 |


Распределённая база данные компьютерный
|
|
|
|
Проблемы распределенных баз данных
Исходя из определения Дэйта, распределенную базу данных в общем случае можно рассматривать как слабосвязанную сетевую структуру, узлы которой представляют собой локальные базы данных. Локальные базы данных автономны, независимы и самоопределены; доступ к ним обеспечивается от различных поставщиков. Связи между узлами — это потоки тиражируемых данных. Топология DDB варьируется в широком диапазоне: возможны варианты иерархии, структур типа звезда и т. д. В целом топология DDB определяется географией информационной системы и направленностью потоков тиражирования данных.
Рассмотрим теперь проблемы реальных распределенных баз данных [5]. Проблемы централизованных СУБД существуют и здесь, однако децентрализация добавляет новые:
а) Какова общая модель данных распределенной системы? Мы должны иметь единую концептуальную схему всей сети. Это обеспечит логическую прозрачность данных для пользователя, в результате чего он сможет формировать запрос ко всей базе, находясь за отдельным терминалом (т. е. как бы работая с централизованной базой данных).
б) Необходима схема, определяющая местонахождение данных в сети. Это обеспечит прозрачность размещения данных, благодаря которой пользователь может не указывать, куда переслать запрос, чтобы получить требуемые данные.
в) Распределенные базы данных могут быть однородными или неоднородными по аппаратным и программным средствам. Проблему неоднородности сравнительно легко решить, если распределенная база является неоднородной по аппаратным средствам, но однородной по программным средствам (одинаковые СУБД в узлах). Если же в узлах распределенной системы используются разные СУБД, необходимы средства преобразования структур данных и языков. Это должно обеспечить прозрачность преобразования в узлах распределенной базы данных.
|
|
|
г) Управление словарями. Для обеспечения всех видов прозрачности в распределенной базе данных нужны программы, управляющие многочисленными справочниками или словарями.
д) Методы выполнения запросов в распределенной базе данных отличаются от аналогичных методов централизованных СУБД, так как отдельные части запроса нужно выполнять в месторасположении соответствующих данных и передавать частичные результаты на другие узлы; при этом должна быть обеспечена координация всех процессов.
е) В распределенной базе данных нужен сложный механизм управления одновременной обработкой, который, в частности, должен обеспечивать синхронизацию при обновлениях информации, это гарантирует непротиворечивость данных.
ж) Развитая методология распределения и размещения данных, включая разбиение, является одним из основных требований к распределенной базе данных.
База данных физически распределяется по узлам компьютерной информационной системы при помощи фрагментации и репликации (тиражирования) данных.
Особенности распределенных баз данных
В сегодняшнем быстро меняющемся компьютерном мире сосуществуют по крайней мере три основные идеологии: клиент - сервер, Web и распределенные объекты (DCOM, CORBA). Внутри каждого направления также существует большое количество решений и стандартов от разных производителей. Сегодняшняя ситуация вызывает очень большую озабоченность независимых разработчиков и потребителей: Какую технологию выбрать и что будет со мной и моим бизнесом, если я приму неправильное решение? При этом очевидно, что цена ошибки будет весьма высока, кроме того большие средства уже вложены в разработку и эксплуатацию уже существующих систем.
|
|
|
Клиент-сервер
Термин "клиент-сервер" означает такую архитектуру программного комплекса, в которой его функциональные части взаимодействуют по схеме "запрос-ответ". Если рассмотреть две взаимодействующие части этого комплекса, то одна из них (клиент) выполняет активную функцию, т. е. инициирует запросы, а другая (сервер) пассивно на них отвечает. По мере развития системы роли могут меняться, например некоторый программный блок будет одновременно выполнять функции сервера по отношению к одному блоку и клиента по отношению к другому [6].
Любая информационная система должна иметь минимум три основные функциональные части - модули хранения данных, модули обработки и модули интерфейса с пользователем. Каждая из этих частей может быть реализована независимо от двух других. Например, не изменяя программ, используемых для хранения и обработки данных, можно изменить интерфейс с пользователем таким образом, что одни и те же данные будут отображаться в виде таблиц, графиков или гистограмм. Не меняя программ представления данных и их хранения, можно изменить программы обработки, например изменив алгоритм полнотекстового поиска. И наконец, не меняя программ представления и обработки данных, можно изменить программное обеспечение для хранения данных, перейдя, например, на другую файловую систему.
В классической архитектуре клиент-сервер приходится распределять три основные части приложения по двум физическим модулям. Обычно ПО хранения данных располагается на сервере (например, сервере базы данных), интерфейс с пользователем - на стороне клиента, а вот обработку данных приходится распределять между клиентской и серверной частями. В этом-то и заключается основной недостаток двухуровневой архитектуры, из которого следуют несколько неприятных особенностей, сильно усложняющих разработку клиент-серверных систем.
При разбиении алгоритмов обработки данных необходимо синхронизировать поведение обеих частей системы. Все разработчики должны иметь полную информацию о последних изменениях, внесенных в систему, и понимать эти изменения. Это создает большие сложности при разработке клиент-серверных систем, их установке и сопровождении, поскольку необходимо тратить значительные усилия на координацию действий разных групп специалистов. В действиях разработчиков часто возникают противоречия, а это тормозит развитие системы и вынуждает изменять уже готовые и проверенные элементы.
