 |


Основные правила перегрузки операций
|
|
|
|
1. Вводить собственные обозначения для операций, не совпадающие со стандартными операциями языка С++, нельзя.
2. Не все операции языка С++ могут быть перегружены. Нельзя перегрузить следующие операции:
‘. ’ – прямой выбор компонента,
‘ .* ’ – обращение к компоненту через указатель на него,
‘ ?: ’ – условная операция,
‘ :: ’ – операция указания области видимости,
‘sizeof’,
‘ # ’, ‘ ## ’– препроцессорные операции.
3. Каждая операция, заданная в языке, имеет определенное число операндов, свой приоритет и ассоциативность. Все эти правила, установленные для операций в языке, сохраняются и для ее перегрузки, т.е. изменить их нельзя.
4. Любая унарная операция Å определяется двумя способами: либо как компонентная функция без параметров, либо как глобальная (возможно дружественная) функция с одним параметром. Выражение Å z означает в первом случае вызов z.operator Å (), во втором–вызов operator Å (z).
5. Любая бинарная операция Å определяется также двумя способами: либо как компонентная функция с одним параметром, либо как глобальная (возможно дружественная) функция с двумя параметрами. В первом случае x Å y означает вызов x.operator Å (y), во втором – вызов operator Å (x,y).
6. Перегруженная операция не может иметь аргументы (операнды), заданные по умолчанию.
7. В языке С++ установлена идентичность некоторых операций, например ++z – это то же, что и z+=1. Эта идентичность теряется для перегруженных операций.
8. Функцию operator можно вызвать по ее имени, например z=operator*(x,y) или z=x.operator*(y). В первом случае вызывается глобальная функция, во втором – компонентная функция класса Х, и х – это объект класса Х. Однако чаще всего функция operator вызывается косвенно, например z=x*y
|
|
|
9. За исключением перегрузки операций new и delete функция operator должна быть либо нестатической компонентной функцией, либо иметь, как минимум, один аргумент (операнд) типа «класс» или «ссылка на класс» (если это глобальная функция).
10. Операции ‘ = ’, ‘ [] ’, ‘ –> ’ можно перегружать только с помощью нестатической компонентной функции operator Å. Это гарантирует, что первыми операндами будут леводопустимые выражения.
11. Операция ‘ [] ’ рассматривается как бинарная. Пусть а – объект класса А, в котором перегружена операция ‘ [] ’. Тогда выражение a[i] интерпретируется как a.operator[](i).
12. Операция ‘ () ’ вызова функции рассматривается как бинарная. Пусть а – объект класса А, в котором перегружена операция ‘ () ’. Тогда выражение a(x1,x2,x3,x4) интерпретируется как a.operator()(x1,x2,x3,x4).
13. Операция ‘ –> ’ доступа к компоненту класса через указатель на объект этого класса рассматривается как унарная. Пусть а – объект класса А, в котором перегружена операция ‘ –> ’. Тогда выражение a–>m интерпретируется как (a.operator–>())–>m. Это означает, что функция operator–>() должна возвращать указатель на класс А, или объект класса А, или ссылку на класс А.
14. Перегрузка операций ‘ ++ ’ и ‘ -- ‘, записываемых после операнда (z++, z--), отличается добавлением в функцию operator фиктивного параметра int, который используется только как признак отличия операций z++ и z-- от операций ++z и --z.
15. Глобальные операции new можно перегрузить и в общем случае они могут не иметь аргументов (операндов) типа “класс”. В результате разрешается иметь несколько глобальных операций new, которые различаются путем изменения числа и (или) типов аргументов.
16. Глобальные операции delete не могут быть перегружены. Их можно перегрузить только по отношению к классу.
17. Заданные в самом языке глобальные операции new и delete можно изменить, т.е. заменить версию, заданную в языке по умолчанию, на свою версию.
|
|
|
18. Локальные функции operator new() и operator delete() являются статическими компонентами класса, в котором они определены, независимо от того, использовался или нет спецификатор static (это, в частности, означает, что они не могут быть виртуальными).
