения такого вывода (а, следовательно, и определения принадлежности цепочки языку) называется разбором.
С практической точки зрения наибольший интерес представляет разбор по контекстно-свободным (КС и УКС) грамматикам. Их порождающей мощности достаточно для описания большей части синтаксической структуры языков программирования, для различных подклассов КС-грамматик имеются хорошо разработанные практически приемлемые способы решения задачи разбора.
Определение: вывод цепочки β ∈ (VT)* из S ∈ VN в КС-грамматике
G = (VT, VN, P, S), называется левым (левосторонним), если в этом выводе каждая очередная сентенциальная форма получается из предыдущей заменой самого левого нетерминала.
Определение: вывод цепочки β ∈ (VT)* из S ∈ VN в КС-грамматике
G = (VT, VN, P, S), называется правым (правосторонним), если в этом выводе каждая очередная сентенциальная форма получается из предыдущей заменой самого правого нетерминала.
В грамматике для одной и той же цепочки может быть несколько выводов, эквивалентных в том смысле, что в них в одних и тех же местах применяются одни и те же правила вывода, но в различном порядке.
Для КС-грамматик можно ввести удобное графическое представление вывода, называемое деревом вывода, причем для всех эквивалентных выводов деревья вывода совпадают.
Дерево называется деревом вывода (или деревом разбора) в КС-грамматике G = {VT, VN, P, S), если выполнены следующие условия:
(1) каждая вершина дерева помечена символом из множества (VN ∪ VT ∪ ε),
при этом корень дерева помечен символом S; листья - символами из (VT ∪ ε);
|
|
|
(2) если вершина дерева помечена символом A ∈ VN, а ее непосредственные
потомки - символами a1, a2,..., an, где каждое ai ∈ (VT ∪ VN), то A → a1a2...an - правило вывода в этой грамматике;
(3) если вершина дерева помечена символом A ∈ VN, а ее единственный непосредственный потомок помечен символом ε, то A → ε - правило вывода в этой грамматике.
КС-грамматика G называется неоднозначной, если существует хотя бы одна цепочка α ∈ L(G), для которой может быть построено два или более различных деревьев вывода.
Это утверждение эквивалентно тому, что цепочка α имеет два или более разных левосторонних (или правосторонних) выводов.
В противном случае грамматика называется однозначной.
Язык, порождаемый грамматикой, называется неоднозначным, если он не может быть порожден никакой однозначной грамматикой.
Примеры грамматик и языков
Замечание: если при описании грамматики указаны только правила вывода Р, то будем считать, что большие латинские буквы обозначают нетерминальные символы, S - цель грамматики, все остальные символы - терминальные.
1) Язык типа 0: L(G) = {a2 bn2−1 | n >= 1}
G: S → aaCFD
F → AFB | AB
AB → bBA
Ab → bA
AD → D
Cb → bC
CB → C
bCD → ε
2) Язык типа 1: L(G) = { an bn cn, n >= 1}
G: S → aSBC | abC
CB → BC
bB → bb
bC → bc
cC → cc
3) Язык типа 2: L(G) = {(ac)n (cb)n | n > 0}
G: S → aQb | accb
Q → cSc
4) Язык типа 3: L(G) = {ω ⊥ | ω ∈ {a,b}+, где нет двух рядом стоящих а}
G: S → A⊥ | B⊥
A → a | Ba
B → b | Bb | Ab
Приложение
{S → aSb|ab} - КС-грамматика, она порождает КС-язык
{an bn |n ⩾ 1}.
Язык {an bn am |m, n ⩾ 1} контекстно-свободен, поскольку порождается КС-грамматикой
{S → CD, C → aC b|ab, D → aD|a}.
Преобразования грамматик
В некоторых случаях КС-грамматика может содержать недостижимые и бесплодные символы, которые не участвуют в порождении цепочек языка и поэтому могут быть удалены из грамматики.
Определение: символ x ∈ (VT ∪ VN) называется недостижимым в грамматике G = (VT, VN, P, S), если он не появляется ни в одной сентенциальной форме этой грамматики.
|
|
|
Алгоритм удаления недостижимых символов:
Вход: КС-грамматика G = (VT, VN, P, S)
Выход: КС-грамматика G’ = (VT’, VN’, P’, S), не содержащая недостижимых символов, для которой L(G) = L(G’).
