 |


Доверительные интервалы для зависимой переменной
|
|
|
|
Одной из центральных задач эконометрического моделирования является предсказание (прогнозирование) значений зависимой переменной при определенных значениях объясняющих переменных. Здесь возможен двоякий подход: либо предсказать условное математическое ожидание зависимой переменной при определенных значениях объясняющих переменных (предсказание среднего значения), либо прогнозировать некоторое конкретное значение зависимой переменной (предсказание конкретного значения).
Предсказание среднего значения. Пусть построено уравнение парной регрессии yteor(xi) = b0 + b1×xi, на основе которого необходимо предсказать условное математическое ожидание М(YïХ = хp) переменной yteor(xp) при X = хp. В данном случае значение yteor(xp) = b0 + b1×xp является оценкой (приближением) М(YïХ = хp). Тогда естественным является вопрос, как сильно может уклониться модельное среднее значение yteor(xp), рассчитанное по эмпирическому уравнению регрессии, от соответствующего истинного условного математического ожидания yteor,true(xp) = b0 + b1×xp. Ответ на этот вопрос дается на основе интервальных оценок, построенных с заданной надежностью (1-a) при любом конкретном значении хр объясняющей переменной.
Чтобы построить доверительный интервал, покажем, что случайная величина yteor(xp) имеет нормальное распределение с конкретными параметрами. Используя формулы (8.1), (8.2), имеем:
yteor(xp) = b0 + b1×xp = ådi yi +(å ci yi)×xp = å(di +ci×xp)yi.
Следовательно, yteor(xp) является линейной комбинацией нормальных случайных величин и, значит, сама имеет нормальное распределение.
Myteor(xp) = M(b0 + b1×xp) = M(b0)+ M(b1)×xp = b0 + b1×xp,
Dyteor(xp) = D(b0 + b1×xp) = D(b0)+ D(b1) +2×cov(b0,b1)×xp, (8.12)
(здесь используются формулы: D(X+Y) = D(Х)+D(У)+ 2×соv(Х, Y); D(сХ) = с2×D(Х); cov(Х, b×Y) = b×соv(Х, Y)).
|
|
|
cov(b0,b1) = M[(b0 – M(b0)×(b1 – M(b1))] =
= M[(b0 - b0)×(b1 – b1)] = M[(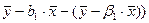 ×(b1 – M(b1))] =
×(b1 – M(b1))] =
= -  × M[(b1 - M(b1)×(b1 – M(b1))] = × M[(b1 - b1)×(b1 – b1)] =
× M[(b1 - M(b1)×(b1 – M(b1))] = × M[(b1 - b1)×(b1 – b1)] =
= - ×D(b1) = 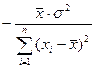 .
.
Следовательно,

= 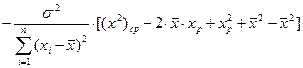 =
=
= 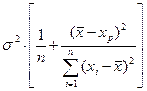 . (8.13)
. (8.13)
Так как
 ,
,
Поскольку
 Подставив вместо s2 её несмещенную оценку
Подставив вместо s2 её несмещенную оценку  получим выборочную исправленную дисперсию D(yteor(xp)) рассматриваемой случайной величины. Тогда случайная величина
получим выборочную исправленную дисперсию D(yteor(xp)) рассматриваемой случайной величины. Тогда случайная величина
 (8.14)
(8.14)
имеет распределение Стьюдента с числом степеней свободы n = n–2. Следовательно, по таблице критических точек распределения Стьюдента по требуемому уровню значимости a и числу степеней свободы n=n–2 можно определить критическую точку ta/2,n-2, удовлетворяющую условию Р(ïТï < ta/2,n-2) = 1–a.
С учетом (7.3) имеем:
 (8.15)
(8.15)
После алгебраических преобразований получим:

 =1-a. (8.16)
=1-a. (8.16)
Таким образом, доверительный интервал для гипотезы H0: M(YïX=xp) = b0 + b0*хр имеет вид:
 ;
;
 . (8.17)
. (8.17)
В верхней строке приведена нижняя граница доверительного интервала, в нижней строке – верхняя граница доверительного интервала, в котором с надёжностью 1–a находятся значения зависимого фактора, лежащие на линии регрессии
Для проверки гипотезы
H0: M(YïX=xp) = yp;
H1: M(YïX=xp) ¹ yp;
используется статистика:
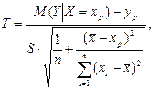 (8.18)
(8.18)
имеющая распределение Стьюдента с числом степеней свободы n = n -2. Поэтому H0 отклоняется, если |Tнабл | ³ ta/2,n-2 (a– требуемый уровень значимости).
 Рис. 8.1. Диаграмма нижних и верхних доверительных границ для индивидуальных значений и значений, лежащих на линии регрессии, а также самой линии регрессии
Рис. 8.1. Диаграмма нижних и верхних доверительных границ для индивидуальных значений и значений, лежащих на линии регрессии, а также самой линии регрессии
Поскольку фактические индивидуальные значения зависимой переменной Y варьируют около среднего регрессионного значения yteor(xp) = b0 + b1×xp, и так как они могут отклоняться от yteor(xp) = b0 + b1×xp на величину среднеквадратического отклонения s2, которая оценивается как корень квадратный из дисперсии , то нижние и верхние границы оцениваются соответственно следующим образом:
|
|
|
 ;
;
 .
.
|
|
|