19. Для правильного освобождения динамической памяти под базовый и производный объекты следует использовать виртуальный деструктор.
20. Если для класса Х операция “=” не была перегружена явно и x и y–это объекты класса Х, то выражение x=y задает по умолчанию побайтовое копирование данных объекта y в данные объекта x.
21. Функция operator вида operator type() без возвращаемого значения, определенная в классе А, задает преобразование типа А к типу type.
22. За исключением операции присваивания ‘ = ’ все операции, перегруженные в классе Х, наследуются в любом производном классе Y.
23. Пусть Х – базовый класс, Y – производный класс. Тогда локально перегруженная операция для класса Х может быть далее повторно перегружена в классе Y.
Примеры программ
Программа 1.
Задание: определить и реализовать класс “complex”- комплексное число. Для сложения чисел определить в классе функцию и перегруженную операцию. Предусмотреть счетчик созданных в программе чисел.
Файл “complex.h”
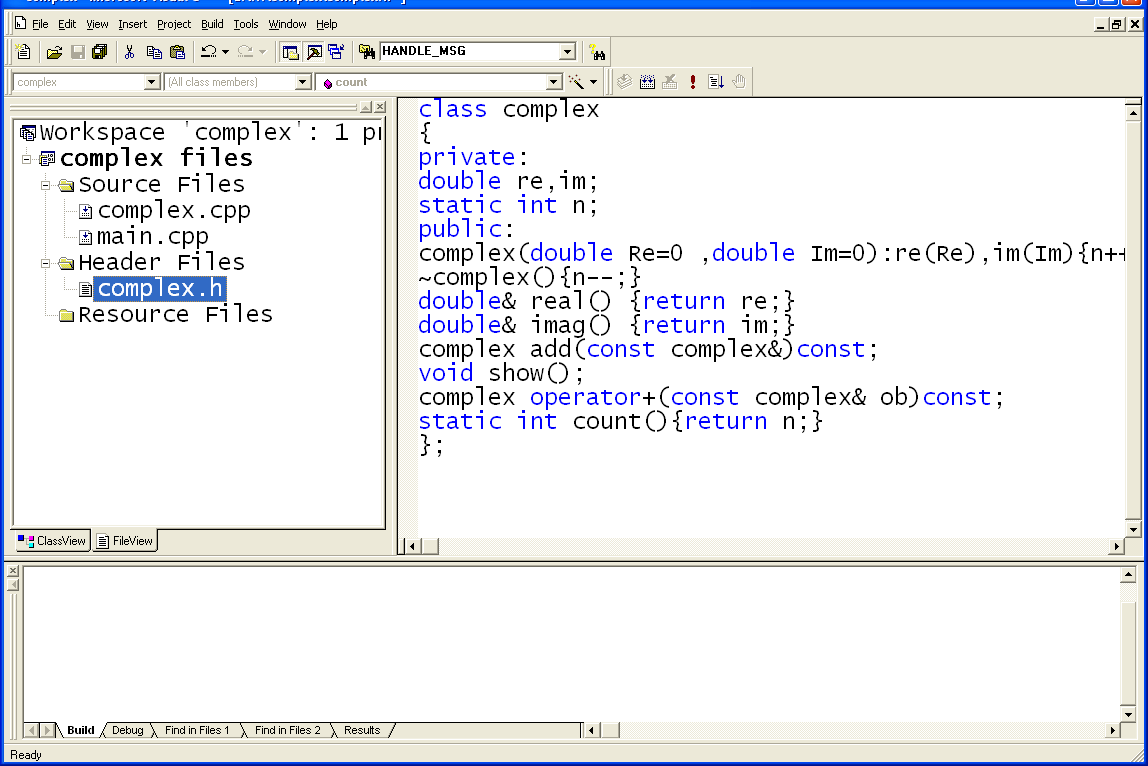
class complex
{
private:
double re,im;
static int n; //счетчик объектов
public:
complex(double Re=0,double Im=0):re(Re),im(Im){n++;};
~complex(){n--;}
double& real() {return re;}
double& imag() {return im;}
//функции для сложения чисел
complex add(const complex&)const;
//функции для вывода числа
void show();
//перегруженная операция сложения чисел
complex operator+(const complex& ob)const;
static int count(){return n;}
};
Файл “complex.cpp”

#include<iostream.h>
#include"complex.h"
void complex::show()
{
cout<<"re="<<re<<" im="<<im<<endl;
}
complex complex::add(const complex& ob)const
{
complex temp;
temp.re=re+ob.re;
temp.im=im+ob.im;
return temp;
}
complex complex::operator+(const complex& ob)const
{
complex temp;
temp.re=re+ob.re;
temp.im=im+ob.im;
return temp;
}
Файл “main.cpp”
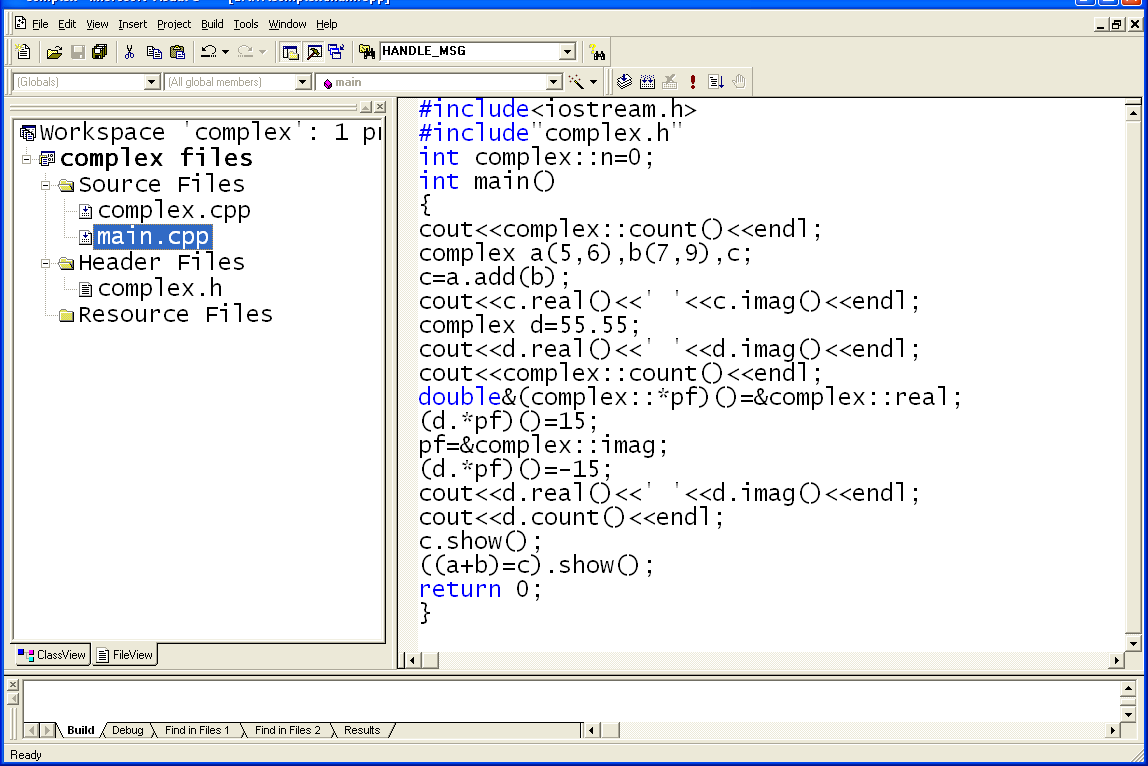
#include<iostream.h>
#include"complex.h"
int complex::n=0;//