|
|
|
Чтобы избежать несогласованности различных элементов архитектуры, пытаются выполнять обработку данных на одной из двух физических частей - либо на стороне клиента ("толстый" клиент), либо на сервере ("тонкий" клиент, или архитектура, называемая "2,5- уровневый клиент-сервер"). Каждый подход имеет свои недостатки. В первом случае неоправданно перегружается сеть, поскольку по ней передаются необработанные, а значит, избыточные данные. Кроме того, усложняется поддержка системы и ее изменение, так как замена алгоритма вычислений или исправление ошибки требует одновременной полной замены всех интерфейсных программ, а иначе могут возникнуть ошибки или несогласованность данных. Если же вся обработка информации выполняется на сервере (когда такое вообще возможно), то возникает проблема описания встроенных процедур и их отладки. Дело в том, что язык описания встроенных процедур обычно является декларативным и, следовательно, в принципе не допускает пошаговой отладки. Кроме того, систему с обработкой информации на сервере абсолютно невозможно перенести на другую платформу, что является серьезным недостатком.
Многие средства быстрой разработки приложений (RAD), которые работают с различными базами данных, реализует первую стратегию, т. е. "толстый" клиент обеспечивает интерфейс с сервером базы данных через встроенный SQL. Такой вариант реализации системы с "толстым" клиентом, кроме перечисленных выше недостатков, обычно обеспечивает недопустимо низкий уровень безопасности. Например, в банковских системах приходится всем операционистам давать права на запись в основную таблицу учетной системы. Кроме того, данную систему почти невозможно перевести на Web-технологию, так как для доступа к серверу базы данных используется специализированное клиентское ПО.
|
|
|
Рассмотренные выше модели имеют следующие недостатки.
1. "Толстый" клиент:
· сложность администрирования;
· усложняется обновление ПО, поскольку его замену нужно производить одновременно по всей системе;
· усложняется распределение полномочий, так как разграничение доступа происходит не по действиям, а по таблицам;
· перегружается сеть вследствие передачи по ней необработанных данных;
· слабая защита данных, поскольку сложно правильно распределить полномочия.
2. "Толстый" сервер:
· усложняется реализация, так как языки типа PL/SQL не приспособлены для разработки подобного ПО и нет хороших средств отладки;
· производительность программ, написанных на языках типа PL/SQL, значительно ниже, чем созданных на других языках, что имеет важное значение для сложных систем;
· программы, написанные на СУБД-языках, обычно работают недостаточно надежно; ошибка в них может привести к выходу из строя всего сервера баз данных;
· получившиеся таким образом программы полностью непереносимы на другие системы и платформы.
Для решения перечисленных проблем используются многоуровневые (три и более уровней) архитектуры клиент-сервер.
Многоуровневая архитектура клиент-сервер — разновидность архитектуры клиент-сервер, в которой функция обработки данных вынесена на один или несколько отдельных серверов. Это позволяет разделить функции хранения, обработки и представления данных для более эффективного использования возможностей серверов и клиентов.
Частный случаи многоуровневой архитектуры - трёхуровневая (трехзвенная) архитектура.
Трёхзвенная архитектура предполагает наличие следующих компонентов приложения: клиентское приложение (обычно говорят «тонкий клиент» или терминал), подключенное к серверу приложений, который в свою очередь подключен к серверу базы данных.
«Тонкий клиент» или Терминал — это интерфейсный (обычно графический) компонент, который представляет собственно приложение для конечного пользователя. Первый уровень не должен иметь прямых связей с базой данных (по требованиям безопасности), быть нагруженным основной бизнес-логикой и хранить состояние приложения (по требованиям надежности). На первый уровень может быть вынесена и обычно выносится простейшая бизнес-логика: интерфейс авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и соответствие формату, несложные операции (сортировка, группировка, подсчет значений) с данными, уже загруженными на терминал.
|
|
|
Сервер приложений располагается на втором уровне. На втором уровне сосредоточена бо́льшая часть бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы, а также погруженные в третий уровень хранимые процедуры и триггеры.
Сервер базы данных обеспечивает хранение данных и выносится на третий уровень. Обычно это стандартная реляционная или объектно-ориентированная СУБД. Если третий уровень представляет собой базу данных вместе с хранимыми процедурами, триггерами и схемой, описывающей приложение в терминах реляционной модели, то второй уровень строится как программный интерфейс, связывающий клиентские компоненты с прикладной логикой базы данных.
В простейшей конфигурации физически сервер приложений может быть совмещён с сервером базы данных на одном компьютере, к которому по сети подключается один или несколько терминалов.
В «правильной» (с точки зрения безопасности, надёжности, масштабирования) конфигурации сервер базы данных находится на выделенном компьютере (или кластере), к которому по сети подключены один или несколько серверов приложений, к которым, в свою очередь, по сети подключаются терминалы.
