 |


Лексический анализатор целочисленных констант языка С
|
|
|
|
Содержание
Введение. 4
ЛАБОРАТОРНАЯ РАБОТА № 1 5
ПОСТРОЕНИЕ ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА.. 5
1. Цель работы.. 5
2. Краткие теоретические сведения. 5
3. Примеры.. 6
3.1. Лексический анализатор целочисленных констант языка С.. 6
3.2. Лексический анализатор для поиска строк в исходном тексте программы 12
4. Содержание работы.. 16
5. Контрольные вопросы.. 16
Лабораторная работа № 2 18
Генерация и оптимизация кода.. 18
1. Цель работы.. 18
2. Краткие теоретические сведения. 18
3. Примеры.. 18
3.1. Схемы СУ – перевода. 18
3.2. Схема СУ–перевода дерева операций на язык ассемблера. 19
3.3. Схема СУ - перевода дерева операций в последовательность триад. 22
3.4. Методы оптимизации кода. 24
3.5. Свертка объектного кода. 25
3.6. Исключение лишних операций. 27
4. Содержание работы.. 29
5. Контрольные вопросы.. 30
Список литературы.. 31
Введение
Реальное применение языка программирования невозможно без соответствующей системы программирования, основу которой составляет транслятор.
Транслятор – это программа, которая переводит программу на исходном (входном) языке в эквивалентную ей программу на результирующем (выходном) языке.
Компилятор – это транслятор, который осуществляет перевод исходной программы в эквивалентную ей результирующую программу на языке машинных команд или языке ассемблера.
Освоение методов программирования трансляторов дает студентам возможность применять полученные знания, как при решении конкретных практических задач, так и при разработке и реализации входных языков прикладных систем.
ЛАБОРАТОРНАЯ РАБОТА № 1
ПОСТРОЕНИЕ ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА
Цель работы
Целью лабораторной работы является закрепление теоретических знаний и приобретение практических навыков при построении лексических анализаторов.
|
|
|
Краткие теоретические сведения
Лексический анализатор (сканер) - разбивает программу на простые элементы-слова, называемые лексемами. Лексемами являются имена, служебные слова, числа, разделители, знаки операций. Удаляет из программы комментарии. Компилятор может иметь в своем составе несколько лексических анализаторов, каждый из которых предназначен для выборки и проверки определенного типа лексем. Обобщенный алгоритм работы простейшего лексического анализатора можно описать следующим образом:
· из входного потока выбирается очередной символ, в зависимости от которого запускается тот или иной сканер (символ может быть также проигнорирован либо признан ошибочным);
· запущенный сканер просматривает входной поток символов программы на исходном языке, выделяя символы, входящие в требуемую лексему, до обнаружения очередного символа, который может ограничивать лексему, либо до обнаружения ошибочного символа;
· при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем и таблицу идентификаторов, алгоритм возвращается к первому этапу и продолжает рассматривать входной поток символов с того места, на котором остановился сканер;
· при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят о реализации сканера – либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма).
Техника построения сканеров основывается на моделировании работы детерминированных и недетерминированных КА с дополнением функций распознавателя вызовами функций обработки ошибок, а также заполнения таблиц лексем и таблиц идентификаторов. Такая техника не требует сложной математической обработки и важных преобразований входных грамматик. Для разработчиков сканера важно только решить, где кончаются функции сканера и начинаются функции синтаксического разбора.
|
|
|
Примеры
Лексический анализатор целочисленных констант языка С
Рассмотрим пример анализа лексем, представляющих собой целочисленные константы в формате языка С. Такие константы могут быть десятеричными, восьмеричными или шестнадцатеричными. Восьмеричной константой считается число, начинающиеся с 0 и содержащее цифры от 0 до 7; шестнадцатеричная константа должна начинаться с последовательности символов 0x и может содержать цифры и буквы от a до f. Остальные числа считаются десятеричными. Константа может начинаться также с одного из знаков, + или -, а в конце цифры, обозначающей значение константы, в языке С может следовать буква, явно обозначающая ее тип (u, U – unsigned; h, H – short, L – long).
При построении сканера будем учитывать, что константы входят в общий текст программы на языке С. Рассмотренные выше правила могут быть записаны в грамматике целочисленных констант для языка С.
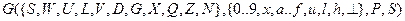
P:
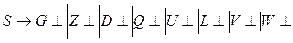




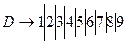
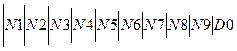

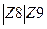

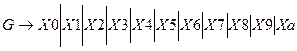







Данная грамматика является леволинейной автоматной регулярной грамматикой. По ней можно построить КА, который будет распознавать цепочки входного языка (рис. 1.). Начальным состоянием автомата будет состояние H.