int main()
{
//Чисел еще нет, статическая функция возвращает 0
cout<<complex::count()<<endl;
complex a(5,6),b(7,9),c;
//сложение чисел a и b, результат в с
//используем автоматически созданную операцию-функцию
//присваивания
c=a.add(b);
cout<<c.real()<<' '<<c.imag()<<endl;
complex d=55.55;
cout<<d.real()<<' '<<d.imag()<<endl;
|
|
|
//Сейчас имеется три числа-функция возвращает 3
cout<<complex::count()<<endl;
//вводим указатель на функцию и инициализируем его
double&(complex::*pf)()=&complex::real;
//используя указатель на функцию, изменяем
// действительную часть числа d
(d.*pf)()=15;
//изменяем значение указателя на функцию
//сейчас он указывает на функцию imag
pf=&complex::imag;
//используя указатель на функцию, изменяем
// мнимую часть числа d
(d.*pf)()=-15;
cout<<d.real()<<' '<<d.imag()<<endl;
cout<<d.count()<<endl;
//показываем число с
c.show();
//демонстрируем, что перегруженные операции сложения
//и присваивания возвращают объект
((a+b)=c).show();
return 0;
}
Шаблоны функций и классов
Шаблоны функций
Шаблоны являются одой из важных особенностей С++.
Причина этого заключается в том, что шаблоны фундаментально изменяют внешнюю сторону программирования. Используя шаблон, можно создать обобщенные спецификации для функций и для классов, которые называются параметризованными функциями (generic functions) и параметризованными классами (generic classes). Параметризованная функция определяет общую процедуру, которая может быть применена к данным различных типов. Параметризованный класс определяет общий класс, который может применяться к различным типам данных. В обоих случаях конкретный тип данных, над которыми выполняется операция, передается в качестве параметра.
Причина использования параметризованных функций заключается в следующем.
Многие алгоритмы не зависят от типа данных, которыми они манипулируют. Например, обмен значениями
TData temp,x,y;
//...
temp=x; x=y; y=temp;
