 |


Разработка программного продукта
|
|
|
|
Введение
Целью курсовой работы является разработка архиватора методом сжатия RLE (run-length encoding) с применение объектно-ориентированных возможностей языка программирования C# в среде разработки приложений Microsoft Visual Studio 2010 Ultimate.
С# - это универсальный объектно-ориентированный язык программирования, обеспечивающий безопасность преобразования типов. Целью его создания было повышение производительности труда программистов. Поэтому в языке сбалансированы - простота, выразительность и эффективность.
1 Язык программирования С#
1.1 Общее описание языка С#
Последнее время С и С++ являются наиболее используемыми языками для разработки коммерческих и бизнес приложений. Эти языки устраивают многих разработчиков, но в действительности не обеспечивают должной продуктивности разработки. К примеру, процесс написания приложения на С++ зачастую занимает значительно больше времени, чем разработка эквивалентного приложения, скажем, на Visual Basic. Сейчас существуют языки, увеличивающие продуктивность разработки за счет потери в гибкости, которая так привычна и необходима программистам на С/С++. Подобные решения являются весьма неудобными для разработчиков и зачастую предлагают значительно меньшие возможности. Эти языки также не ориентированы на взаимодействие с появляющимися сегодня системами и очень часто они не соответствуют существующей практике программирования для Web. Многие разработчики хотели бы использовать современный язык, который позволял бы писать, читать и сопровождать программы с простотой Visual Basic и в то же время давал мощь и гибкость C++, обеспечивал доступ ко всем функциональным возможностям системы, взаимодействовал бы с существующими программами и легко работал с возникающими Web стандартами.
|
|
|
Учитывая все подобные пожелания, Microsoft разработала новый язык - C#. В него входит много полезных особенностей - простота, объектная ориентированность, типовая защищенность, "сборка мусора", поддержка совместимости версий и многое другое. Данные возможности позволяют быстро и легко разрабатывать приложения, особенно COM+ приложения и Web сервисы. При создании C#, его авторы учитывали достижения многих других языков программирования: C++, C, Java, SmallTalk, Delphi, Visual Basic и т.д. Надо заметить что по причине того, что C# разрабатывался с чистого листа, у его авторов была возможность (которой они явно воспользовались), оставить в прошлом все неудобные и неприятные особенности (существующие, как правило, для обратной совместимости), любого из предшествующих ему языков. В результате получился действительно простой, удобный и современный язык, по мощности не уступающий С++, но существенно повышающий продуктивность разработок.
Очень часто можно проследить такую связь - чем более язык защищен и устойчив к ошибкам, тем меньше производительность программ, написанных на нем. К примеру рассмотрим две крайности - очевидно это Assembler и Java. В первом случае вы можете добиться фантастической быстроты своей программы, но вам придется очень долго заставлять ее работать правильно не на вашем компьютере. В случае же с Java - вы получаете защищенность, независимость от платформы, но, к сожалению, скорость вашей программы вряд ли совместима со сложившимся представлением о скорости, например, какого-либо отдельного клиентского приложения (конечно существуют оговорки - JIT компиляция и прочее).
В C#, как в несомненно современном языке, также существуют характерные особенности для обхода возможных ошибок. Например, помимо упомянутой выше "сборки мусора", там все переменные автоматически инициализируются средой и обладают типовой защищенностью, что позволяет избежать неопределенных ситуаций в случае, если программист забудет инициализировать переменную в объекте или попытается произвести недопустимое преобразование типов. Также в C# были предприняты меры для исключения ошибок при обновлении программного обеспечения. Изменение кода, в такой ситуации, может непредсказуемо изменить суть самой программы. Чтобы помочь разработчикам бороться с этой проблемой C# включает в себя поддержку совместимости версий (vesioning). В частности, в отличии от C++ и Java, если метод класса был изменен, это должно быть специально оговорено. Это позволяет обойти ошибки в коде и обеспечить гибкую совместимость версий. Также новой особенностью является native поддержка интерфейсов и наследования интерфейсов. Данные возможности позволяют разрабатывать сложные системы и развивать их со временем.
