 |


Регрессионно-факторный анализ технологических моделей.
|
|
|
|
Данная практическая работа выполняется методом творческих заданий. Предлагается использовать таблицы экспериментальных данных, полученных студентами заранее во время занятий научной работой. При решении творческих заданий, студенты могут выполнять роль экспертов, помогая другим студентам в группе найти правильное решение. Экспертами выбираются студенты, быстро построившие модель процесса.
Регрессионный анализ позволяет оценить степень связи между переменными, предлагая механизм вычисления предполагаемого значения y = 0,8551Ln(x) + 4,6586 переменной из нескольких уже известных значений.
В состав M. Excel входит набор средств анализа данных (пакет анализа), предназначенный для решения сложных статистических и инженерных задач. Для анализа данных следует указать входные данные и выбрать параметры; анализ будет выполнен с помощью подходящей статистической или инженерной макрофункции, а результат будет помещен в выходной диапазон. Другие средства позволяют представить результаты анализа в графическом виде. Средства, включенные в пакет анализа данных, доступны через команду Анализ данных меню Сервис. Если этой команды нет в меню, необходимо загрузить надстройку Пакет анализа.
Цель работы: проанализировать влияние функционально-технологических свойств рецептурных смесей на основе регрессионно-факторного анализа.
Пример: В лабораторных условиях было исследовано влияние ферментного препарата глюкозооксидазы (х2) в сочетании с аскорбиновой кислотой (х1) на качество хлеба (табл.). Необходимо с помощью ЭВМ расчитать, какой фактор (х1 илих2) оказывает большее влияние на пористость хлеба; построить эмпирическую линейную модель зависимости пористости хлеба y от фактора х1 или х2, оказывающего на него большее влияние; выявить, как изменится пористость хлеба, если величину глюкозооксидазы увеличить на 30% от среднего значения выборки.
|
|
|
Таблица 3- Влияние ферментного препарата глюкозооксидазы в сочетании с аскорбиновой кислотой на качество хлеба
| Количество аскорбиновой кислоты х1, % | Количество глюкозооксидазы х2, % | Пористость y, % |
| 0,003 | 0,0146 | |
| 0,003 | 0,0853 | |
| 0,017 | 0,0146 | |
| 0,017 | 0,0854 | |
| 0,000 | 0,0500 |
1. Создадим шаблон-таблицу в M. Excel.
2. Определим, какой фактор (количество аскорбиновой кислоты х1 или количество глюкозооксидазы х2) оказывает большее влияние на пористость хлеба с помощью коэффициента регрессии. Для этого построим матрицу коэффициентов корреляции: Сервис → Анализ данных → Корреляция (рис. 4).

Рисунок 4 – Определение матрицы коэффициентов корреляции
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция). Коэффициент корреляции, как ковариационный анализ, характеризует область, в которой два измерения изменяются вместе. Коэффициент масштабируется таким образом, что его значение не зависит от единиц, в которых выражены переменные двух измерений.
Таблица 4- Матрица коэффициентов корреляции
| Количество аскорбиновой кислоты х1, % | Количество глюкозооксидазы х2, % | Пористость y, % | |
| Количество аскорбиновой кислоты х1, % | |||
| Количество глюкозооксидазы х2, % | 0,000351665 | ||
| Пористость y, % | 0,304572452 | -0,88317 |
Любое значение коэффициента корреляции должно находится в диапазоне от –1 до +1 включительно. Чем ближе по модулю коэффициент корреляции rхук 1, тем теснее связь между х и у. Если │rх1у│>│rх2у│, то фактор х1 оказывает большее влияние на у, чем х2. В результате имеем: rх1у = 0,304572452 – связь (между х1 и у) слабая;
|
|
|
rх2у = -0,88317– связь (между х2 и у) умеренная обратная (т.е. с увеличением количества глюкооксидазы, пористость хлеба уменьшается).
Значит │rх1у│<│rх2у│, поэтому фактор х1 оказывает меньшее влияние на у, чем х2. Следовательно, будем строить эмпирическую зависимость Метка помечается, если в выделенном диапазоне содержатся имена столбцов Диапазон входных данных выделяется блоком пористости хлеба у от количества глюкооксидазы х2.
Построим эмпирическую модель зависимости пористости хлеба у от количества глюкооксидазы х2. Для этого используем встроенный пакет регрессионного анализа: Сервис → Анализ данных → Регрессия (рис. 5).
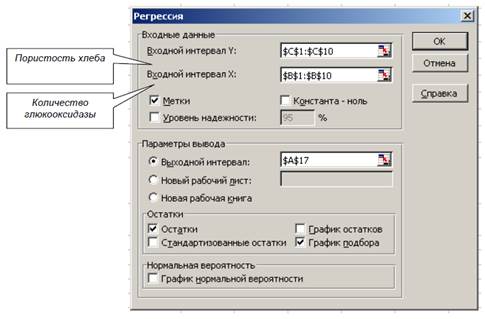
Рисунок 5 – Вид окна пакета «Регрессия»
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов.
Получили зависимость: y=87,3– 29,1х2. Коэффициент детерминации R2=0,78, т.е. доля вариации у объясняется лишь на 78% вариацией (есть смысл «улучшить» модель для вычисления значения).
|
|
|
