 |


Алгоритм Кнута - Морриса - Пратта (КМП)
|
|
|
|
Метод использует предобработку искомой строки, а именно: на ее основе создается так называемая префикс-функция. Суть этой функции в нахождении для каждой подстроки S[1..i] строки S наибольшей подстроки S[1..j] (j<i), присутствующей одновременно и в начале, и в конце подстроки (как префикс и как суффикс). Например, для подстроки abcHelloabc такой подстрокой является abc (одновременно и префиксом, и суффиксом). Смысл префикс-функции в том, что можно отбросить заведомо неверные варианты, т.е. если при поиске совпала подстрока abcHelloabc (следующий символ не совпал), то имеет смысл продолжать проверку продолжить поиск уже с четвертого символа (первые три и так совпадут). Вначале рассматриваются некоторые вспомогательные утверждения. Для произвольного слова X рассматриваются все его начала, одновременно являющиеся его концами, и выбираются из них самое длинное (не считая, конечно, самого слова X). Оно обозначается n(X). Такая функция носит название префикс – функции [13].
Примеры.
n(aba)=a, n(n(aba))=n(a)=L;
n(abab)=ab, n(n(abab))=n(ab)=L;
n(ababa)=aba, n(n(ababa))=n(aba)=a, n(n(n(ababa)))=n(a)=L; n(abc)=L.
Справедливо следующее предложение:
(1) Последовательность слов n(X),n(n(X)),n(n(n(X))),... "обрывается" (на пустом слове L).
(2) Все слова n(X),n(n(X)),n(n(n(X))),...,L являются началами слова X.
(3) Любое слово, одновременно являющееся началом и концом слова X (кроме самого X), входит в последовательность n(X),n(n(X)),....,L.
Метод КМП использует предобработку искомой строки, а именно: на ее основе создается префикс-функция. При этом используется следующая идея: если префикс (он же суффикс) строки длинной i длиннее одного символа, то он одновременно и префикс подстроки длинной i-1. Таким образом, проверяется префикс предыдущей подстроки, если же тот не подходит, то префикс ее префикса, и т.д. Действуя так, находится наибольший искомый префикс. (см. приложение 3).
|
|
|
Следующий вопрос, на который стоит ответить: почему время работы процедуры линейно, ведь в ней присутствует вложенный цикл? Ну, во-первых, присвоение префикс-функции происходит четко m раз, остальное время меняется переменная k. Так как в цикле while она уменьшается (P[k]<k), но не становится меньше 0, то уменьшаться она может не чаще, чем возрастать. Переменная k возрастает на 1 не более m раз. Значит, переменная k меняется всего не более 2m раз. Выходит, что время работы всей процедуры есть O(m).
Алгоритм последовательного поиска и алгоритм КМП помимо нахождения самих строк считают, сколько символов совпало в процессе работы. Реализация этого алгоритма представлена в приложении 4.
Алгоритм Бойера – Мура
Алгоритм Бойера-Мура, разработанный двумя учеными – Бойером и Муром, считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке.
Простейший вариант алгоритма Бойера-Мура состоит из следующих шагов. На первом шаге строится таблица смещений для искомого образца. Процесс построения таблицы будет описан ниже. Далее совмещается начало строки и образца и начинается проверка с последнего символа образца. Если последний символ образца и соответствующий ему при наложении символ строки не совпадают, образец сдвигается относительно строки на величину, полученную из таблицы смещений, и снова проводится сравнение, начиная с последнего символа образца. Если же символы совпадают, производится сравнение предпоследнего символа образца и т. д. Если все символы образца совпали с наложенными символами строки, значит нашлась подстрока и поиск окончен. Если же какой-то (не последний) символ образца не совпадает с соответствующим символом строки, сдвигается образец на один символ вправо и снова начинается проверку с последнего символа. Весь алгоритм выполняется до тех пор, пока либо не будет найдено вхождение искомого образца, либо не будет достигнут конец строки.
|
|
|
Величина сдвига в случае несовпадения последнего символа вычисляется исходя из следующих соображений: сдвиг образца должен быть минимальным, таким, чтобы не пропустить вхождение образца в строке. Если данный символ строки встречается в образце, смещается образец таким образом, чтобы символ строки совпал с самым правым вхождением этого символа в образце. Если же образец вообще не содержит этого символа, сдвигается образец на величину, равную его длине, так что первый символ образца накладывается на следующий за проверявшимся символ строки.
Величина смещения для каждого символа образца зависит только от порядка символов в образце, поэтому смещения удобно вычислить заранее и хранить в виде одномерного массива, где каждому символу алфавита соответствует смещение относительно последнего символа образца.
Пример. Пусть есть алфавит из пяти символов: a, b, c, d, e и надо найти вхождение образца “abbad” в строке “abeccacbadbabbad”. Следующие схемы иллюстрируют все этапы выполнения алгоритма. Таблица смещений будет выглядеть так.
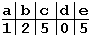
Начало поиска.
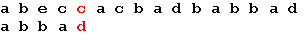
Последний символ образца не совпадает с наложенным символом строки. Сдвигается образец вправо на 5 позиций:
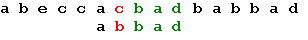
Три символа образца совпали, а четвертый – нет. Сдвигается образец вправо на одну позицию:
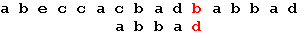
Последний символ снова не совпадает с символом строки. В соответствии с таблицей смещений сдвигается образец на 2 позиции:
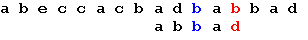
Еще раз сдвигается образец на 2 позиции:

Теперь, в соответствии с таблицей, сдвигается образец на одну позицию, и получается искомое вхождение образца:
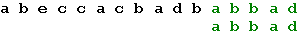
Прежде всего следует определить тип данных «таблица смещений». Для кодовой таблицы, состоящей из 256 символов, определение этого типа будет выглядеть так:
Type
TBMTable = Array [0..255] of Integer;
Реализация процедуры, вычисляющая таблицу смещений для образца p, представлена в приложении 5.
Теперь пишется функция, осуществляющая поиск (см. Приложение 6).
Параметр StartPos позволяет указать позицию в строке s, с которой следует начинать поиск. Это может быть полезно в том случае, если надо найти все вхождения p в s. Для поиска с самого начала строки следует задать StartPos равным 1. Если результат поиска не равен нулю, то для того, чтобы найти следующее вхождение p в s, нужно задать StartPos равным значению «предыдущий результат плюс длина образца».
|
|
|
|
|
|