Метод:
1. V0 = {S}; i = 1.
2. Vi = {x | x ∈ (VT ∪ VN), в P есть A→αxβ и A∈Vi-1, α,β∈(VT∪VN)∗} ∪ Vi-1.
3. Если Vi ≠ Vi-1, то i = i + 1 и переходим к шагу 2, иначе VN’ = Vi ∩ VN;
VT’ = Vi ∩ VT; P’ состоит из правил множества P, содержащих только символы из Vi; G’ = (VT’, VN’, P’, S).
Определение: символ A ∈ VN называется бесплодным в грамматике G = (VT, VN, P, S), если множество { α ∈ VT* | A à α} пусто.
Алгоритм удаления бесплодных символов:
Вход: КС-грамматика G = (VT, VN, P, S).
Выход: КС-грамматика G’ = (VT, VN’, P’, S), не содержащая бесплодных символов, для которой L(G) = L(G’).
Метод:
Рекурсивно строим множества N0, N1,...
1. N0 = ∅, i = 1.
2. Ni = {A | (A → α) ∈ P и α ∈ (Ni-1 ∪ VT)*} ∪ Ni-1.
3. Если Ni ≠ Ni-1, то i = i + 1 и переходим к шагу 2, иначе VN’ = Ni; P’ состоит из правил множества P, содержащих только символы из VN’ ∪ VT; G’ = (VT,VN’, P’, S).
Определение: КС-грамматика G называется приведенной, если в ней нет недостижимых и бесплодных символов.
Алгоритм приведения грамматики:
(1) обнаруживаются и удаляются все бесплодные нетерминалы.
(2) обнаруживаются и удаляются все недостижимые символы.
Удаление символов сопровождается удалением правил вывода, содержащих эти символы.
Замечание: если в этом алгоритме переставить шаги (1) и (2), то не всегда результатом будет приведенная грамматика.
Для описания синтаксиса языков программирования стараются использовать однозначные приведенные КС-грамматики.
Теория трансляции. Основные понятия и определения
Практически во всех трансляторах (и в компиляторах, и в интерпретаторах) в том или ином виде присутствует большая часть перечисленных ниже процессов:
* лексический анализ
* синтаксический анализ
* семантический анализ
* генерация внутреннего представления программы
* оптимизация
* генерация объектной программы.
В конкретных компиляторах порядок этих процессов может быть несколько иным, некоторые из них могут объединяться в одну фазу, другие могут выполнятся в течение всего процесса компиляции. В интерпретаторах и при смешанной стратегии трансляции некоторые этапы могут вообще отсутствовать.
Замечание:
a) запись вида {α} означает итерацию цепочки α, т.е. в порождаемой цепочке в этом месте может находиться либо ε, либо α, либо αα, либо ααα и т.д.
b) запись вида [ α | β ] означает, что в порождаемой цепочке в этом месте может находиться либо α, либо β.
c) P - цель грамматики; символ ⊥ - маркер конца текста программы.
|
|
|
Контекстные условия:
1. Любое имя, используемое в программе, должно быть описано и только один раз.
2. В операторе присваивания типы переменной и выражения должны совпадать.
3. В условном операторе и в операторе цикла в качестве условия возможно только логическое выражение.
4. Операнды операции отношения должны быть целочисленными.
5. Тип выражения и совместимость типов операндов в выражении определяются по обычным правилам; старшинство операций задано синтаксисом.
В любом месте программы, кроме идентификаторов, служебных слов и чисел, может находиться произвольное число пробелов и комментариев вида {< любые
символы, кроме } и ⊥ >}.
True, false, read и write - служебные слова (их нельзя переопределять, как стандартные идентификаторы Паскаля).
Сохраняется паскалевское правило о разделителях между идентификаторами, числами и служебными словами.
Семантический анализ
Контекстно-свободные грамматики, с помощью которых описывают синтаксис языков программирования, не позволяют задавать контекстные условия, имеющиеся в любом языке.
Примеры наиболее часто встречающихся контекстных условий:
a) каждый используемый в программе идентификатор должен быть описан,
но не более одного раза в одной зоне описания;
b) при вызове функции число фактических параметров и их типы должны
соответствовать числу и типам формальных параметров;
c) обычно в языке накладываются ограничения на типы операндов любой операции, определенной в этом языке; на типы левой и правой частей в операторе присваивания; на тип параметра цикла; на тип условия в операторах цикла и условном операторе и т.п.
Проверку контекстных условий часто называют семантическим анализом. Его можно выполнять сразу после синтаксического анализа, некоторые требования можно контролировать во время генерации кода (например, ограничения на типы операндов в выражении), а можно совместить с синтаксическим анализом.