Рис. 1. Граф конечного автомата для распознавания целочисленных
констант
Дополним грамматику еще одним состоянием E (ошибка). Переход в данное состояние будет осуществляться по любому символу, кроме тех символов, которыми были помечены дуги, выходящие из рассматриваемой вершины графа.
При построении КА знаком  были обозначены любые символы, которыми может завершаться целочисленная константа языка С. В реальной программе этот символ не встречается, поскольку границы лексем в ней явно не указаны. В языке С в качестве границы константы могут выступать:
были обозначены любые символы, которыми может завершаться целочисленная константа языка С. В реальной программе этот символ не встречается, поскольку границы лексем в ней явно не указаны. В языке С в качестве границы константы могут выступать:
· знаки пробелов, табуляции, конца строки;
· разделители), (, [, ], {, },,,:,;;
· знаки операций +, -, *, /, &, |,?, ~, <, >, ^, =, %.
Ниже приводится текст функции на языке Pascal, реализующий данный распознаватель. Результатом функции является текущее положение считывающей головки анализатора в потоке входной информации после завершения разбора лексемы при успешном распознавании либо 0 при неуспешном распознавании.
|
|
|
Переменная iState отображает текущее состояние автомата, переменная i является счетчиком символов входной строки.
function RunAuto (const sInput: string; iPos: integer):integer;
{ sInput – входная строка исходного текста;
sPos – текущее положение считывающей головки во входной строке исходного текста}
type
TAutoState = (AUTO_H, AUTO_S, AUTO_W, AUTO_U, AUTO_L, AUTO_V, AUTO_D, AUTO_G, AUTO_X, AUTO_Q, AUTO_Z, AUTO_N, AUTO_E);
const
AutoStop =[ ‘ ‘, #10, #13, #7, ‘(‘, ‘)’, ‘[‘, ‘]’, ‘{‘, ‘}’, ‘,’, ‘:, ‘;’, ‘+’, ‘-‘, ‘*’, ‘/’, ‘&’, ‘|’, ‘?’, ‘-‘, ‘<’, ‘>’, ‘^’, ‘=’, ‘%’];
var
iState: TAutoState;
i, iL: integer;
sOut: string;
begin
i:= iPos;
iL:=Length(SInput);
sOut:=’ ‘;
iState:= AUTO_H;
repeat
case iState of
AUTO_H:
case sInput[i] of
‘+’,’-‘: iState:= AUTO_N;
‘0’: iState:= AUTO_Z;
‘1’..’9’: iState:= AUTO_D;
else iState:= AUTO_E;
end;
AUTO_N:
case sInput[i] of
‘0’: iState:= AUTO_Z;
‘1’..’9’: iState:= AUTO_D;
else iState:= AUTO_E;
end;
AUTO_Z:
case sInput[i] of
‘x’: iState:= AUTO_X;
‘0’..’7’: iState:= AUTO_Q;
‘8’,’9’: iState:= AUTO_D;
else
if sInput[i]in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_X:
case sInput[i] of
‘0’..’9’,
‘a’..’f’: iState:= AUTO_G;
else iState:= AUTO_E;
end;
AUTO_Q:
case sInput[i] of
‘0’..’7’: iState:= AUTO_Q;
‘8’,’9’: iState:= AUTO_D;
‘u’: iState:= AUTO_U;
‘l’: iState:= AUTO_L;
‘h’: iState:= AUTO_V;
else
if sInput[i]in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_D:
case sInput[i] of
‘0’..’9’: iState:= AUTO_D;
‘u’: iState:= AUTO_U;
‘l’: iState:= AUTO_L;
‘h’: iState:= AUTO_V;
else
if sInput[i] in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_G:
case sInput[i] of
‘0’..’9’,
‘a’..’f’: iState:= AUTO_G;
‘u’: iState:= AUTO_U;
‘l’: iState:= AUTO_L;
‘h’: iState:= AUTO_V;
else
if sInput[i] in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_U:
case sInput[i] of
‘l’,’h’: iState:= AUTO_W;
else
if sInput[i] in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_L:
case sInput[i] of
‘u’: iState:= AUTO_W;
else
if sInput[i] in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_V:
case sInput[i] of
‘u’: iState:= AUTO_W;
else
if sInput[i] in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end;
AUTO_W:
if sInput[i] in AutoStop then
iState:= AUTO_S
else iState:= AUTO_E;
end {case};
if not (iState in [AUTO_E, AUNO_S]) then
begin
SOut:=sOut+sInput[i];
i:=i+1;
end;
until ((iState = AUTO_E) or (iState = AUTO_S) or (i>iL);
if (iState = AUTO_S) or (i>iL) then
begin
{Вызов функции записи лексем sOut}
RunAuto:=i;
end
else
begin
{Вызов функции формирования сообщения об ошибке}
RunAuto:=0;
end;
end; {RunAuto}
Лексический анализатор сначала считывает в память весь текст исходной программы, а потом начинает его последовательный просмотр. В зависимости от текущего символа вызывается тот или иной сканер. По результатам работы сканера разбор либо продолжается с позиции, которую вернула функция сканера, либо прерывается, если функция возвращает 0.
|
|
|
|
|
|
