 |


Попиксельное итеративное утоньшение бинарного изображения
|
|
|
|
В этом курсовом проекте для утоньшения изображенений используется метод попиксельного итеративного утоньшения. Метод заключается в том, что «окошко» 3х3 перемещается по изображению слева направо сверху вниз и каждому пикселю, попадающему в центр «окошка» (пиксель P) применяется набор правил, на основании которых центральный пиксель отмечается на удаление. После окончания одного прохода все отмеченные пиксели удаляются, по оставшемуся изображению выполняется новый проход по тому же принципу. Алгоритм завершает работу, когда за весь проход ни один пиксель не был отмечен на удаление.
Удаление пикселя выполняется при соблюдении всех из ниже перечисленных условий:
·У пикселя P должен быть как минимум один белый сосед по четырех связности;
·У пикселя P должно быть не менее двух черных соседей по восьми связности;
·Как минимум один из черных соседей по восьми связности должен быть неотмеченным;
·Пиксель P не должен быть точкой разрыва;
·Если пиксель P2 (сверху от пикселя P) отмечен на удаление, то закрашивание пикселя P2 белым цветом не сделает пиксель P точкой разрыва;
·Если пиксель P4 (слева от пикселя P) отмечен на удаление, то закрашивание пикселя P4 белым цветом не сделает пиксель P точкой разрыва.
Пример результата утоньшения для ключевого слова «bedroom» представлен на рисунке 3.4.1.

 Рисунок 3.4.1 – Результат работы попиксельного итеративного утоньшения.
Рисунок 3.4.1 – Результат работы попиксельного итеративного утоньшения.
Распознавание
Для распознавания изображения ключевого слова среди изображений претендентов было решено делать на основании набора информативных признаков, при этом при подсчете таких признаков изображение было разделено на две части. На рисунке 3.5.1 видно, что все что выше линии — относится к верхней половине, а все что ниже линии — к нижней. Для каждой из половины признаки считаются отдельно.
|
|
|
 Рисунок 3.5.1 — разделение изображения на две части.
Рисунок 3.5.1 — разделение изображения на две части.
Набор информативных признаков формируется на основании концевых точек, узловых точек, а также количество пикселей с 3, 4 и 5 черными пикселями-соседями.
На рисунке 3.5.2 стрелками показаны пиксели, являющиеся концевыми.
 Рисунок 3.5.2 — пример концевых пикселей на изображении слова «bedroom»
Рисунок 3.5.2 — пример концевых пикселей на изображении слова «bedroom»
Можно заметить, что на изображении слова «bedroom» в верхней части 3 концевых пикселя, а в нижней части 5 концевых пикселей.
Для определения того, что пиксель является концевым, необходимо рассчитать несколько характеристических чисел:
1);
2);
3);
4);
5) - число четырех связности;
6) - число переходов с 0 на 1.
На основании приведенных характеристических чисел определяется, является ли пиксель концевым, для этого должны выполняться условия:
1) A8 = 1
2) Nc4 = 1
3) CN = 1
При выполнении всех трех условий пиксель считается концевым и добавляется к общему количеству пикселей для исследуемой половины изображения. Данная сумма будет являться одним из признаков для распознавания.
Для распознавания выделенных слов претендентов используется метод двух ближайших соседей.
Реализация этого метода предполагает создание структуры для каждого слова, которая содержат наборы различных информативных признаков, в нашем случае это сумма концевых пикселей в верхней части изображения и сумма концевых пикселей в нижней части изображения Алгоритм работает следующим образом: при распознавании очередного слова, используя информативные признаки, производится расчет евклидового расстояния от слова эталона (ключевое слово на нашем изображении) до каждого слова в структуре признаков. Два минимальных из этих расстояний и определяет распознанные изображения слов.
|
|
|
Минимальное количество признаков обусловлено тем, что при таком подходе большой набор признаков приводит к перекрывании одних признаков другими, и при совершенно разных значениях различных признаков суммарное расстояние может получиться одинаковым. В связи с этим экспериментальным путем были выделены наиболее значимые информативные признаки, которые и используются для распознавания, а именно количество концевых пикселей в верхней половине изображения и количество концевых пикселей в нижней части изображения. Такой набор дает хороший процент распознавания.
Для корректировки результатов описанного выше алгоритма можно добавить зонды, которые будут считать количество черных пикселей, например, в верхней и нижней части изображения по горизонтали, либо вертикальные зонды для букв в слове (рисунок 3.5.3).
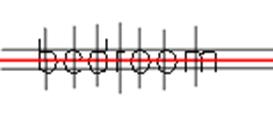 Рисунок 3.5.3 — пример использования зондов.
Рисунок 3.5.3 — пример использования зондов.
4. ПРОГРАММНАЯ РЕАЛИЗАЦИЯ
|
|
|
