 |


Программные системы управления базами данных
|
|
|
|
Модели организации данных
Набор принципов, определяющих организацию логической структуры хранения данных в базе, получил название модели данных. Модели баз данных определяются тремя компонентами:
- допустимой организацией данных;
- ограничениями целостности;
- множеством допустимых операций.
В теории систем управления базами данных выделяют модели трех основных типов: иерархическую, сетевую и реляционную.
Терминологической основой для иерархической и сетевой моделей являются понятия: атрибут, агрегат и запись. Под атрибутом (элементом данных) понимается наименьшая поименованная структурная единица данных. Поименованное множество атрибутов может образовывать агрегат данных. В некоторых случаях отдельно взятый агрегат может состоять из множества экземпляров однотипных данных, или, как еще говорят, являться множественным элементом. Наконец, записью называют составной агрегат, который не входит в состав других агрегатов. В иерархической модели все записи, агрегаты и атрибуты базы данных образуют иерархически организованный набор, то есть такую структуру, в которой все элементы связаны отношениями подчиненности, и при этом любой элемент может подчиняться только одному какому-нибудь другому элементу. Такую форму зависимости удобно изображать с помощью древовидного графа (схемы, состоящей из точек и стрелок, которая связна и не имеет циклов). Пример иерархической структуры базы данных приведен на рис. 1.
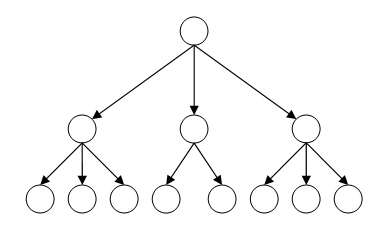
Рис. 1. Схема иерархической модели данных
Типичным представителем семейства баз данных, основанных на иерархической модели, является Information Management System (IMS) фирмы IBM, первая версия которой появилась в 1968 г. Концепция сетевой модели данных связана с именем Ч. Бахмана. Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков (рис. 2).
|
|
|

Рис. 2. Схема сетевой модели данных
Сетевая БД состоит из набора записей и набора связей между этими записями, точнее, из набора экземпляров записей заданных типов (из допустимого набора типов) и набора экземпляров из заданного набора типов связи. Примером системы управления данными с сетевой организацией является Integrated Database Management System (IDMS) компании Cullinet Software Inc., разработанная в середине 70-х годов. Она предназначена для использования на "больших" вычислительных машинах. Архитектура системы основана на предложениях Data Base Task Group (DBTG), Conference on Data Systems Languages (CODASYL), организации, ответственной за определение стандартов языка программирования Кобол. Среди достоинств систем управления данными, основанных на иерархической или сетевой моделях, могут быть названы их компактность и, как правило, высокое быстродействие, а среди недостатков - неуниверсальность, высокая степень зависимости от конкретных данных.
Реляционная модель данных
Концепции реляционной модели впервые были сформулированы в работах американского ученого Э. Ф. Кодда. Откуда происходит ее второе название - модель Кодда.
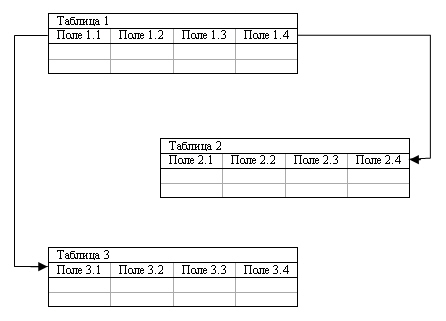
Рис. 3. Схема реляционной модели данных
В реляционной модели объекты и взаимосвязи между ними представляются с помощью таблиц (рис. 7.3). Для ее формального определения используется фундаментальное понятие отношения. Собственно говоря, термин "реляционная" происходит от английского relation - отношение. Если заданы произвольные конечные множества D1, D2,…, Dn, то декартовым произведением этих множеств D1? D2? …? Dn называют множество всевозможные наборов вида (d1, d2..., dn), где
d1 D1, d2 D2,..., dn Dn. Отношением R определенным на множествах D1, D2,…, Dn,, называется подмножество декартова произведения Dl x D2x... х Dn. При этом множества D1? D2? …? Dn называются доменами отношения, а элементы декартова произведения - кортежами отношения. Число я определяет степень отношения, а количество кортежей - его мощность. Наряду с понятиями домена и кортежа при работе с реляционными таблицами используются альтернативные им понятия поля и записи.
