 |


Описательная статистика показателей обеспеченности ТДП
|
|
|
|
| N | Minimum | Maximum | Mean | Std. Deviation | |
| indexTDP1 | 4711 | .00 | 11.84 | .6333 | 1.01381 |
| indexTDP2 | 4711 | .00 | 63.00 | 13.2815 | 11.65379 |
| indexTDP3 | 4711 | .00 | 10.00 | 4.0964 | 1.64273 |
Есть семьи, где рассчитанный показатель наличия ТДП равен нулю, это говорит о том, что у этих домохозяйств вовсе отсутствуют перечисленные товары, либо они довольно старые (либо они просто не аккуратно ответили на данный вопрос анкеты).
Гистограммы распределения показателей следующие:
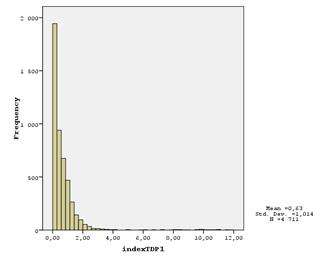
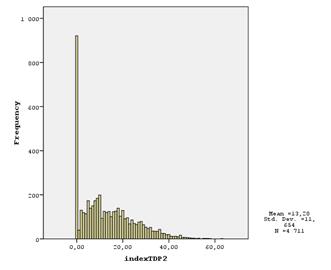
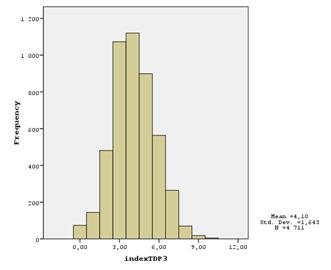
Как видно, для первого и второго показателей присутствует большая группа семей, для которых они равны 0 (или около того). Это происходит, скорее всего, потому, что вещи есть, но они достаточно старые (старше 9 лет), поэтому индексы их учитывают как будто бы их нет вовсе.
Наконец, для изучения зависимости между потреблением ТДП от дохода и других социально-экономических факторов строятся несколько регрессионных моделей.
Ниже отдельно для каждого из трех показателей приводится отдельная таблица, содержащая 3 или 4 модели. Первая модель всегда содержит только одну независимую переменную, вторая – две и так далее. Такое представление результатов позволяет показать, как добавление последующей объясняющей переменной отражается на качестве модели. Для добавления переменных в модель был использован алгоритм Stepwise программы SPSS. Значки Sig. показывают значимость модели в целом и коэффициентов по отдельности. Считается, что если Sig. близок к 0, то модель значима, то есть, имеет смысл.
Рассмотрим модели с первым показателем. Качество моделей (хотя они и значимы) очень низкое. Так как показатель R2 близок к 0. То есть, независимые переменные (доход, число источников дохода и проч.) плохо объясняют изменения переменной индекса владения ТДП. Максимум – на 7%. В первую очередь программа включила в модель число членов семьи, затем – двоичную переменную город/село, затем – суммарный доход и, наконец, число источников дохода. Интерпретация для 4-й модели, например, такая: каждый дополнительный член домохозяйства, при прочих равных условиях, увеличивает индекс потребления ТДП, в среднем, на 0,148 единиц. Иными словами, более крупные семьи, обычно, владеют большим набором ТДП. Что естественно. Аналогично, если домохозяйство из городской среды, то нужно увеличить прогноз индекса на 0,269. Каждый доп. рубль суммарного дохода домохозяйства увеличивает индекс на 0,00000514 единиц. А вот чем больше источников дохода, тем меньше как бы становится индекс. В части выводов причина этого обсуждается.
