 |


Взаимодействие компонентов БнД
|
|
|
|
На рис. 1.10 представлена упрощенная схема взаимодействия компонентов БнД в процессе создания и эксплуатации системы. Создание БД начинается с проектирования БД и ее описания на ЯОД (1). На этапе проектирования структуры БД могут использоваться как методики «ручного» проектирования, так и CASE -средства, автоматически генерирующие описания БД. Полученные описания должны быть введены в БнД и запомнены в соответствии с требованиями конкретной СУБД (2,3). После того, как описание базы данных сохранено, в базу данных могут вводиться данные (4). При этом СУБД использует метаинформацию, зафиксированную в словаре данных. Заполненная БД может использоваться для извлечения из нее нужной пользователям информации (5). При формулировании запросов используется информация, содержащаяся в схемах и подсхемах. В результате выполнения запроса выходные данные в том или виде выдаются пользователю (6). Кроме собственно затребованных данных при выполнении операций с БнД часто выдается та или иная диагностическая информация (7). Для обеспечения надежности функционирования БнД необходимо выполнять соответствующие процедуры, в частности осуществлять журнализацию (8) выполняемых действий с БД, регулярно архивировать данные (9).

Рис. 1.10 Схема взаимод
Классификация банков данных
Банки данных являются сложными системами, и их классификация может быть произведена как для всего банка данных в целом, так и для каждой его компоненты отдельно; классификация для каждого из компонентов может быть проведена по множеству разных признаков (рис. 1.12).
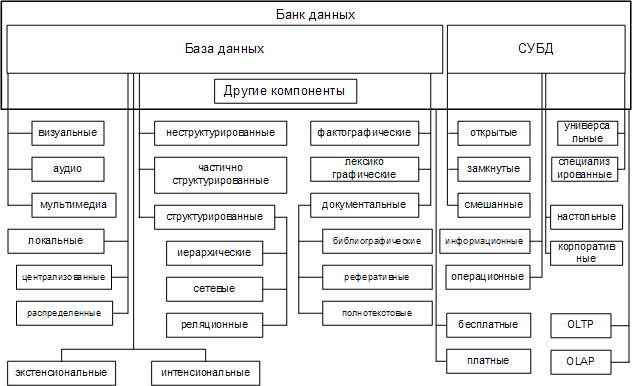
Рис. 1.12. Классификация БнД
Классификация баз данных
Центральной компонентой банка данных является база данных, и большинство классификационных признаков относятся именно к ней. По форме представления информации различают визуальные — и аудио системы, а также системы мультимедиа. Эта классификация показывает, в каком виде информация храниться в БД и выдается из баз данных пользователям: в виде изображения, звука или имеется возможность использования разных форм отображения информации. Понятие "изображение" здесь используется в широком смысле: это может быть символьный текст, неподвижное графическое изображение (рисунки, чертежи и т.п.), фотографии, географические карты, движущие изображения. Классификация способов представления информации являет собой самостоятельную проблему и здесь не рассматривается.
|
|
|
По характеру организации данных БД могут быть разделены на неструктурированные, частично структурированные и структурированные. Этот классификационный признак относится к информации, представленной в символьном виде. К неструктурированным БД могут быть отнесены базы, организованные в виде семантических сетей. Частично структурированными можно считать базы данных в виде обычного текста или гипертекстовые системы. Структурированные БД требуют предварительного проектирования и описания структуры БД. Только после этого базы данных такого типа могут быть заполнены данными.
Структурированные БД в свою очередь по типу используемой модели делятся на иерархические, сетевые, реляционные, смешанные и мультимодельные.
Классификация по типу модели распространяется не только на базы данных, но и на СУБД.