Технология клиент-сервер по праву считается одним из "китов", на которых держится современный мир компьютерных сетей. Но те задачи, для решения которых она была разработана, постепенно уходят в прошлое, и на сцену выходят новые задачи и технологии, требующие переосмысления принципов клиент-серверных систем. Одна из таких технологий - World Wide Web.
Многоуровневые клиент-серверные системы достаточно легко можно перевести на Web-технологию - для этого достаточно заменить клиентскую часть универсальным или специализированным браузером, а сервер приложений дополнить Web-сервером и небольшими программами вызова процедур сервера. Реализация этого принципа основана на использовании либо HTTP-SQL, либо API (организация динамических приложений на стороне сервера), либо Java (JDBC - организация динамических приложений на стороне клиента) интерфейсов для формирования запросов пользователя к базам данных или к другим информационным источникам на получение и обработку информации.
Следует отметить и тот факт, что в трехуровневой системе по каналу связи между сервером приложений и базой данных передается достаточно много информации. Однако это не замедляет вычислений, так как для связи указанных элементов можно использовать более скоростные линии. Это потребует минимальных затрат, поскольку оба сервера обычно находятся в одном помещении. Таким образом, увеличивается суммарная производительность системы - над одной задачей теперь работают два различных сервера, а связь между ними можно осуществлять по наиболее скоростным линиям с минимальными затратами средств. Правда, возникает проблема согласованности совместных вычислений, которую призваны решать менеджеры транзакций - новые элементы многоуровневых систем.
Менеджеры транзакций
Особенностью многоуровневых архитектур является использование менеджеров транзакций (МТ), которые позволяют одному серверу приложений одновременно обмениваться данными с несколькими серверами баз данных. Хотя серверы Oracle имеют механизм выполнения распределенных транзакций, но если пользователь хранит часть информации в БД Oracle, часть в БД Informix, а часть в текстовых файлах, то без менеджера транзакций не обойтись. МТ используется для управления распределенными разнородными операциями и согласования действий различных компонентов информационной системы. Следует отметить, что практически любое сложное ПО требует использования менеджера транзакций. Например, банковские системы должны осуществлять различные преобразования представлений документов, т. е. работать одновременно с данными, хранящимися как в базах данных, так и в обычных файлах, - именно эти функции и помогает выполнять МТ.
Менеджер транзакций - это программа или комплекс программ, с помощью которых можно согласовать работу различных компонентов информационной системы [7]. Логически MT делится на несколько частей:
· коммуникационный менеджер (Communication Manager) контролирует обмен сообщениями между компонентами информационной системы;
· менеджер авторизации (Authorisation Manager) обеспечивает аутентификацию пользователей и проверку их прав доступа;
· менеджер транзакций (Transaction Manager) управляет распределенными операциями;
· менеджер ведения журнальных записей (Log Manager) следит за восстановлением и откатом распределенных операций;
· менеджер блокировок (Lock Manager) обеспечивает правильный доступ к совместно используемым данным.
Обычно коммуникационный менеджер объединен с авторизационным, а менеджер транзакций работает совместно с менеджерами блокировок и системных записей. Причем такой менеджер редко входит в комплект поставки, поскольку его функции (ведение записей, распределение ресурсов и контроль операций), как правило, выполняет сама база данных (например, Oracle).
Первые менеджеры транзакций появились в начале 70-х гг. (например, CICS); с тех пор они незначительно изменились идеологически, но весьма существенно - технологически. Наибольшие идеологические изменения произошли в коммуникационном менеджере, так как в этой области появились новые объектно-ориентированные технологии (CORBA, DCOM и т.д.). Из-за бурного развития коммуникационных средств в будущем следует ожидать широкого использования различных типов менеджеров транзакций.
Таким образом, многоуровневая архитектура клиент-сервер позволяет существенно упростить распределенные вычисления, делая их не только более надежными, но и более доступными. Появление таких средств, как Java, упрощает связь сервера приложений с клиентами, а объектно-ориентированные менеджеры транзакций обеспечивают согласованную работу сервера приложений с базами данных. В результате создаются все предпосылки для создания сложных распределенных информационных систем, которые эффективно используют все преимущества современных технологий.
Одним из основных требований к распределенной базе данных остается требование наличия развитой методологии распределения и размещения данных, включая разбиение.
Фрагментация данных
База данных физически распределяется по узлам компьютерной информационной системы при помощи фрагментации и репликации (тиражирования) данных.
Отношения, принадлежащие реляционной базе данных, могут быть фрагментированы на горизонтальные или вертикальные разделы.
Горизонтальная фрагментация реализуется при помощи операции селекции, которая направляет каждый кортеж отношения в один из разделов, руководствуясь предикатом фрагментации. Например, для отношения Employee (Сотрудник) возможна фрагментация в соответствии с территориальным распределением рабочих мест сотрудников.
Тогда запрос "получить информацию о сотрудниках компании" может быть сформулирован так:
SELECT * FROM employee@donetsk,
employee@kiev
На рисунке 1 изображен принцип разделения данных при горизонтальной фрагментации.
На рисунке 2 приведен пример горизонтальной фрагментации.