Этот алгоритм работает вне зависимости от фактического значения типа данных TData. Однако в большинстве языков программирования для обмена данными каждого типа требуется написание новой версии подпрограммы, несмотря на то, что лежащий в ее основе алгоритм остается неизменным.
Многие алгоритмы допускают отделение метода от данных. При использовании таких алгоритмов большим преимуществом была бы возможность однократного определения и отладки логики алгоритма и последующее применение алгоритма к различным типам данных без необходимости перепрограммирования. Это не только позволяет экономить усилия и время, но и страхует от ошибок.
|
|
|
Итак, обобщенные параметризованные процедуры предоставляют очевидные преимущества. Поэтому программисты всегда пытались их использовать. Однако до изобретения шаблонов такие попытки имели лишь частичный успех. Появились два далеких от совершенствования метода.
Первый заключается в построении параметризированных функций через использование макросов. Например, макрос создает «родовую функцию», возвращающую абсолютное значение числа.
# define ABS(a)
((a<0)?–(a):(a))
...
int x;
float f;
x=ABS(-10);
f=ABS(15.25);
Однако добиться работы макросов с типами данных, определенными пользователем, достаточно сложно. Кроме того, поскольку этот макросы не выполняет никакой проверки типов, возможна ситуация, когда он будет ошибочно использован с такими типами данных, для которых не определены используемые в нем операции. Также не для всех алгоритмов можно написать макрос.
Второй метод построения параметризованной функции заключается в добавлении одного или нескольких параметров, предназначенных для определения типов данных, над которыми функция выполняет операции. Например, распространенным подходом была передача функции указателя на данные в качестве одного параметра и размера этих данных в байтах – в качестве другого (например, указатель типа void*).
