 |


Основные свойства точечных оценок
|
|
|
|
Для того чтобы оценка  имела практическую ценность, она должна обладать следующими свойствами:
имела практическую ценность, она должна обладать следующими свойствами:
1. Оценка параметра q называется несмещенной, если ее математическое ожидание равно оцениваемому параметру q, т.е.
М =  q. (12)
q. (12)
Если равенство (12) не выполняется, то оценка может либо завышать значение q (М > q), либо занижать его (М < q). Естественно в качестве приближенного неизвестного параметра брать несмещенные оценки для того, чтобы не делать систематической ошибки в сторону завышения или занижения.
2. Оценка  параметра q называется состоятельной, если она подчиняется закону больших чисел, т.е. сходится по вероятности к оцениваемому параметру при неограниченном возрастании числа опытов (наблюдений) и, следовательно, выполняется следующее равенство:
параметра q называется состоятельной, если она подчиняется закону больших чисел, т.е. сходится по вероятности к оцениваемому параметру при неограниченном возрастании числа опытов (наблюдений) и, следовательно, выполняется следующее равенство:
 , (13)
, (13)
где e > 0 сколько угодно малое число.
Для выполнения (13) достаточно, чтобы дисперсия оценки стремилась к нулю при  , т.е.
, т.е.
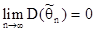 (14)
(14)
И кроме того, чтобы оценка была несмещенной. От формулы (14) легко перейти к (13), если воспользоваться неравенством Чебышева.
Итак, состоятельность оценки означает, что при достаточно большом количестве опытов и со сколько угодно большой достоверностью отклонение оценки от истинного значения параметра меньше любой наперед заданной величины. Этим оправдано увеличение объема выборки.
Так как - случайная величина, значение которой изменяется от выборки к выборке, то меру ее рассеивания около математического ожидания q будем характеризовать дисперсией D . Пусть  и
и  - две несмещенные оценки параметра q, т.е. M = q и M = q, соответственно D и D и, если D
- две несмещенные оценки параметра q, т.е. M = q и M = q, соответственно D и D и, если D  < D
< D 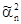 , то в качестве оценки принимают .
, то в качестве оценки принимают .
|
|
|
3. Несмещенная оценка , которая имеет наименьшую дисперсию среди всех возможных несмещенных оценок параметра q, вычисленных по выборкам одного и того же объема, называется эффективной оценкой.
На практике при оценке параметров не всегда удается удовлетворить одновременно требованиям 1, 2, 3. Однако выбору оценки всегда должно предшествовать ее критическое рассмотрение со всех точек зрения. При выборке практических методов обработки опытных данных необходимо руководствоваться сформулированными свойствами оценок.
В статистике законы распределения так же применяются и для изучения показателей уровня жизни населения. С ними мы познакомимся в следующей главе.
2.Уровень жизни населения и его показатели
2.1.Оценка и виды уровня жизни населения
Главной целью общественного развития является повышение уровня жизни населения.
Термин «уровень жизни» был введен ООН в 1961 году. Его количественная характеристика до сих пор точного определения не имеет.
Уровень жизни – комплексный показатель, характеризующий благосостояние и качество жизни граждан или социальных групп отдельной страны или территории. УЖ представляет собой уровень потребления этих благ, отражает благосостояние населения и характеризуется системой следующих показателей:
· объем реальных доходов на душу населения;
· структура потребления продовольствия, непродовольственных товаров, услуг;
· уровень и динамика цен на основные товары народного потребления;
· ставки квартирной платы, жилищных услуг;
· объем выплат и льгот из общественных фондов потребления;
· уровень образования, медобслуживания.
|
|
|
Национальное богатство является той средой, где создаются необходимые условия для благополучной в материальном отношении жизни людей, где формируется и поддерживается уровень жизни населения (благосостояние). Под уровнем жизни населения в статистике понимается обеспеченность населения теми благами и услугами, которые необходимы и достаточны для удовлетворения как жизненно важных материальных потребностей людей (питание, одежда, жилище, предметы культуры и быта), так и социально-культурных (труд, занятость, досуг, здоровье, образование, природная среда обитания и т.д.).
В денежном выражении вся данная совокупность благ и услуг, фактически потребляемых в течение данного времени в домохозяйстве, представляет собой стоимость жизни.