В структурированных БД обычно различают несколько уровней информационных единиц, входящих одна в другую. Число этих уровней может быть различным даже для систем, относящихся к одному и тому же классу. Большинство структурированных систем поддерживают уровень поля, записи и файла. Эти информационные единицы могут называться в разных системах по разному, но суть остается одной и той же, а именно: полю соответствует наименьшая семантическая единица информации; совокупность полей или и иных, более сложных информационных единиц, если они допустимы в конкретной СУБД, образуют запись, а множество однотипных записей представляют файл базы данных. В последнее время большинство СУБД в явном виде поддерживают и уровень базы данных, как совокупности взаимосвязанных файлов БД.
|
|
|

Рис. 1. 13. Схема иерархической модели
В иерархических (Рис. 1.13) и сетевых (Рис. 1.14) моделях между информационными единицами (записями разных файлов) могут задаваться связи. Как видно из приведенных схем, графическое представление иерархической модели представляет собой граф типа «дерево». В такой модели имеется одна вершина – корень дерева, являющаяся входом в структуру. Каждая вершина, отличная от корня, может иметь только одну исходную вершину и, в общем случае, сколько угодно порожденных вершин.
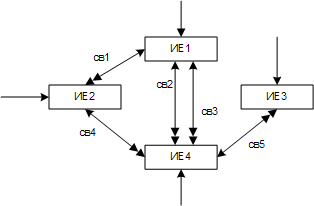
Рис. 1. 13. Схема иерархической модели
Графическое представление сетевой модели представляет собой граф типа «сеть». Входом в такую структуру может являться любая вершина. Каждая вершина может иметь как несколько порожденных, так и несколько исходных вершин. Между парой вершин может быть объявлено несколько связей. Подавляющее большинство СУБД поддерживает простые сетевые структуры, т. е. между каждой парой типов записей поддерживается отношение 1:М. Направление и характер связи в сетевых моделях не является очевидными, как в случае иерархической модели, поэтому при изображении структуры БД направление связи должно быть указано.

Рис. 1. 15. Схема сетевой модели с разнотипными файлами
Кроме сетевых моделей с равноправными файлами существуют сетевые модели с разнотипными файлами. В таких моделях различают главные (основные) и зависимые файлы (рис. 1.15). Вход в структуру возможен только через главные файлы. Связываться между собой могут только записи разных типов.
Связи в иерархических и сетевых моделях описываются при проектировании БД. Чаще всего эти связи при хранении данных в БД передаются посредством адресных указателей. Иерархические и сетевые модели БД не накладывают ограничения на тип внутризаписной структуры. В принципе она может быть любой, как простой линейной (т. е. состоять только из простых полей, следующих в записи последовательно друг за другом), так и сложной иерархической, включающей в себя различные составные единицы информации (векторы, повторяющиеся группы и т. п.). Конкретные же СУБД накладывают ограничения на допустимые в них информационные единицы, характер связей между ними, порядок их расположения в записи, а также часто имеют и различные количественные ограничения.
|
|
|
Особое место среди структурированных систем занимают системы, построенные на использовании инвертированных файлов. Особенность организации данных в них состоит в том, что собственно хранимые данные и информация о связях между логически и физически отделены друг от друга. Основные данные в этих системах хранятся в файлах, записи которых могут иметь сложную структуру. Вся управляющая информация сосредоточена в ассоциаторе. Логическая связь между файлами устанавливается посредством компонента ассоциатора, называемого сетью связи. На рис. 1.16 схематически представлен принцип установления связей в таких системах. Реально, связи устанавливаются не непосредственно с элементами связи, как это изображено на рисунке, а через преобразователь адреса. В системах, построенных на инвертированных файлах, можно передавать связь типа М:М между записями файлов (что не позволяют никакие другие системы). Отделение ассоциативной информации от собственно хранимых данных позволяет изменять связи, не изменяя при этом самих файлов.

Рис. 1.16. Схема организации данных в системах, основанных на инвертированных файлах
В реляционных моделях (в отличие от иерархических и сетевых) связи между файлами БД определяются динамически в момент выполнения запроса. Эти связи определяются по равенству значений соответствующих полей (полей связи), содержащихся в каждом из связанных файлов.