Рис. 1 Горизонтальная фрагментация

Рис. 2 Пример горизонтальной фрагментации
При вертикальной фрагментации отношение делится на разделы при помощи операции проекции. Например, один раздел отношения Employee может содержать поля Номер_сотрудника (emp_id), ФИО_сотрудника (emp_name), Адрес_сотрудника (emp_adress), а другой – поля Номер_сотрудника (emp_id), Оклад (salary), Руководитель (emp_chief).
Тогда запрос "получить информацию о заработной плате сотрудников компании" будет выглядеть следующим образом:
SELECT employee.emp_id,
emp_name,
salary
FROM employee@donetsk,
employee@kiev
ORDER BY emp_id
На рисунках 3 и 4 изображены сущность и пример вертикальной фрагментации.

Рис. 3 Вертикальная фрагментация
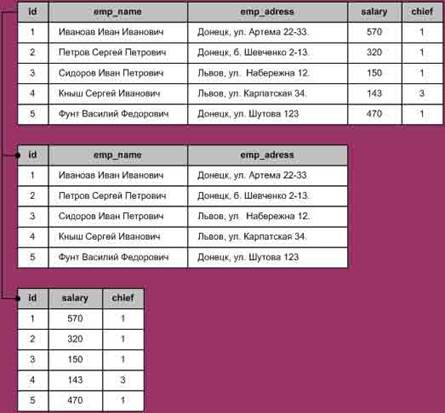
Рис. 5. Пример вертикальной фрагментации
За счет фрагментации данные приближаются к месту их наиболее интенсивного использования, что потенциально снижает затраты на пересылки; уменьшаются также размеры отношений, участвующих в пользовательских запросах. Однако практически добиться ускорения выполнения запросов, затрагивающих фрагментированные отношения, очень трудно. Основная проблема состоит в резком расширении пространства поиска вариантов выполнения запросов, с которым должен работать оптимизатор запросов.
Репликация данных
Второй способ распределения данных – репликация (рис.6). Репликация (или тиражирование) означает создание дубликатов данных. Репликаты – это множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых поддерживается синхронизация (идентичность) с некоторой "главной" копией.

Рис. 6. Репликация
Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослабляется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. На рисунках 7, 8, 9 показаны различные модели тиражирования.
При репликации фрагменты данных тиражируются с учетом спроса на доступ к ним. Это полезно, если доступ к одним и тем же данным нужен из приложений, выполняющихся на разных узлах. В таком случае, с точки зрения экономии затрат, более эффективно будет поддерживать копии данных на всех узлах, чем непрерывно пересылать данные между узлами.

Рис. 7. Одновременное обновление (с управлением параллелизмом)

Рис. 8 Распространенные обновления
Основной проблемой репликации данных является то, что обновление любого логического объекта должно распространяться на все хранимые копии этого объекта. Трудности возникают из-за того, что некоторый узел, содержащий данный объект, может быть недоступен (например, из-за краха системы или данного узла) именно в момент обновления. В таком случае очевидная стратегия немедленного распространения обновлений на все копии может оказаться неприемлемой, поскольку предполагается, что обновление (а значит и исполнение транзакции) будет провалено, если одна из копий будет недоступна в текущий момент.

Рис. 9. Запланированная синхронизация дубликатов только для чтения
В современных СУБД функции репликации выполняет, как правило, специальный модуль – сервер тиражирования данных, называемый репликатором (так устроены СУБД CA – OpenIngress и Sybase). В Informix-OnLine Dynamic Server репликатор встроен в сервер, вOracle для использования репликации необходимо приобрести дополнительную опцию Replication Option.
Спецификация механизмов репликации зависит от используемой СУБД. Простейший вариант – использование “моментальных снимков” (snapshot).
|
|
|