В реляционной базе данных каждая таблица должна иметь первичный ключ (ключевой элемент) - поле или комбинацию полей, которые единственным образом идентифицируют каждую строку в таблице. Важным преимуществом реляционной модели является то, что в ее рамках действия над данными могут быть сведены к операциям реляционной алгебры, которые выполняются над отношениями. Это такие операции, как объединение, пересечение, вычитание, декартово произведение, выборка, проекция, соединение, деление.
Важнейшей проблемой, решаемой при проектировании баз данных, является создание такой их структуры, которая бы обеспечивала минимальное дублирование информации и упрощала Процедуры обработки и обновления данных. Код-дом был предложен некоторый набор формальных требований универсального характера к организации данных, которые позволяют эффективно решать перечисленные задачи. Эти требования к состоянию таблиц данных получили название нормальных форм. Первоначально были сформулированы три нормальные формы. В дальнейшем появилась нормальная форма Бойса-Кодда и нормальные формы более высоких порядков. Однако они не получили широкого распространения на практике. - Говорят, что отношение находится в первой нормальной форме, если все его атрибуты являются простыми.
|
|
|
- Говорят, что отношение находится во второй нормальной форме, если оно удовлетворяет требованиям первой нормальной формы и каждый не ключевой атрибут функционально полно зависит от ключа (однозначно определяется им).
- Говорят, что отношение находится в третьей нормальной форме, если оно удовлетворяет требованиям второй нормальной формы и при этом любой не ключевой атрибут зависит от ключа нетранзитивно. Заметим, что транзитивной называется такая зависимость, при которой какой-либо не ключевой атрибут зависит от другого не ключевого атрибута, а тот, в свою очередь, уже зависит от ключа.
Принципиальным моментом является то, что для приведения таблиц к состоянию, удовлетворяющему требованиям нормальных форм, или, как еще говорят, для нормализации данных над ними, должны быть осуществлены перечисленные выше операции реляционной алгебры. Основным достоинством реляционной модели является ее простота. Именно благодаря ей она положена в основу подавляющего большинства реально работающих СУБД.
|
|
|
Язык SQL
В разработанной Коддом реляционной модели были определены как требования к организации таблиц, содержащих данные, так и язык, позволяющий работать с ними. Впоследствии этот язык получил название SQL (Structured Query Language - структурированный язык запросов). SQL был впервые реализован фирмой I в начале 70-х годов двадцатого века под названием Structures English Query Language (SEQUEL). Он был ориентирован на управление прототипом реляционной базы данных IBM-System R. В дальнейшем SQL стал стандартом de facto языка работы с реляционными базами данных. Этот его статус был впервые зафиксирован в 1986 году Американским национальным институтом стандартов (ANSI). Другими достаточно известными стандартами SQL стали стандарты ANSI SQL-92 ISO SQL-92, X/Open. В составе SQL могут быть выделены следующие группы инструкций:
- язык описания данных - DDL (Data Definition Language);
- язык манипулирования данными - DML (Data Manipulation Language);
- язык управления транзакциями.
Инструкции DDL предназначены для создания, изменения и удаления объектов базы данных. Их описание приведено в табл. 1.