|
|
|
Регрессионные модели потребления ТДП (первый вариант)
| Модель № | 1 | 2 | 3 | 4 |
| Константа | 0,223 (Sig.=0,000) | 0,013 (Sig.=0,741) | 0,016 (Sig.=0,688) | 0,077 (Sig.=0,074) |
| Число членов семьи | 0,148 (Sig.=0,000) | 0,154 (Sig.=0,000) | 0,140 (Sig.=0,000) | 0,148 (Sig.=0,000) |
| Городская местность проживания | – | 0,279 (Sig.=0,000) | 0,254 (Sig.=0,000) | 0,269 (Sig.=0,000) |
| Суммарный доход домохозяйства за последние 30 дней | – | – | 5,10Е-006 (Sig.=0,000) | 5,14Е-006 (Sig.=0,000) |
| Число источников дохода за последнее время | – | – | – | –0,039 (Sig.=0,001) |
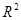
| 0,043 | 0,059 | 0,071 | 0,073 |
| Значимость модели (Sig.) | 0,00 0 | 0,00 0 | 0,00 0 | 0,00 0 |
Модель с использованием второго варианта индекса (без учета весов ТДП) кажется более удачной. Но и здесь объясняющая способность не превышает 16% для 4-х объясняющих переменных. Суть коэффициентов остается той же. Но они теперь чуть-чуть побольше, поскольку второй индекс имеет больший масштаб изменений.
Регрессионные модели потребления ТДП (второй вариант)
| Модель № | 1 | 2 | 3 | 4 |
| Константа | 5,969 (Sig.=0,000) | 2,623 (Sig.=0,000) | 2,662 (Sig.=0,000) | 3,574 (Sig.=0,000) |
| Число членов семьи | 2,629 (Sig.=0,000) | 2,725 (Sig.=0,000) | 2,533 (Sig.=0,000) | 2,639 (Sig.=0,000) |
| Городская местность проживания | – | 4,443 (Sig.=0,000) | 4,087 (Sig.=0,000) | 4,314 (Sig.=0,000) |
| Суммарный доход домохозяйства за последние 30 дней | – | – | 7,41Е-005 (Sig.=0,000) | 7,46Е-005 (Sig.=0,000) |
| Число источников дохода за последнее время | – | – | – | –0,572 (Sig.=0,000) |
|
| 0,103 | 0,133 | 0,153 | 0,156 |
| Значимость модели (Sig.) | 0,000 | 0,000 | 0,000 | 0,000 |
|
|
|
Третий вариант индекса наилучшим образом подходит для моделирования (см. табл. ниже). Но и здесь 3-я модель объясняет лишь 18,7% колеблемости индекса. Число источников дохода здесь включать было излишне и SPSS не включил.
Регрессионные модели потребления ТДП (третий вариант)
| Модель № | 1 | 2 | 3 |
| Константа | 2,966 (Sig.=0,000) | 2,412 (Sig.=0,000) | 2,418 (Sig.=0,000) |
| Число членов семьи | 0,407 (Sig.=0,000) | 0,422 (Sig.=0,000) | 0,394 (Sig.=0,000) |
| Городская местность проживания | – | 0,735 (Sig.=0,000) | 0,683 (Sig.=0,000) |
| Суммарный доход домохозяйства за последние 30 дней | – | – | 1,09Е-005 (Sig.=0,000) |
|
| 0,124 | 0,1166 | 0,187 |
| Значимость модели (Sig.) | 0,000 | 0,000 | 0,000 |
Итак, поставленная цель была достигнута. Регрессионные модели построены. Они не очень хорошо объясняют все три варианта индекса, видимо, потому, что все-таки наличи в домохозяйстве ТДП объясняется, в основном, не этими переменными, а теми, что я не учла в анализе.
В следующем разделе обсуждаются некоторые выводы, которые можно из всего этого сделать.
Выводы
В ходе работы был проведен анализ данных опроса RLMS волны 2004 года. Основной целью работы было исследование зависимости наличия у домохозяйств товаров длительного пользования от доходов и различных социально-экономических факторов (числа членов домохозяйства, числа источников доходов, местности проживания).