Примером может служить библиотечная функция qsort().
void qsort(void* buf,size_t num,size_t size,int(*comp)(const void*,const void*));
Но поскольку параметры передаются через стек, передача каждого параметра генерирует несколько инструкций в машинном коде, что уменьшает эффективность кода, увеличивая время, требующееся для вызова функции.
Так, функция qsort() обычно реализуется как рекурсивная функция, и поэтому наличие дополнительных параметров приводит к значительному снижению ее производительности.
В С++ параметризированная функция создается с помощью ключевого слова template. Шаблон определяет общий набор операций (алгоритм), которые будут применяться к данным различных типов. При этом тип данных, над которыми функция должна выполнять операции, передается ей в виде параметра на стадии компиляции. Формат функции-шаблона:
template <class тип_данных> тип_возвр_значения имя_функции(список_параметров)
{тело_функции}
Параметр тип_данных обозначает тип данных, используемых функцией. Это имя может использоваться в пределах действия определения функции. Когда компилятор будет создавать конкретную версию этой функции, он автоматически заменит этот параметр конкретным типом данных. Можно определить несколько родовых типов данных, которые в списке должны отделяться друг от друга запятыми. Каждый элемент данного списка предваряется ключевым словом class, которое в данном контексте ссылается не на конкретный тип данных class, а на любой тип данных, фактически передаваемый при вызове функции (встроенный либо определенный программистом). Это так называемые параметры–шаблоны.
|
|
|
Пример 4.1.1. Шаблон функции для обмена значениями.
template <class Stype> void swap(Stype& x,Stype& y)
{Stype temp;
temp=x; x=y; y=temp;}
Хотя функция-шаблон по мере надобности может перегружать себя сама, можно выполнять ее явную перегрузку. Если параметризованная функция перегружается явно, то эта перегруженная функция «скрывает» параметризованную функцию по отношению к конкретной версии.
Пример 4.1.2. Сортировка методом обмена
# include <iostream.h>
# include <string.h>
template <class Stype> void bubble(Stype* item,int count);
void main()
{
// сортировка массива символов
char str[]=”dcab”;
bubble(str,strlen(str));//здесь компилятор построит функцию
//сортировки для данных типа char,
// т.е. Stype заменится на char
cout<<str<<endl;
// сортировка массива целых чисел
int nums[]={5,7,3,9,5,1,8};
int i;
bubble(nums,7);//а здесь компилятор построит
//функцию сортировки для данных типа int
for(i=0;i<7;i++) cout<<nums[i]<<” “;
cout<<endl;
}
// Определение параметризованной функции
template <class Stype> void bubble(Stype* item,int count)
{register int i,j;
Stype temp;
for(i=1;i<count;i++)
for(j=count-1;j>=i;--j)
if(item[j-1]>item[j])
{temp=item[j-1];
item[j-1]=item[j];
item[j]=temp;
}
}
Можно считать, что параметры шаблона функции являются его формальными параметрами, а типы тех параметров, которые используются в конкретных обращениях к функции, служат фактическими параметрами шаблона.
При первом вызове функции с конкретными типами параметром компилятор построит функцию для параметров этого типа. Естественно, операции, используемые в функции, должны быть определены для этих типов.
Перечислим основные свойства параметров шаблона функции:
Имена параметров шаблона должны быть уникальными во всем определении шаблона.
1. Список параметров шаблона не может быть пустым.
2. В списке параметров шаблона может быть несколько параметров и каждому из них должно предшествовать ключевое слово class.
3. Имя параметра шаблона имеет все права имени типа в определенной шаблоном функции.
4. Все параметры шаблона должны быть обязательно использованы в спецификациях параметров определения функции. Например, будет ошибочным такой шаблон:
template <class A,class B,class C> C func(A x,B y)
{C temp;...}
Здесь остался неиспользованным параметр шаблона с именем C.
5. Определенная с помощью шаблона функция может иметь любое количество непараметризованных формальных параметров. Может быть не параметризовано и возвращаемое функцией значение.