Другой отличительной чертой реляционных моделей является ограничение на внутризаписную структуру: записи имеют линейную структуру и могут содержать только простые поля (рис. 1.17).
|
|
|

Рис. 1.17. Схема реляционной модели
Эти отличительные особенности играют решающую роль при проектировании структуры БД.
Восьмидесятые годы были временем интенсивного развития реляционных систем. В 1992 году [1] уровень продаж реляционных СУБД впервые превысил уровень продаж нереляционных СУБД. Но до 90% данных предприятий хранилось к этому моменту в нереляционных базах данных на мэйнфреймах.
По типу хранимой информации БД делятся на документальные, фактографические и лексикографические. Среди документальных баз различают библиографические, реферативные и полнотекстовые. К лексикографическим базам данных относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.).
В системах фактографического типа в БД хранится информация об интересующих пользователя объектах предметной области в виде «фактов» (например, биографические данные о сотрудниках, данные о выпуске продукции производителями и п. т.); в ответ на запрос пользователя выдается требуемая ему информация об интересующем его объекте/объектах или сообщение о том, что искомая информация отсутствует в БД.
В документальных БД единицей хранения является какой-либо документ (например, текст закона или статьи) и пользователю в ответ на его запрос выдается либо ссылка на документ, либо сам документ, в котором он может найти интересующую его информацию.
БД документального типа могут быть организованы по-разному: без хранения и с хранением самого исходного документа на машинных носителях. К системам первого типа можно отнести библиографические и реферативные БД, а также БД-указатели, «отсылающие» к источнику информации. Системы, в которых предусмотрено хранение полного текста документа, так и называются полнотекстовыми.
В системах документального типа целью поиска может быть не только какая-то информация, хранящаяся в документах, но и сами документы. Так, возможны запросы типа «сколько документов было создано за определенный период времени» и т. п. Часто в критерий поиска в качестве признаков включаются «дата принятия документа», «кем принят» и другие «выходные данные» документов.
Специфической разновидностью баз данных являются базы данных форм документов. Они обладают некоторыми чертами документальных систем (ищется документ, а не информация о конкретном объекте, форма документа имеет название, по которому обычно и осуществляется ее поиск), так и специфическими особенностями (документ ищется не с целью извлечь из него информацию, а с целью использования его в качестве «шаблона»).
|
|
|
В последние годы активно развивается объектно-ориентированный подход к созданию информационных систем. Объектные базы данных организованы как объекты и ссылки к объектам. Объект представляет собой данные и правила, которые оперируют этими данными. Объект включает метод, который является частью определения объекта и запоминается вместе с объектом. В объектных базах данных данные запоминаются как объекты, классифицированные по типам классов и организованные в иерархическое семейство классов. Класс — коллекция объектов с одинаковыми свойствами. Объекты принадлежат классу. Классы организованы в иерархии.

Рис. 1.18. Классификация БнД по характеру хранения данных и обращения к ним
По характеру организации хранения данных и обращения к ним различают локальные (персональные), общие (интегрированные, централизованные) и распределенные базы данных (Рис. 1.18).
Персональная база данных[2] — это база данных, предназначенная для локального использования одним пользователем. Локальные БД могут создаваться каждым пользователем самостоятельно, а могут извлекаться из общей БД.
Интегрированные и распределенные БД предполагают возможность одновременного обращения нескольких пользователей к одной и той же информации (многопользовательский, параллельный режим доступа). Это привносит специфические проблемы при их проектировании и в процессе эксплуатации БнД. Распределенные БД кроме этого имеют характерные особенности, связанные с тем, что физически разные части БД могут быть расположены на разных ЭВМ, а логически, с точки зрения пользователя они должны представлять собой единое целое.