Для учета наличия в домохозяйстве товаров длительного пользования было построено 3 варианта индикатора. Первый вариант, наиболее сложный, учитывал наличие ТДП по 13 позициям, веса различных ТДП (например, компьютер имеет значительно меньший вес, чем автомобиль), а также – количество лет, сколько данный товар уже используется в домохозяйстве. Логика данного индикатора такова, что чем больше дорогих товаров длительного пользования имеется в домохозяйстве и чем эти товары «моложе» (т.е. куплены относительно недавно), тем больше величина индикатора. Второй вариант упрощает логику первого индикатора, исключая из него веса ТДП. Т.е. теперь, например, дополнительная квартира и стиральная машинка имеют один и тот же вес. Но срок давности этих вещей по-прежнему учитывался. Этим я как бы проверяю обоснованность назначения весов товарам длительного пользования. Третий вариант индикатора еще проще. Он является простым пересчетом различных ТДП, без учета их возраста и весов. Это самый простой вариант.
|
|
|
Зависимости всех этих 3 индикаторов последовательно изучались в 3 блоках регрессионных моделей. Сначала изучалось влияние независимый переменных на 1-й индикатор, затем – на 2-й, затем – на 3-й. При этом в каждом блоке строилась не одна, а несколько моделей, т.е. сначала включалась одна независимая переменна, затем к ней добавлялась вторая и т.д. Для этого был использован метод анализа Stepwise пакета SPSS. Этот метод сам решает, нужно ли включить переменную в анализ, или нет. В итоге в 1 и 2 блоках были включены все независимые переменные, а в 3 блоке – все за исключением числа источников дохода. С добавлением каждой из независимых переменных в модель, объясняющая способность модели возрастала, при этом построенная в итоге модель множественной линейной регрессии была значимой (значения Sig. в таблице ANOVA были малы).
К сожалению, ни в одном блоке не удалось добиться высокого показателя качества регрессионной модели R2. Он был далек от единицы во всех случаях. Хуже всего поддавался моделированию 1-й показатель (самый сложный). Включением в модель всех 4 независимых переменных удалось добиться «объяснения» показателя лишь на R2=0,073 (т.е. на 7%). Это, конечно, мало. Второй показатель показал себя лучше. Он объяснялся максимум на 15,6%, что, хотя, тоже немного. Третий показатель показал себя чуть лучше второго. Он объяснялся на 18,7%.
Таким образом, основной вывод, который мы можем сделать – это тот, что отчасти показатель наличия, давности приобретения и веса ТДП в домохозяйстве объясняются текущими показателями дохода, числа источников дохода, а также – числом членов семьи и местностью проживания, но, вообще, зависимость от всех этих переменных – довольно слабая. Во всяком случае, не превышает 20%.
|
|
|
Другой вывод, который можно сделать – это тот, что SPSS включал переменные в модель всегда в одном и том же порядке. Сначала число членов семьи, затем – город, затем – доход, затем – число источников дохода (кроме блока 3). Наверное, это логично, поскольку разнообразие товаров длительного пользования, конечно, во многом зависит от размера семьи. В большой семье сложно обойтись без основных вещей. Наличие ТДП, конечно, зависит и от местности проживания, поскольку городские жители все же пока лучше, чем сельские обеспечены самым необходимым. Кроме этого, сельские жители редко владеют, скажем, дачами, т.е. у них показатель ТДП часто оказывается заниженным. С другой стороны, городские жители, например, реже, чем сельские, владеют тракторами. То, что доход домохозяйства за последние 30 дней находился далеко не на 1-м месте, значит, наверное, то, что, хотя мы и пытались учесть срок давности приобретения ТДП, но все же это товары длительного пользования, а, значит, их наличие лишь в очень небольшой степени объясняется доходом за последний месяц.
Замечу, что для всех независимых переменных коэффициенты были положительными, за исключением числа источников дохода. Получается, что чем больше у домохозяйства источников дохода, чем меньше у него индекс ТДП. Конечно, эта переменная влияет на индекс слабее остальных, но все же может показаться странным, что большой спектр источников дохода оборачивается малым количеством (или большой давностью ТДП). Я думаю, этот «парадокс» объясняется довольно просто. При подсчете числа источников доходов мы учитывали и такие источники, как пенсия, субсидии, помощь от государственных и негосударственных организаций, помощь родственников и других людей (в том числе – не только деньгами, но и вещами). Получается, что большое число источников дохода – не показатель благополучия домохозяйства, а, скорее, наоборот - обозначение того, что семья вынуждена прибегать к помощи со стороны. Тогда как состоятельные семьи часто существуют, в основном, на зарплату и, может быть, проценты от акций и т.д. Я считаю это довольно интересным выводом.