Таблица 1. Инструкции языка определения данных (DDL)
| Инструкция | Назначение |
| CREATE | Создание новых объектов (таблиц, полей, индексов и т. д.) |
| DROP | Удаление объектов |
| ALTER | Изменение объектов |
Например, нам необходимо создать таблицу, содержащую данные по каталогу фирм, каждая фирма в котором характеризуется кодом, наименованием, MCCTOJV расположения штаб-квартиры, размером уставного фонда. Данной операции со ответствует SQL-выражение
|
|
|
CREATE TABLE Фирмы
(КодФирмы TEXT (5),
НазвФирмы TEXT (30),
АдресФирмы TEXT (40),
УстФонд DOUBLE);
Отметим, что допустимые имена полей создаваемой таблицы и типы содержащихся в них данных могут варьироваться для различных версий и диалектов SQL Если нам понадобится изменить структуру таблицы Фирмы - допустим, добавит! к ней еще одну колонку с фамилией директора, то сделать это можно с помощью SQL-инструкции:
ALTER TABLE Фирмы ADD COLUMN Директор TEXT.(30);
а выражение, дающее Команду на уничтожение таблицы, будет выглядеть так:
DROP TABLE Фирмы;
Инструкции DML (табл. 2) позволяют выбирать данные из таблиц, а также добавлять, удалять и изменять их.
Таблица 2. Инструкции языка манипулирования данными (DML)
| Инструкция | Назначение |
| SELECT | Выполнение запроса к базе данных с целью отбора записей, удовлетворяющих заданным критериям |
| INSERT | Добавление записей в таблицы базы данных |
| UPDATE | Изменение значений отдельных записей и полей |
| DELETE | Удаление записей из базы данных |
SELECT - команда на выборку записей из базы данных - является наиболее часто используемой SQL-инструкцией. Сфера данных, которыми она манипулирует, определяется с помощью специальных предложений. Перечень основных предложений языка SQL приведен в табл. 3.
Таблица 3. Основные предложения языка SQL
| Инструкция | Назначение |
| FROM | Указывает имя таблицы, из которой должны быть отобраны данные |
| WHERE | Специфицирует условия, которым должны удовлетворять выбираемые данные |
| GROUP BY | Определяет, что выбираемые записи должны быть сгруппированы |
| HAVING | Задает условие, которому должна удовлетворять каждая группа отобранных записей |
| ORDER BY | Специфицирует порядок сортировки записей |
Примером простейшего применения инструкции SELECT может служить команда на выборку всех данных из таблицы Фирмы:
SELECT * FROM Фирмы;
Однако, вообще говоря, данная инструкция представляет собой весьма мощный инструмент манипуляции с содержимым баз данных. Так, выражение
SELECT Int([УстФонд]/500)*500 AS Диапазон,
Count(КодФирмы) AS ЧислоФирм
FROM Фирмы
GROUP BY Int([УстФонд]/500)*500;
задает команду на вывод данных о распределении значений уставных фондов фирм по интервалам длиной 500 денежных единиц (д. е.), то есть сколько фирм имеют уставный фонд менее 500 д. е., от 500 до 1000 д. е. и т. д. Третьей составной частью SQL является язык управления транзакциями. Транзакция - это логически завершенная единица работы, содержащая одну или более элементарных операций обработки данных. Все действия, составляющие транзакцию, должны либо выполниться полностью, либо полностью не выполниться. Инструкции языка управления транзакциями приведены в табл. 4.
|
|
|
Таблица 4. Инструкции языка управления транзакциями
| Инструкция | Назначение |
| COMMIT | Фиксация в базе данных всех изменений, сделанных текущей транзакцией |
| SAVEPOINT | Установка точки сохранения (начала транзакции) |
| ROLLBACK | Откат изменений, сделанных с момента начала транзакции |
В большинстве СУБД элементарные команды, составляющие тело транзакции, выполняются над некоторой буферной копией данных, и только если их удается успешно довести до конца, происходит окончательное обновление основной базы. Транзакция начинается от точки сохранения, задаваемой инструкцией SAVEPOINT, и может быть завершена по команде COMMIT или прервана по команде ROLLBACK (откат). Также в современных системах управления данными предусмотрены средства автоматического отката транзакций при возникновении системных сбоев. Таким образом, механизм управления транзакциями является важнейшим инструментом поддержания целостности данных.