Мы выберем последний вариант: как только синтаксический анализатор распознает конструкцию, на компоненты которой наложены некоторые ограничения, проверяется их выполнение. Это означает, что на этапе синтаксического анализа придется выполнять некоторые дополнительные действия, осуществляющие семантический контроль.
Если для синтаксического анализа используется метод рекурсивного спуска, то в тела процедур РС-метода необходимо вставить вызовы дополнительных "семантических" процедур (семантические действия). Причем, как показывает практика, удобнее вставить их сначала в синтаксические правила, а потом по этим расширенным правилам строить процедуры РС-метода.
Лексический анализ и его задачи
Лексический анализ (ЛА) - это первый этап процесса компиляции. На этом этапе символы, составляющие исходную программу, группируются в отдельные лексические элементы, называемые лексемами.
Лексический анализ важен для процесса компиляции по нескольким причинам:
a) замена в программе идентификаторов, констант, ограничителей и служебных слов лексемами делает представление программы более удобным для дальнейшей обработки;
b) лексический анализ уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии;
c) если будет изменена кодировка в исходном представлении программы, то это отразится только на лексическом анализаторе.
Выбор конструкций, которые будут выделяться как отдельные лексемы, зависит от языка и от точки зрения разработчиков компилятора. Обычно принято выделять следующие типы лексем: идентификаторы, служебные слова, константы и ограничители. Каждой лексеме сопоставляется пара (тип_лексемы, указатель_на_информацию_о_ней).
Соглашение: эту пару тоже будем называть лексемой, если это не будет вызывать недоразумений.
Т. о., лексический анализатор - это транслятор, входом которого служит цепочка символов, представляющих исходную программу, а выходом последовательность лексем.
Очевидно, что лексемы перечисленных выше типов можно описать с помощью регулярных грамматик.
Для грамматик этого класса существует простой и эффективный алгоритм анализа того, принадлежит ли заданная цепочка языку, порождаемому этой грамматикой. Однако перед лексическим анализатором стоит более сложная задача: он должен сам выделить в исходном тексте цепочку символов, представляющую лексему, а также преобразовать ее в пару
(тип_лексемы, указатель_на_ информацию_о_ней). Для того, чтобы решить эту задачу, опираясь на способ анализа с помощью диаграммы состояний, введем на дугах дополнительный вид пометок - пометки-действия. Теперь каждая дуга в ДС может выглядеть так:
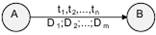
Смысл ti прежний - если в состоянии A очередной анализируемый символ совпадает с ti для какого-либо i = 1, 2,... n, то осуществляется переход в состояние B; при этом необходимо выполнить действия D1, D2,...,Dm.
Лексический анализатор
Лексический анализатор — это программа или часть программы, выполняющая лексический анализ. Лексический анализатор обычно работает в две стадии: сканирование и оценка.
На первой стадии, сканировании, лексический анализатор обычно реализуется в виде конечного автомата, определяемого регулярными выражениями. В нём кодируется информация о возможных последовательностях символов, которые могут встречаться в токенах. Входные символы обрабатываются один за другим пока не встретится символ, не входящий во множество допустимых символов для данного токена. В некоторых языках правила разбора лексем несколько более сложные и требуют возвратов назад по читаемой последовательности.
Полученный таким образом токен содержит необработанный исходный текст (строку). Для того чтобы получить токен со значением, соответствующим типу (напр. целое или дробное число), выполняется оценка этой строки — проход по символам и вычисление значения.
Токен с типом и соответственно подготовленным значением передаётся на вход синтаксического анализатора.
Синтаксический анализ
На этапе синтаксического анализа нужно установить, имеет ли цепочка лексем структуру, заданную синтаксисом языка, и зафиксировать эту структуру.
Следовательно, снова надо решать задачу разбора: дана цепочка лексем, и надо определить, выводима ли она в грамматике, определяющей синтаксис языка.
Однако структура таких конструкций как выражение, описание, оператор и т.п., более сложная, чем структура идентификаторов и чисел. Поэтому для описания синтаксиса языков программирования нужны более мощные грамматики, чем регулярные. Обычно для этого используют укорачивающие контекстно-свободные грамматики (УКС-грамматики), правила которых имеют вид A → α, где A ∈ VN, α ∈ (VT ∪ VN)*. Грамматики этого класса, с одной стороны, позволяют достаточно полно описать синтаксическую структуру реальных языков программирования; с другой стороны, для разных подклассов УКС-грамматик существуют достаточно эффективные алгоритмы разбора.
С теоретической точки зрения существует алгоритм, который по любой данной КС-грамматике и данной цепочке выясняет, принадлежит ли цепочка языку, порождаемому этой грамматикой. Но время работы такого алгоритма (синтаксического анализа с возвратами) экспоненциально зависит от длины цепочки, что с практической точки зрения совершенно неприемлемо.