Технологии, которые на первый взгляд вроде бы находятся на разных концах спектра (локальная и распределенная обработка), на самом деле очень близки и различаются практически тем, как поддерживается связь между отдельными частями БД. В случае локальных систем поддержание этой связи не является централизованной, а в случае распределенных БнД — должна поддерживаться СУБД. Технологией, позволяющей совмещать идеи локальной работы и централизованного поддержания единой БД, является технология тиражирования, при которой средства СУБД позволяют тиражировать отдельные части общей БД, локально использовать их, а потом «согласовывать» отдельные фрагменты БД в рамках единой базы данных.
Концепции централизованной и распределенной обработки данных также не так сильно различаются между собой, как кажется на первый взгляд. Так называемые клиент-серверные системы с «тонким клиентом» очень близки к централизованным базам данных.
Банк данных является сложной человеко-машинной системой, и распределяться по узлам сети могут не только БД, но и другие компоненты БнД. Причем сама БД при этом может быть и не распределенной (например, при обеспечении многопользовательского доступа к централизованной БД в сети). Поэтому будем различать два понятия: распределенные БД и распределенные БнД. При этом под распределенным БнД будем понимать банк данных, в котором распределена хотя бы одна любая из его компонент.
В [15] различают экстенсиональные (ЭБД) и интенсиональные БД. Интенсиональная база данных (ИБД) строится с помощью правил, определяющих ее содержание, а не с помощью явного хранения данных в БД, как в экстенсиональных БД.
Например, пусть имеется ЭБД, содержащая таблицу ЛИЧНОСТЬ (PERSON), которая содержит сведения о личности, и среди полей которой есть поля ФАМИЛИЯ_ИМЯ_ОТЧЕСТВО (FIO), ПОЛ (SEX). Мы можем построить в этой ЭБД вторую таблицу РОДИТЕЛЬ (PARENT), которая содержит поля ФАМИЛИЯ_ИМЯ_ОТЧЕСТВО родителя (FIO) и ИМЯ_РЕБЕНКА (CHILD). С помощью правил мы можем определить, например, отношение ОТЕЦ (FATHER), просто указав, что отец это родитель, у которого пол – мужской. На ПРОЛОГе это отношение можно определить следующим образом:
father (X, Y):= person (X, male), parent (X, Y).
Если выполнить это правило, то получится отношение, которое содержит подмножество кортежей таблицы PARENT, таких, для которых верно указанное условие. Пользователю эти данные выдадутся в виде обычного отношения.
Данное определение ЭБД и ИБД можно расширить и на другой (не реляционный) тип БД, и другой способ задания правил. В более общем виде можно сказать, что информацию можно передать и в виде данных, и в виде программ (строго говоря, программы тоже являются данными, но в русском языке нет подходящего термина, который можно было бы здесь употребить вместо слова "данные").
БД классифицируются по объему. Особое место здесь занимают так называемые очень большие базы данных. Это вызвано тем, что для больших баз данных по иному стоят вопросы обеспечения эффективности хранения информации и обеспечения ее обработки.
Классификация СУБД
Рассмотрим теперь ряд классификационных признаков, относящихся к СУБД. По языкам общения СУБД делятся на открытые, замкнутые и смешанные.
Открытые системы — это системы, в которых для обращения к базам данных используются универсальные языки программирования. Замкнутые системы имеют собственные языки общения с пользователями БнД.
По числу уровней в архитектуре различают одноуровневые, двухуровневые, трехуровневые системы. В принципе возможно выделение и большего числа уровней. Под архитектурным уровнем СУБД понимают функциональный компонент, механизмы которого служат для поддержки некоторого уровня абстракции данных (логический и физический уровень, а также "взгляд" пользователя –внешний уровень).

Рис 1.19. Классификация СУБД по числу уровней в архитектуре (пример трехуровневой архитектуры)
На рис. 1.19 сделана попытка совместить терминологию, встречающуюся в разных литературных источниках. В литературе широко используются понятия "внешняя", "концептуальная" и внутренняя" модель/уровень (см., например, [9], и др), а также "логический" и "физический" уровень [15], а кроме того "внешняя схема", "подсхема", "схема хранения", просто "схема" и проч. Понятие схема с тем или иным уточнением обычно относится к описанию соответствующего уровня описания данных.