Программные системы управления базами данных
Кратко остановимся на конкретных программных продуктах, относящихся к классу СУБД. На самом общем уровне все СУБД можно разделить:
- на профессиональные, или промышленные;
- персональные (настольные). Профессиональные (промышленные) СУБД представляют собой программную основу для разработки автоматизированных систем управления крупными экономическими объектами. На их базе создаются комплексы управления и обработки информации крупных предприятий, банков или даже целых отраслей. Первостепенными условиями, которым должны удовлетворять профессиональные СУБД, являются:
- возможность организации совместной параллельной работы большого количества пользователей;
- масштабируемость, то есть возможность роста системы пропорционально расширению управляемого объекта;
- переносимость на различные аппаратные и программные платформы;
- устойчивость по отношению к сбоям различного рода, в том числе наличие многоуровневой системы резервирования хранимой информации;
- обеспечение безопасности хранимых данных и развитой структурированной системы доступа к ним.
Промышленные СУБД к настоящему моменту имеют уже достаточно богатую историю развития. В частности, можно отметить, что в конце 70-х - начале 80-х годов в автоматизированных системах, построенных на базе больших вычислительных машин, активно использовалась СУБД Adabas. В настоящее время характерными представителями профессиональных СУБД являются такие программные продукты, как Oracle, DB2, Sybase, Informix, Ingres, Progress. Основоположниками СУБД Oracle стала группа американских разработчиков (Ларри Эллисбн, Роберт Майнер и Эдвард Оутс), которые более двадцати лет тому назад создали фирму Relational Software Inc. и поставили перед собой задачу создать систему, на практике реализующую идеи, изложенные в работах Э. Ф. Кодда И К. Дж. Дейта. Результатом их деятельности стала реализация переносимой реляционной системы управления базами данных с базовым языком обработки SQL. В 1979 г. заказчикам была представлена версия Oracle для мини-компьютеров PDP-11 фирмы Digital Equipment Corporation сразу для нескольких операционных систем: RSX- 11, IAS, RSTS и UNIX. Чуть позже Oracle был перенесен на компьютеры VAX под управлением VAX VMS. Значительная часть кода была написана на ассемблере, и поэтому процесс переноса системы на новую платформу требовал значительных усилий. Основным отличием Oracle очередной, третьей версии было то, что она была полностью написана на языке С. Такое решение обеспечивало переносимость системы на многие новые платформы, в частности, на различные клоны UNIX. Второй важной особенностью новой (1983 г.) версии была поддержка концепции транзакции. Примерно в это же время фирма получила новое имя - Oracle Corporation - и заняла лидирующее место на рынке производителей СУБД. Четвертая версия Oracle характеризовалась расширением перечня поддерживаемых платформ и операционных систем. Oracle был перенесен как на большие ЭВМ фирмы IBM (мэйнфреймы), так и на персональные компьютеры, работающие под управлением MS DOS. Именно в четвертой версии был сделан важный шаг в развитии технологии поддержки целостности баз данных. Для многопользовательских систем было предложено оригинальное решение Oracle поддержки "непротиворечивости чтения". В пятой версии была впервые реализована СУБД с архитектурой "клиент- сервер". Последующие версии СУБД Oracle были ориентированы на построение крупномасштабных систем обработки транзакций, изменение методов реализации систем ввода/вывода, буферизации, подсистем управления параллельным доступом, резервирования и восстановления. Также была реализована поддержка симметричных мультипроцессорных архитектур.