В статистике выделяют следующие виды уровня жизни:
· достаток (пользование благами и услугами, которые обеспечивают всестороннее развитие человека);
· нормальный уровень (потребление благ и услуг по научно обоснованным нормам, которые достаточны для полноценного восстановления физических и интеллектуальных сил человека);
· бедность (потребление благ и услуг на уровне возможности сохранения работоспособности человека);
· нищета (минимальное потребление благ и услуг на уровне биологического выживания человека).
Чтобы получить всю совокупность характеристик по уровню жизни, исследуются все статистические совокупности:
· население в целом;
· отдельные социальные и профессиональные группы;
· домохозяйства с различным доходом.
В мировой практике накоплен определенный опыт по комплексному исследованию уровня жизни населения по основным социально-экономическим показателям, из которых можно выделить следующие:
· показатели прожиточного минимума;
· показатели дифференциации населения;
· показатели денежных доходов (в среднем на душу населения в месяц);
· средний размер пенсий;
· показатели расходов и потребления населения;
· показатели покупательной способности населения;
· достигнутый уровень образования;
· показатели расходов в социальной сфере;
· продолжительность жизни и уровень рождаемости и т.д.
Информационными источниками для построения системы показателей по уровню жизни населения являются данные из материалов различных разделов государственной статистики (демографической, статистики труда, статистики цен, социальной статистики), материалы выборочных обследований бюджетов домохозяйств, материалы переписи населения.
|
|
|
Одним из важнейших обобщающих показателей уровня жизни являются доходы населения. Одним из показателей доходов является объем личных доходов населения (ЛДН) – все виды доходов населения, полученные в денежной форме или натуре.
Совокупные (общие) доходы населения (СДН) определяются суммированием личных доходов и стоимости бесплатных или льготных услуг, оказываемых населению за счет социальных фондов.
Изменение состава и использования денежных доходов населения России приведено в табл. 4(см. приложение2).
Анализ данных таблицы показывает снижение доли социальных выплат в денежных доходах при одновременном увеличении доходов от собственности. В расходах отмечается снижение покупательной способности и увеличение расходов на оплату услуг.
Номинальные показатели доходов – показатели, рассчитанные в ценах текущего периода (оплата труда, соц. трансферты, доходы от собственности и др.). Они не определяют реального содержания доходов, не показывают, какое количество материальных благ и услуг доступно населению при сложившемся уровне доходов.
Вычитая из личных номинальных доходов населения (ЛДН) налоги, обязательные платежи и взносы в общественные организации (НП), находят личные располагаемые доходы (ЛРД) населения – часть личных доходов, которую их владельцы направляют на потребление и сбережение:
ЛРД = ЛДН – НП. (15)
Доля этой части в общем объеме составит:
d =  =
=  . (16)
. (16)
Среднедушевые денежные доходы населения (или средние по домашним хозяйствам) исчисляют делением общей суммы денежного дохода за год на среднегодовую численность населения (или число домашних хозяйств). Таблицу среднедушевых доходов населения представлена в таблице 5 (приложение 3).
|
|
|
2.2. Методы изучения динамики реальных доходов населения
При наличии инфляции на всякий темп роста денежных доходов может свидетельствовать об ухудшении уровня жизни населения.
С целью устранения фактора изменения цен, приводящего к изменению покупательной способности денег, номинальные и располагаемые денежные расходы (доходы) населения рассчитываются в реальном выражении с корректировкой на индексы потребительских цен (сводный и субиндексы на отдельные товарные группы).
Расчет показателей в реальном выражении осуществляется делением соответствующих показателей текущего периода на индекс потребительских цен (ИПЦ рубля), или умножением на индекс покупательной способности денег (ИПЦ).
Реальные располагаемые доходы населения рассчитываются по формуле:
РРД = (ЛДН - НП) * Iп.с.р., (17)
где Iп.с.р. =  .
.
Аналогично рассчитываются реальные общие доходы (РОД) населения – как совокупные доходы (СДН) с поправкой на покупательную способность денег:
РОД = 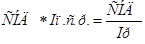 . (18)
. (18)
Динамика реальных денежных доходов населения представлена в таблице 6 (приложение 4).
2.3. Потребление населением материальных благ и услуг
Важными характеристиками уровня жизни населения являются уровень и структура потребления материальных благ и услуг, где объектами статистического наблюдения являются потребительские единицы (условная единица). Они дают возможность сопоставить между собой по уровню потребления домашние хозяйства с различными по возрасту и полу потребительскими единицами (по шкале коэффициентов приведения за условную потребительскую единицу принимается, например, мужчина в возрасте 18-59 лет). Используя потребительскую единицу, можно рассчитать показатель среднедушевого потребления как отношение количества потребленного продукта питания к числу условных потребителей.