Довольно тяжело объяснить, почему аккуратный учет располагаемых ТДП в домохозяйстве выражающийся индексом №1, оказался хуже, чем остальные индексы, которые не учитывают, ни вес ТДП, ни их возраст. Может быть, это от того, что c увеличением дохода потребление различных товаров длительного пользования изменяется в разной степени независимо от их цен. А может быть мы просто подобрали такие веса, которые не точно соответствуют соотношениям цен на товары. Может, сложность заключается еще в том, что у нас как бы смешались ТДП, которые есть почти в каждой семье (холодильник, телевизор) и товары, которые есть лишь у некоторых (автомобиль, компьютер, дополнительная квартира). Возможно, проблема состоит еще и в том, что, если учитывать возраст вещей и не учитывать вещи, которые старше 10 лет (как это было сделано в индексах №1 и 2), то около 20% домохозяйств имеют индекс ТДП, равный 0, т.е. вовсе не имеют вещей, которые нас интересуют. А для третьего индекса таких домохозяйств только 1%.
|
|
|
Итак, в результате проведенных исследований мы выяснили, что зависимость потребления ТДП от дохода и других социально-экономических факторов можно описать с помощью множественной линейной регрессии, но далеко не полностью.
Литература
1. Салин В.Н., Шпаковская Е.П. Социально-экономическая статистика: Учебник. – М.: Юристъ, 2001. – 461 с.
2. Социальная статистика: Учебник / Под ред. чл.-кор. РАН И.И. Елисеевой. – 3-е изд., перераб и доп. – М. Финансы и статистика, 2002. – 480 с.
3. Социальное положение и уровень жизни населения России: Стат. сб. / Госкомстат России. – М., 2001. – 463 с.
4. SPSS Base 14.0 Руководство пользователя. – SPSS Inc, 2005. – 814 с.
5. Российский статистический ежегодник. 2005: Стат. сб. / Росстат. – М., 2006. – 819 с.
6. Сигел, Эндрю. Практическая бизнес-статистика.: Пер. с англ. – М.: Издательский дом «Вильямс», 2002. – 1056 с.
7. Приложения
Командный синтаксис SPSS-15 для построения моделей. В приложении приводится перечень команд трансформации и статистического анализа в SPSS, выполнение которых позволяет при наличии исходных данных получить расчетные показатели, а также таблицы с результатами моделирования. Синтаксис позволяет при необходимости быстро воспроизвести ход процесса моделирования, а также допускает легкую модификацию для построения аналогичных моделей на других данных, имеющих схожую структуру (либо на этих же данных, но по подгруппам респондентов). Дополнительно о синтаксисе SPSS можно прочитать на сайте www.spsstools.ru, или в руководстве пользователя по синтаксису (см. выше).
Внимание! Перед запуском синтаксиса необходимо определить пропущенные значения по всем переменным, чтобы они исключались из анализа и не искажали результатов расчета.
Вычисление показателей.
Вычисление числа членов семьи (это присутствует либо в переменной i1.o, либо в i1.n).
COMPUTE nfam=SUM(i1.o,i1.n).
Вычисление двоичной переменной «город» (если код 1 или 2, то это – город).
COMPUTE gorod=status<3.
Вычисление числа источников дохода (если код в этих переменных равен 1, значит респондент согласился, что у него есть такой источник дохода).
COMPUTE ndohod=SUM(0, if3=1, if6.1=1, if6.2=1,
if9.1a=1,
if9.2a=1,
if9.3a=1,
if9.4a=1,
if9.5a=1,
if9.6a=1,
if9.7a=1,
if9.8a=1,
if9.9a=1,
if9.91a=1,
if9.10a=1,
if10=1,
if11.3=1,
if12.1a=1,
if12.2a=1,
if12.3a=1,
if12.4a=1,
if12.5a=1,
if12.6aa=1,
if12.6ba=1,
if12.7a=1,
if12.8a=1,
if12.9a=1,
if1210ba=1).