Проект и экспериментальный вариант СУБД Ingres были разработаны в университете Беркли под руководством одного из наиболее известных в мире ученых и специалистов в области баз данных Майкла Стоунбрейкера. С самого начала СУБД Ingres разрабатывалась как мобильная система, функционирующая в среде ОС UNIX. Первая версия Ingres была рассчитана на 16-разрядные компьютеры и работала главным образом на машинах серии PDP. Это была первая СУБД, распространяемая бесплатно для использования в университетах. Впоследствии группа Стоунбрейкера перенесла Ingres в среду ОС UNIX BSD, которая также была разработана в университете Беркли. Семейство СУБД Ingres из университета Беркли принято называть университетской Ingres. В начале 80-х была образована компания RTI (Relational Technology Inc.), которая разработала и стала продвигать коммерческую версию СУБД Ingres. В настоящее время коммерческая Ingres поддерживается, развивается и продается компанией Computer Associates. Сейчас это одна из наиболее развитых коммерческих реляционных СУБД. В то же время, по поводу университетской Ingres имеется много высококачественных публикаций. Более того, университетскую Ingres можно опробовать на практике и даже посмотреть ее исходные тексты.
Перечисленные выше (для СУБД Oracle) тенденции носят универсальный характер и определяют пути развития других программных продуктов, что вполне объясняется жесткой конкурентной ситуацией, сложившейся на данном рынке.
Персональные системы управления данными - это программное обеспечение, ориентированное на решение задач локального пользователя или компактной группы пользователей и предназначенное для использования на микроЭВМ (персональном компьютере). Это объясняет и их второе название - настольные. Определяющими характеристиками настольных систем являются:
- относительная простота эксплуатации, позволяющая создавать на их основе работоспособные приложения как "продвинутым" пользователям, так и тем, чья квалификация невысока;
- относительно ограниченные требования к аппаратным ресурсам.
Исторически первой среди персональных СУБД, получивших массовое распространение, стала Dbase фирмы Ashton-Tate (впоследствии права на нее перешли к фирме Borland, а с 1999 г. данная программа поддерживается фирмой dBASE Inc.). В дальнейшем серия реляционных персональных СУБД пополнилась такими продуктами, как FoxBase/FoxPRO (Fox Software, в дальнейшем - Microsoft), Clipper (Nantucket, затем - Computer Associates), R:base (Microrim), Paradox (Borland, на настоящий момент правами владеет фирма Corel), Access (Microsoft), Approach (Lotus). Завоевавшие широкую популярность в России системы Dbase, FoxPRO и Clipper работали с таблицами данных, размещавшихся в файлах, имевших расширение *.dbf (термин dbf-формат стал общепринятым). Впоследствии семейство этих баз данных получило интегрированное наименование Xbase.
Несмотря на неизбежные различия, обусловливавшиеся замыслами разработчиков, все перечисленные системы в ходе своей эволюции приобрели ряд общих конструктивных черт, среди которых, прежде всего, могут быть названы:
- наличие визуального интерфейса, автоматизирующего процесс создания средств манипуляции данными, - экранных форм, шаблонов отчетов, запросов и т. п.;
- наличие инструментов создания объектов базы данных в режиме диалога: Experts в Paradox, Wizards в Access, Assistants в Approach;
- наличие развитого инструментария создания программных расширений в рамках единой среды СУБД: язык разработки приложений PAL в Paradox, VBA (Visual Basic for Applications) в Access, Lotus Script в Approach;
- встроенная поддержка универсальных языков управления данными, например SQL или QBE (Query By Example). Среди СУБД, которые, условно говоря, занимают промежуточное положение между настольными и промышленными системами, могут быть названы SQLWindows/ SQLBase фирмы Centura (до 1996 г. Gupta), InterBase (Borland), наконец, Microsoft SQL Server. В завершении раздела необходимо отметить, что в последние годы наметилась устойчивая тенденция к стиранию четких граней между настольными и профессиональными системами. Последнее, в первую очередь, объясняется тем, что разработчики в стремлении максимально расширить потенциальный рынок для своих продуктов постоянно расширяют набор их функциональных характеристик.
|
|
|