Нумерация уровней на рисунке условна, но тем нее менее отражает их значимость (внутренняя модель может быть построена только на основе концептуальной; эти два уровня могут быть совмещены, но поддерживаются СУБД всегда; внешний уровень в архитектуре СУБД может отсутствовать).
По выполняемым функциям СУБД делятся на информационные и операционные. Информационные СУБД позволяют организовать хранение информации и доступ к ней. Для выполнения более сложной обработки необходимо писать специальные программы. Операционные СУБД выполняют достаточно сложную обработку, например, автоматически позволяют получать агрегированные показатели, не хранящиеся непосредственно в базе данных, могут изменять алгоритмы обработки и т.д.
По сфере возможного применения различают универсальные и специализированные, обычно проблемно-ориентированные СУБД.
Системы управления базами данных поддерживают разные типы данных. Набор типов данных, допустимых в разных СУБД, различен. Кроме того, ряд СУБД позволяет разработчику добавлять новые типы данных и новые операции над этими данными. Такие системы называются расширяемыми системами баз данных (РСБД).
Дальнейшим развитием концепции РСБД являются системы объектно-ориентированных баз данных (СООБД), обладающие достаточно мощными выразительными возможностями, чтобы непосредственно моделировать сложные объекты.
По «мощности» СУБД делятся на «настольные» и «корпоративные». Характерными чертами настольных СУБД являются сравнительно невысокие требования к техническим средствам, ориентация на конечного пользователя, низкая стоимость.
Корпоративные СУБД обеспечивают работу в распределенной среде, высокую производительность, поддержку коллективной работы при проектировании систем, имеют развитые средства администрирования и более широкие возможности поддержания целостности.
В связи с выше перечисленными чертами корпоративных СУБД очевидно, что эти системы сложны, дороги, требуют значительных вычислительных ресурсов.
| Табл. 1.1 — Сравнение «настольных» и «корпоративных» СУБД | ||
| Критерий | настольные | корпоративные |
| Простота использования | + | |
| Стоимость программного обеспечения | + | |
| Стоимость эксплуатации | + | |
| Функциональные возможности, в т. ч.: • возможности администрирования • возможности работы с Интернет/Интранет и др. | + | |
| Надежность функционирования | + | |
| Поддерживаемые объемы данных | + | |
| Быстродействие | + | |
| Возможности масштабирования | + | |
| Работа в гетерогенной среде | + |
Системы обоих классов интенсивно развиваются, причем некоторые тенденции развития присущи каждому из этих классов. Прежде всего, это использование высокоуровневых средств разработки приложений (что раньше было присуще, в основном, настольным системам), рост производительности и функциональных возможностей, работа в локальных и глобальных сетях и др.
Наиболее известными из корпоративных СУБД являются Oracle, Informix, Sybase, MS SQL Server, Progress и некоторые другие.
Наблюдается связь между классом СУБД и используемой операционной системой. Системы под UNIX позиционируются как корпоративные распределенные системы. Сейчас в этот сектор «пробивается» Windows NT и заменяющая ее Windows 2000.
По ориентации на преобладающую категорию пользователей можно выделить СУБД для разработчиков и для конечных пользователей. Системы, относящиеся к первому классу, должны иметь качественные компиляторы и позволять создавать «отчуждаемые» программные продукты, обладать развитыми средствами отладки, включать средства документирования проекта и обладать другими возможностями, позволяющими создавать эффективные сложные системы. Основными требованиями, предъявляемыми к системам, ориентированным на конечного пользователя, являются: удобство интерфейса, высокий уровень языковых средств, наличие интеллектуальных модулей подсказок, повышенная защита от непреднамеренных ошибок («защита от дурака») и т. п.
|
|
|