Вычисление первого варианта индекса (наличие предмета (код=1), т.е. 1 мы умножаем на вес и на максимум из 0 или 10-«возраст». Если возраст предмета больше или равен 10 годам, мы берем не отрицательное значение, а 0, т.е. не учитываем данный предмет).
COMPUTE indexTDP=SUM(0, (ic9.1a=1)*0.04*Max(0,10-ic9.1b),
(ic9.2a=1)*0.04*Max(0,10-ic9.2b),
(ic9.3a=1)*0.04*Max(0,10-ic9.3b),
(ic9.4a=1)*0.01*Max(0,10-ic9.4b),
(ic9.5a=1)*0.03*Max(0,10-ic9.5b),
(ic9.6a=1)*0.03*Max(0,10-ic9.6b),
(ic9.6.2a=1)*0.04*Max(0,10-ic9.6.2b),
(ic9.7a=1)*0.1*Max(0,10-ic9.7b),
(ic9.7.1a=1)*0.1*Max(0,10-ic9.7.1b),
(ic9.8a=1)*0.05*Max(0,10-ic9.8b),
(ic9.9a=1)*0.1*Max(0,10-ic9.9b),
(ic9.101a=1)*0.2*Max(0,10-ic9.101b),
(ic9.12a=1)*1*Max(0,10-ic9.12b)).
Вычисление второго варианта индекса ТДП. Тут мы не учитываем вес предмета.
COMPUTE indexTDP1=SUM(0, (ic9.1a=1)*Max(0,10-ic9.1b),
(ic9.2a=1)*Max(0,10-ic9.2b),
(ic9.3a=1)*Max(0,10-ic9.3b),
(ic9.4a=1)*Max(0,10-ic9.4b),
(ic9.5a=1)*Max(0,10-ic9.5b),
(ic9.6a=1)*Max(0,10-ic9.6b),
(ic9.6.2a=1)*Max(0,10-ic9.6.2b),
(ic9.7a=1)*Max(0,10-ic9.7b),
(ic9.7.1a=1)*Max(0,10-ic9.7.1b),
(ic9.8a=1)*Max(0,10-ic9.8b),
(ic9.9a=1)*Max(0,10-ic9.9b),
(ic9.101a=1)*Max(0,10-ic9.101b),
(ic9.12a=1)*Max(0,10-ic9.12b)).
Вычисление третьего варианта индекса ТДП. Здесь мы учитываем только наличие предметов.
COMPUTE indexTDP2=SUM(0, (ic9.1a=1),
(ic9.2a=1),
(ic9.3a=1),
(ic9.4a=1),
(ic9.5a=1),
(ic9.6a=1),
(ic9.6.2a=1),
(ic9.7a=1),
(ic9.7.1a=1),
(ic9.8a=1),
(ic9.9a=1),
(ic9.101a=1),
(ic9.12a=1)).
Описательная статистика рассчитанных и присутствующих в базе данных показателей, которые будут использованы для моделирования:
FREQUENCIES
VARIABLES=nfam gorod ndohod
/ORDER=ANALYSIS.
GRAPH
/HISTOGRAM=if14 indexTDP1 indexTDP2 indexTDP3.
EXAMINE
VARIABLES=ndohod nfam if14 indexTDP1 indexTDP2 indexTDP3
/PLOT BOXPLOT STEMLEAF
/COMPARE GROUP
/PERCENTILES(5,10,25,50,75,90,95) HAVERAGE
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.
Построение 3-х блоков регрессионных моделей, по одному на каждый вариант индекса.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT indexTDP1
/METHOD=STEPWISE nfam gorod ndohod if14.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT indexTDP2
/METHOD=STEPWISE nfam gorod ndohod if14.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT indexTDP3
/METHOD=STEPWISE nfam gorod ndohod if14.
|
|
|
12 |