|
|
|
В C# была унифицирована система типов, теперь вы можете рассматривать каждый тип как объект. Несмотря на то, используете вы класс, структуру, массив или встроенный тип, вы можете обращаться к нему как к объекту. Объекты собраны в пространства имен (namespaces), которые позволяют программно обращаться к чему-либо. Это значит что вместо списка включаемых файлов заголовков в своей программе вы должны написать какие пространства имен, для доступа к объектам и классам внутри них, вы хотите использовать. В C# выражение using позволяет вам не писать каждый раз название пространства имен, когда вы используете класс из него. Например, пространство имен System содержит несколько классов, в том числе и Console. И вы можете писать либо название пространства имен перед каждым обращением к классу, либо использовать using как это было показано в примере выше.
Важной и отличительной от С++ особенностью C# является его простота. К примеру, всегда ли вы помните, когда пишите на С++, где нужно использовать "->", где "::", а где "."? Даже если нет, то компилятор всегда поправляет вас в случае ошибки. Это говорит лишь о том, что в действительности можно обойтись только одним оператором, а компилятор сам будет распознавать его значение. Так в C#, оператор"->" используется очень ограничено (в unsafe блоках, о которых речь пойдет ниже), оператор "::" вообще не существует. Практически всегда вы используете только оператор "." и вам больше не нужно стоять перед выбором.
|
|
|
Еще один пример. При написании программ на C/С++ вам приходилось думать не только о типах данных, но и о их размере в конкретной реализации. В C# все упрощено - теперь символ Unicode называется просто char (а не wchar_t, как в С++) и 64-битное целое теперь - long (а не __int64). Также в C# нет знаковых и беззнаковых символьных типов.
В C#, также как и в Visual Basic после каждого выражения case в блоке switch подразумевается break. И более не будет происходить странных вещей если вы забыли поставить этот break. Однако если вы действительно хотите чтобы после одного выражения case программа перешла к следующему вы можете переписать свою программу с использованием, например, оператора goto.
Многим программистам (на тот момент, наверное, будущим программистам) было не так легко во время изучения C++ полностью освоиться с механизмом ссылок и указателей. В C# (кто-то сейчас вспомнит о Java) нет указателей. В действительности нетривиальность указателей соответствовала их полезности. Например, порой, трудно себе представить программирование без указателей на функции. В соответствии с этим в C# присутствуют Delegates - как прямой аналог указателя на функцию, но их отличает типовая защищенность, безопасность и полное соответствие концепциям объектно-ориентированного программирования.
Хотелось бы подчеркнуть современное удобство C#. Когда вы начнете работу с C#, а, надеюсь, это произойдет как можно скорее, вы увидите, что довольно большое значение в нем имеют пространства имен. Уже сейчас, на основе первого примера, вы можете судить об этом - ведь все файлы заголовков заменены именно пространством имен. Так в C#, помимо просто выражения using, предоставляется еще одна очень удобная возможность - использование дополнительного имени (alias) пространства имен или класса.
Современность C# проявляется и в новых шагах к облегчению процесса отладки программы. Традиционным средством для отладки программ на стадии разработки в C++ является маркировка обширных частей кода директивами #ifdef и т.д. В C#, используя атрибуты, ориентированные на условные слова, вы можете куда быстрее писать отлаживаемый код.
|
|
|
В наше время, когда усиливается связь между миром коммерции и миром разработки программного обеспечения, и корпорации тратят много усилий на планирование бизнеса, ощущается необходимость в соответствии абстрактных бизнес процессов их программным реализациям. К сожалению, большинство языков реально не имеют прямого пути для связи бизнес логики и кода. Например, сегодня многие программисты комментируют свои программы для объяснения того, какие классы реализуют какой-либо абстрактный бизнес объект. C# позволяет использовать типизированные, расширяемые метаданные, которые могут быть прикреплены к объекту. Архитектурой проекта могут определяться локальные атрибуты, которые будут связанны с любыми элементами языка - классами, интерфейсами и т.д. Разработчик может программно проверить атрибуты какого-либо элемента. Это существенно упрощает работу, к примеру, вместо того чтобы писать автоматизированный инструмент, который будет проверять каждый класс или интерфейс, на то, является ли он действительно частью абстрактного бизнес объекта, можно просто воспользоваться сообщениями основанными на определенных в объекте локальных атрибутах.