6. В списке параметров прототипа шаблона имена параметров не обязаны совпадать с именами тех же параметров в определении шаблона.
7. При конкретизации параметризованной функции необходимо, чтобы при вызове функции типы фактических параметров, соответствующие одинаково параметризованным формальным параметрам, были одинаковы.
8. При использовании шаблонов функций возможна перегрузка, как шаблонов, так и функций. Могут быть шаблоны с одинаковыми именами, но разными параметрами. Или с помощью шаблона может создаваться функция с таким же именем, что и явно определенная функция. В обоих случаях “распознавание” конкретного вызова выполняется по сигнатуре, т.е. по типам, порядку и количеству фактических параметров.
Шаблоны классов
Шаблон класса используется для построения родового класса. При создании родового класса создается целое семейство родственных классов, которые можно применять к любому типу данных. Таким образом, тип данных, которым оперирует класс, указывается в качестве параметра при создании объекта, принадлежащего к этому классу. Принципиальное преимущество параметризованного класса заключается в том, что он позволяет определить члены класса один раз, но применять класс к данным любых типов. Подобно тому, как класс определяет правила построения и формат отдельных объектов, шаблон класса определяет способ построения отдельных классов. В определении класса, входящего в шаблон, имя класса является не именем отдельного класса, а параметризованным именем семейства классов.
Наиболее широкое применение шаблоны классов находят при создании контейнерных классов. Фактически создание контейнеров является одной из основных причин, по которым были введены в употребление шаблоны.
Контейнерными классами (контейнерами) называются классы, в которых хранятся организованные данные. Например, массивы и связные списки. Преимущество, даваемое определением параметризованных контейнерных классов, заключается в том, что, как только логика, необходимая для поддержки контейнера, определена, он может применяться к любым типам данных без необходимости его переписывания. Например, параметризованный контейнер связного списка можно использовать для построения списков, содержащих почтовые адреса, заглавия книг, названия автомобилей.
Общая форма объявления параметризованного класса:
template <class тип_данных> class имя_класса {... };
Здесь тип_данных представляет собой имя типа шаблона, которое в каждом случае конкретизации будет замещаться фактическим типом данных. При необходимости можно использовать более одного параметризованного типа данных, используя список с разделителем – запятой. В пределах определения класса имя тип_данных можно использовать в любом месте.
Создав параметризованный класс, можно создать конкретную реализацию этого класса, используя следующую общую форму:
имя_класса <тип> имя_объекта;
Здесь тип представляет собой имя типа данных, над которыми фактически оперирует класс, и заменяет собой переменную тип_данных.
Перечислим основные свойства шаблонов классов:
1. Компонентные функции параметризованного класса автоматически являются параметризованными. Их не обязательно объявлять как параметризованные с помощью template.
2. Дружественные функции, которые описываются в параметризованном классе, не являются автоматически параметризованными функциями, т.е. по умолчанию такие функции являются дружественными для всех классов, которые организуются по данному шаблону.
3. Если friend-функция содержит в своем описании параметр типа параметризованного класса, то для каждого созданного по данному шаблону класса имеется собственная friend-функция.
4. В рамках параметризованного класса нельзя определить friend-шаблоны (дружественные параметризованные классы).
5. С одной стороны, шаблоны могут быть производными (наследоваться) как от шаблонов, так и от обычных классов, с другой стороны, они могут использоваться в качестве базовых для других шаблонов или классов.
6. Определенные пользователем имена в описании шаблона по умолчанию рассматриваются как идентификаторы переменных. Чтобы имя рассматривалось как идентификатор типа, оно должно быть определено внутри шаблона или в окружающей области определения через ключевое слово typename.
7. Шаблоны функций, которые являются членами классов, нельзя описывать как virtual.
8. Локальные классы не могут содержать шаблоны в качестве своих элементов.
|
|
|