Важнейшей реальной величиной конечного потребления является объем фактического потребления домашних хозяйств, которое обеспечивается не только за счет реального дохода, но и за счет социальных трансфертов.
Объем фактического потребления включает потребление товаров и услуг. Все товары, потребляемые населением, имеют следующую структуру:
· товары первой необходимости (продукты питания, повседневная одежда, жилье и т.д.);
· товары отложенной необходимости (книги, бытовая техника, теле- и радиоаппаратура, машины и т.д.);
|
|
|
· предметы роскоши (дорогая одежда, дорогая мебель, ювелирные изделия, деликатесные продукты питания и т.д.).
В объеме услуг принято выделять:
· услуги производственные (ремонт бытовой техники, ремонт предметов повседневного потребления и т.п.);
· услуги хозяйственного назначения (внутренний ремонт жилья, наружный ремонт жилья и т.п.);
Все услуги могут быть предоставлены либо на бесплатной основе, либо на платной (рыночные услуги).
Часть денежных затрат на покупку потребительских товаров и личных услуг текущего потребления есть потребительские расходы населения. Почти половину всех расходов в бюджете домашних хозяйств составляют затраты на питание. Расходы на питание представлены в таблице 7 (приложение 5).
Чем выше абсолютная величина затрат на питание в среднем на одного члена домохозяйства, тем ниже уровень жизни данного домохозяйства, и наоборот.
Широко используемым статистическим показателем потребления является уровень личного потребления (индивидуального потребления). Он исчисляется как отношение объема товаров и услуг, потребленных населением за год, к среднегодовой численности населения, как в целом, так и по групповым показателям. Статистические данные личного потребления характеризуют не только благосостояние населения, но и важны для определения многих макроэкономических показателей.
В статистике потребления используются различные коэффициенты и индексы.
Динамика общего потребления изучается с помощью агрегатного индекса объема потребления Iоп, который рассчитывается следующим образом:
 (19)
(19)
где Iоп - агрегатный индекс объема потребления;
a1, a0 - количество потребленных товаров в отчетном и базисном периодах;
b1, b0 - количество потребленных услуг в отчетном и базисном периодах;
p0, r0 - цена товара и тариф за определенную услугу в базисном периоде.
При статистическом исследовании зависимости объема потребления от дохода используется коэффициент эластичности Кэ, который характеризует величину возрастания или снижения потребления товаров и услуг при росте дохода на 1% (в теории статистики это формула А. Маршалла):
 (20)
(20)
где Кэ - коэффициент эластичности;
х, у - начальные доход и потребление;
x, y – их приращения за некоторый период (или при переходе от одной группы к другой).
Если Кэ > 1, то потребление растет быстрее, чем доходы.
Если Кэ = 1, то между доходом и потреблением имеет место пропорциональная зависимость.
Если Кэ < 1, то доход растет быстрее, чем потребление.
2.4. Показатели социальной дифференциации и бедности населения
Уровень жизни характеризуется показателями дифференциации материальной обеспеченности населения (дифференциации населения по уровню дохода), среди которых можно выделить:
· распределение населения по уровню среднедушевых денежных доходов;
· коэффициент дифференциации доходов;
· индекс концентрации доходов (коэффициент Джини);
· коэффициент бедности.
Важнейшим методом исследования дифференциации доходов населения является распределение населения по уровню среднедушевых денежных доходов на основе построения вариационных рядов. Эмпирические данные выборочного обследования бюджетов домашних хозяйств ранжируются и группируются в определенных интервалах по величине дохода. Для статистических характеристик здесь используются: среднее значение душевого дохода; модальный доход (чаще всего встречающийся уровень дохода населения); медианный доход (показатель дохода, расположенный в середине ранжированного ряда распределения); средний доход (общий средний уровень дохода всего населения).
Данные о распределении населения России по размеру среднедушевых денежных доходов с 2000 по 2006 г. Приведены в таблице 5(см. приложение 3).
Модальный и медианный доходы - это важные структурные показатели, которые характеризуют отклонение среднедушевого дохода от среднего значения для каждой группы. Как правило, результаты исследований свидетельствуют, что одна половина населения имеет доход ниже среднего, а вторая половина - выше среднего.