Современные архиваторы
Архиваторы – это программы для создания архивов. Архивы предназначены для хранения данных в удобном компактном виде. В качестве данных обычно выступают файлы и папки. Как правило, данные предварительно подвергаются процедуре сжатия или упаковки. Поэтому почти каждый архиватор одновременно является программой для сжатия данных. С другой стороны, любая программа для сжатия данных может рассматриваться как архиватор. Эффективность сжатия является важнейшей характеристикой архиваторов. От нее зависит размер создаваемых архивов. Чем меньше архив, тем меньше места требуется для его хранения. Для передачи нужна меньшая пропускная способность канала передачи или затрачивается меньшее время. Преимущества архивов очевидны, если учесть, что данные уменьшаются в размере и в 2 раза, и в 5 раз.
Сжатие данных используется очень широко. Можно сказать, почти везде. Например, документы PDF, как правило, содержат сжатую информацию. Довольно много исполняемых файлов EXE сжаты специальными упаковщиками. Всевозможные мультимедийные файлы (GIF, JPG, MP3, MPG) являются своеобразными архивами.
Основным недостатком архивов является невозможность прямого доступа к данным. Их сначала необходимо извлечь из архива или распаковать. Операция распаковки, впрочем, как и упаковки, требует некоторых системных ресурсов. Это не мгновенная операция. Поэтому архивы в основном применяют со сравнительно редко используемыми данными. Например, для хранения резервных копий или установочных файлов.
|
|
|
В данный момент существует много архиваторов. Они имеют разную распространенность и эффективность. Некоторые интересные архиваторы не известны широкому кругу потенциальных пользователей. Особый интерес представляют оценка и сравнение эффективности сжатия популярных архиваторов.
Методы сжатия
Разработано большое количество разнообразных методов, их модификаций и подвидов для сжатия данных. Современные архиваторы, как правило, одновременно используют несколько методов одновременно. Можно выделить некоторые основные.
Кодирование длин серий (RLE - сокращение от run-length encoding - кодирование длин серий)
Очень простой метод. Последовательная серия одинаковых элементов данных заменяется на два символа: элемент и число его повторений. Широко используется как дополнительный, так и промежуточный метод. В качестве самостоятельного метода применяется, например, в графическом формате BMP.
Словарный метод (LZ - сокращение от Lempel Ziv - имена авторов)
Наиболее распространенный метод. Используется словарь, состоящий из последовательностей данных или слов. При сжатии эти слова заменяются на их коды из словаря. В наиболее распространенном варианте реализации в качестве словаря выступает сам исходный блок данных.
Основным параметром словарного метода является размер словаря. Чем больше словарь, тем больше эффективность. Однако для неоднородных данных чрезмерно большой размер может быть вреден, так как при резком изменении типа данных словарь будет заполнен неактуальными словами. Для эффективной работы данного метода при сжатии требуется дополнительная память. Приблизительно на порядок больше, чем нужно для исходных данных словаря. Существенным преимуществом словарного метода является простая и быстрая процедура распаковки. Дополнительная память при этом не требуется. Такая особенность особенно важна, если необходим оперативный доступ к данным.
Энтропийный метод (Huffman - кодирование Хаффмена, Arithmetic coding - арифметическое кодирование)
В этом методе элементы данных, которые встречаются чаще, кодируются при сжатии более коротким кодом, а более редкие элементы данных кодируются более длинным кодом. За счет того, что коротких кодов значительно больше, общий размер получается меньше исходного.
Широко используется как дополнительный метод. В качестве самостоятельного метода применяется, например, в графическом формате JPG.
Метод контекстного моделирования (CM - сокращение от context modeling - контекстное моделирование)
В этом методе строится модель исходных данных. При сжатии очередного элемента данных эта модель выдает свое предсказание или вероятность. Согласно этой вероятности, элемент данных кодируется энтропийным методом. Чем точнее модель будет соответствовать исходным данным, тем точнее она будет выдавать предсказания, и тем короче будут кодироваться элементы данных.