Существуют табличные методы анализа, применимые ко всему классу КС-грамматик и требующие для разбора цепочек длины n времени cn3 (алгоритм
Кока-Янгера-Касами) либо cn2 (алгоритм Эрли). Их разумно применять только в том случае, если для интересующего нас языка не существует грамматики, по которой можно построить анализатор с линейной временной зависимостью.
Алгоритмы анализа, расходующие на обработку входной цепочки линейное время, применимы только к некоторым подклассам КС-грамматик.
Синтаксический анализатор
Синтаксический и лексический анализаторы взаимодействуют следующим образом: анализ исходной программы идет под управлением синтаксического анализатора; если для продолжения анализа ему нужна очередная лексема, то он запрашивает ее у лексического анализатора; тот выдает одну лексему и "замирает" до тех пор, пока синтаксический анализатор не запросит следующую лексему.
Задача синтаксического анализатора – проверить правильность записи выражения и разбить его на лексемы. Лексемой называется неделимая часть выражения, состоящая, в общем случае, из нескольких символов. Для арифметических и логических выражений лексемами будут: * имена переменных; * имена функций; * константы; * операции – арифметические (+, -, *, /), логические (!, &&, ||) и сравнения (==,!=, >, >=, <, <=); * открывающая скобка; * закрывающая скобка.
При реализации синтаксического анализатора надо все символы, которые могут встретиться в обрабатываемой строке, разбить на группы т. о., чтобы все символы группы вызывали одинаковую реакцию синтаксического анал-ра.
Кроме того, необходимо выделить состояния синтаксического анализатора. Состояние определяет, какие символы в данный момент могут быть на входе синтаксического анализатора, и какова будет реакция на этот символ. Например, если на вход синтаксического анализатора пришла цифра, то он переходит в состояние «Константа», и до завершения константы (т.е. до появления пробела, знака операции, закрывающей скобки или конца строки) на вход синтаксического анализатора могут приходить только цифры и точка, если константа вещественная. Причём, естественно, точка может встречаться только один раз, что приводит к делению состояния «Константа» на два состояния: «Константа до точки», в котором точка может появиться, и «Константа после точки», в котором появление точки будет считаться ошибкой.
Одно состояние является начальным – с него начинается работа синтаксического анализатора, и одно или несколько состояний должны быть конечными.
Далее строиться таблица, которая определяет реакцию синтаксического анализатора на входные символы в зависимости от состояния. Реакция обычно заключается в смене состояния синтаксического анализатора и ещё каких-то действиях, н-р, увеличение или уменьшение уровня вложенности при появлении скобок и т.д.
Семантический анализатор
Контекстные условия, выполнение которых надо контролировать в программах таковы:
1. Любое имя, используемое в программе, должно быть описано и только один раз.
2. В операторе присваивания типы переменной и выражения должны совпадать.
3. В условном операторе и в операторе цикла в качестве условия возможно только логическое выражение.
4. Операнды операции отношения должны быть целочисленными.
5. Тип выражения и совместимость типов операндов в выражении определяются по обычным правилам
Проверку контекстных условий совместим с синтаксическим анализом. Для этого в синтаксические правила вставим вызовы процедур, осуществляющих необходимый контроль, а затем перенесем их в процедуры рекурсивного спуска.
Обработка описаний
Для контроля согласованности типов в выражениях и типов выражений в операторах, необходимо знать типы переменных, входящих в эти выражения.
Кроме того, нужно проверять, нет ли повторных описаний идентификаторов. Эта информация становится известной в тот момент, когда синтаксический анализатор обрабатывает описания. Следовательно, в синтаксические правила для описаний нужно вставить действия, с помощью которых будем запоминать типы переменных и контролировать единственность их описания. Семантический анализатор выполняет следующие основные действия:
· проверка соблюдения во входной программе семантических соглашений входного языка;
· дополнение внутреннего представления программы в компиляторе операторами и действиями, неявно предусмотренными семантикой входного языка;
· проверка элементарных семантических (смысловых) норм языков программирования, напрямую не связанных с входным языком.
Проверка соблюдения во входной программе семантических соглашений входного языка заключается в сопоставлении входных цепочек программы с требованиями семантики входного языка программирования. Каждый язык программирования имеет четко заданные и специфицированные семантические соглашения, которые не могут быть проверены на этапе синтаксического разбора. Именно их в первую очередь проверяет семантический анализатор.
|
|
|