Для построения эффективной модели требуется много памяти. При распаковке приходится строить точно такую же модель. Поэтому скорость и требования к объему оперативной памяти для упаковки и распаковки почти одинаковы. В данный момент методы контекстного моделирования позволяют получить наилучшую степень сжатия, но отличаются чрезвычайно низкой скоростью.
PPM (PPM - Prediction by Partial Matching - предсказание по частичному совпадению)
Это особый подвид контекстного моделирования. Предсказание выполняется на основании определенного количества предыдущих элементов данных. Основным параметром является порядок модели, который задает это количество элементов. Чем больше порядок модели, тем выше степень сжатия, но требуется больше оперативной памяти для хранения данных модели. Если оперативной памяти недостаточно, то такая модель с большим порядком показывает низкие результаты. Метод PPM особенно эффективен для сжатия текстовых данных.
Предварительные преобразования или фильтрация
Данные методы служат не для сжатия, а для представления информации в удобном для дальнейшего сжатия виде. Например, для несжатых мультимедиа данных характерны плавные изменения уровня сигнала. Поэтому для них применяют дельта-преобразование, когда вместо абсолютного значения берется относительное. Существуют фильтры для текста, исполняемых файлов, баз данных и другие.
Метод сортировки блока данных (BWT - сокращение от Burrows Wheeler Transform - по имени авторов)
Это особый вид или группа преобразований, в основе которых лежит сортировка. Такому преобразованию можно подвергать почти любые данные. Сортировка производится над блоками, поэтому данные предварительно разбиваются на части. Основным параметром является размер блока, который подвергается сортировке. Для распаковки данных необходимо проделать почти те же действия, что и при упаковке. Поэтому скорость и требования к оперативной памяти почти одинаковы. Архиваторы, которые используют данный метод, обычно показывают высокую скорость и степень сжатия для текстовых данных.
Непрерывные блоки или непрерывный режим (Solid mode - непрерывный режим)
Во многих методах сжатия начальный участок данных или файла кодируется плохо. Например, в словарном методе словарь пуст. В методе контекстного моделирования модель не построена. Когда количество файлов большое, а их размер маленький, общая степень сжатия значительно ухудшается за счет этих начальных участков. Чтобы этого не происходило при переходе на следующий файл, используется информация, полученная исходя из предыдущих файлов. Аналогичного эффекта можно добиться простым представлением исходных файлов в виде одного непрерывного файла.
Этот метод используется во многих архиваторах и имеет существенный недостаток. Для распаковки произвольного файла необходимо распаковать и файлы, которые оказались в начале архива. Это необходимо для правильного заполнения словаря или построения модели. Существует и промежуточный вариант, когда используются непрерывные блоки фиксированного размера. Потери сжатия получаются минимальными, но для извлечения одного файла, который находится в конце большого архива, необходимо распаковать только один непрерывный блок, а не весь архив.
Сегментирование
Во всех методах сжатия при изменении типа данных собственно сам переход кодируется очень плохо. Словарь становится не актуальным, модель настроена на другие данные. В этих случаях применяется сегментирование. Это предварительная разбивка на однородные части. Затем эти части кодируются по отдельности или группами.
Особо хочется подчеркнуть, что существует большое количество методов сжатия. Каждый метод обычно ориентирован на один вид или группу реальных данных. Хорошие результаты показывает комплексное использование методов.
Разработка программного продукта
Текст, который нужно будет кодировать, получим из текстового поля “text_input” и запишем в строковую переменную “str1”. Далее будем пробегать по каждому символу в этой строке, получать текущий символ в строковую переменную “ch”. В том случае, если данный символ равен следующему, продолжаем поиск количества таких символов, начиная текущей позиции в строке.
После всего этого формируем кодируемую строку равную количеству найденных символов и самому символу, которых повторяется друг за другом n-e количество раз. Если найден только один символ строка принимает значение равное этому символу.
Все выше описанные операции выполняются до тех пор, пока не будет достигнут конец файла.
Алгоритм кодирование информации представлен на рисунке 1.
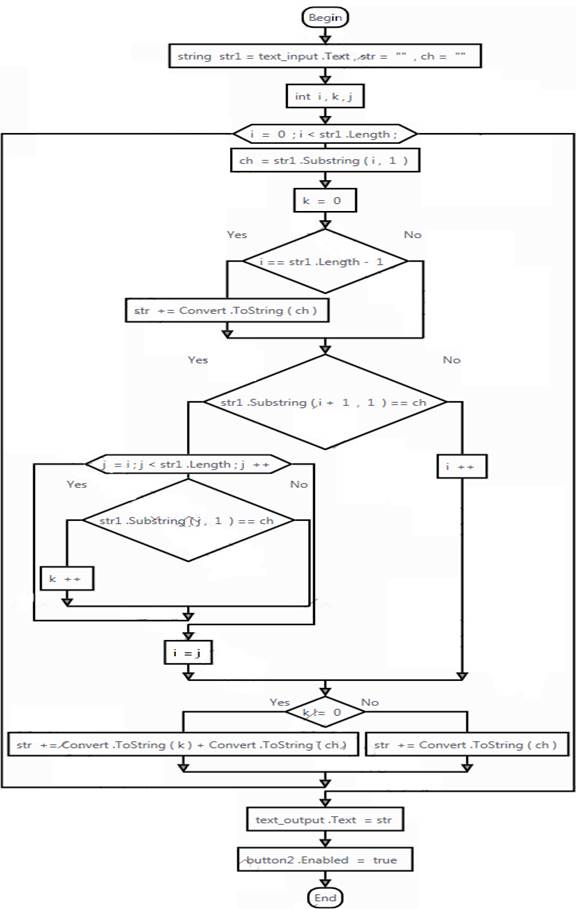
Рисунок 1 – алгоритм кодирования
string str1 = text_input.Text, str = "", ch = "";
int i, k, j;
for (i = 0; i < str1.Length;) { // от 0 до длины строки
ch = str1.Substring(i, 1); // получаем текущий символ из строки str1
k = 0; //счетчик количества повторяющихся символов
if (i == str1.Length - 1) { // если последний символ
str += Convert.ToString(ch);
break; //выходим из цикла
}
if (str1.Substring(i + 1, 1) == ch) {
for (j = i; j < str1.Length; j++) {
if (str1.Substring(j, 1) == ch) //если текущий символ равен символу из строки ch
k++; //увеличиваем счетчик
else
break; //выходим из цикла
}
i = j;
}
else
i++;
if (k!= 0)
str += Convert.ToString(k) + Convert.ToString(ch);
else
str += Convert.ToString(ch);
}
text_output.Text = str;
button2.Enabled = true;
Декодирование информации:
Кодировку успешно выполнили, теперь напишем декодировку строки, кодированную при помощи алгоритма RLE. Декодирование закодированной строки выполняется путем поиска числа, которое является количеством повторений символа и самого символа.
И так, получаем закодированную строку из текстового поля “textBox1” и записывает полученный текст в переменную “str1”. При каждом проходе цикла, который выполняется, пока недостигнут последний символ, записываем в переменную “ch” текущий символ и если он является цифрой, выполняем поиск цифр идущих друг за другом. Тем самым последовательность найденных цифр будет представлять собой число, являющееся количеством повторений символа, идущего сразу же после этой последовательности. В конце в строковую переменную “str” записываем букву столько раз, сколько равно значение числа.
Алгоритм декодирования информации представлен на рисунке 2.

Рисунок 2 – алгоритм декодирования.
string str1 = textBox1.Text, str = "", ch = "", s = "", symb = "";
int i, k = 0, j;
for (i = 0; i < str1.Length;) {
ch = str1.Substring(i, 1); // текущий символ i
k = 0;
s = "";
if ("0123456789".Contains(ch)) { // если символ ch является цифрой
for (j = i; j < str1.Length; j++) {
if ("0123456789".Contains(str1.Substring(j, 1)))
{ // если текущий символ j является цифрой
s += str1.Substring(j, 1);
}
else
break;
}
symb = str1.Substring(j, 1); // получаем букву
i = j + 1;
}
else
i++;
if (s.Length!= 0) {
for (j = 0; j < Convert.ToInt32(s); j++) // декодирование буквы
str += symb;
}
else
str += Convert.ToString(ch);
}
out_shifr.Text = str;
|
|
|