Широко распространен в статистических исследованиях по неравенству в распределении доходов децильный коэффициент дифференциации доходов, который исчисляется как отношение минимального дохода у 10% наиболее обеспеченных граждан к максимальному доходу 10% наименее обеспеченных граждан. Коэффициент дифференциации доходов Кd рассчитывается путем сопоставления девятого (d9) и первого (d1) децилей:
 . (21)
. (21)
где Кd - коэффициент дифференциации доходов;
d9 - девятый дециль;
d1 - первый дециль.
Нижний дециль (d1) – самые низкие доходы, определяется по формуле:
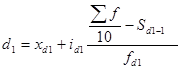 . (22)
. (22)
Верхний предел (d9) – самые высокие доходы, определяется по формуле:
 =
=  . (23)
. (23)
Функционально очень близким к децильному коэффициенту дифференциации доходов является коэффициент фондов Кф, с помощью которого измеряют различие между суммарными (средними) значениями доходов 10% наиболее обеспеченной (Ч10) и 10% наименее обеспеченной (Ч1) части населения.
 (24)
(24)
где Кф - коэффициент фондов;
Ч10 - наиболее обеспеченная часть населения;
Ч1 - наименее обеспеченная часть населения.
Индекс концентрации доходов (коэффициент Джини) КG служит для измерения отличия фактического распределения доходов по численно равным группам населения от их равномерного распределения (степень неравенства в распределении доходов населения). Данный индекс исчисляется по формуле:
 . (25)
. (25)
где КG - индекс концентрации доходов (коэффициент Джини);
xi – доля населения принадлежащая к (i-1) социальной группе в общей численности населения;
yi – доля доходов, сосредоточенная у i-той социальной группы населения;
n – число социальных групп;
cum yi - кумулятивная (исчисленная нарастающим итогом) доля дохода.
Коэффициент Джини изменяется в пределах от 0 (совершенное равенство) до 1 (совершенное неравенство), т.е. чем ближе индекс к 1, тем выше поляризация доходов в обществе. В России максимальная дифференциация доходов населения достигла в 2006 г., когда коэффициент Джини имел значение 0,410 (для сравнения в 2000 г. – 0,395).
Для статистических характеристик уровня жизни важно установление границ дохода, обеспечивающих минимально допустимый уровень, т.е. определение прожиточного минимума (стоимостная оценка минимального набора продовольственных и непродовольственных товаров, а также обязательные платежи и сборы). Прожиточный минимум позволяет установить границы бедности. Данные Приведены в таблице 8 (Приложение 6).
Коэффициент бедности - относительный показатель, который рассчитывается как процентное отношение численности граждан, чьи доходы ниже прожиточного минимума, к общей численности населения страны. В настоящее время (с 1990 г.) в мире установлен порог бедности, равный 1 доллару США в день.
Теперь рассмотрим практическое применение законов распределения при изучении показателей уровня жизни населения. При изучении и решении задач по теории вероятностей и математической статистике, статистике, многомерным статистическим методам, эконометрике студенты сталкиваются с трудностями, вызванными громоздкостью и сложностью вычислительных процедур, что в конечном итоге приводит к большим интеллектуальным усилиям и неоправданным временным затратам. Чтобы улучшить содержательную часть решаемых задач; повысить эффективность учебного процесса за счет сокращения рутинных процедур, эффективного поиска правильного решения за счет быстрой, программной реализации большого количества альтернативных способов решения применяются статистические пакеты прикладных программ. C одним из них мы познакомимся в следующей главе.
3.Практическое применение законов распределения при изучении уровня жизни населения
3.1. Расчет статистических характеристик величин с использованием пакета MINITAB.
Статистический пакет MINITAB был разработан в Пенсильванском государственном университете для облегчения изучения различных статистических дисциплин. Сейчас MINITAB используется более чем в 2000 учебных заведений во всем мире. Более 75 % компаний, входящих в, так называемые Top 50 (по данным журнала Fortune), используют данный пакет в своей работе.
Статистический пакет MINITAB состоит из следующих основных окон:
- окно данных (Data Window);
- окно результатов (Session Window);
- информационное окно (Info Window);
- окно записи использованных команд (History Window);
- графическое окно (Graph Window);
- окно для помощи (Help Window).
Пример 1. По данным таблицы 10 (приложение 7) провести расчет статистических характеристик величин.
В колонках С1, С2 отражены следующие данные:
С1 – валовая доход, в среднем на человека домохозяйства;
С2 – расходы на продукты, в среднем на человека домохозяйства.
Если необходимо получить новый столбец, каждый элемент которого содержал бы сумму (разницу, произведение) двух других, то Осуществление арифметических операций над данными в колонках.
Для этого необходимо выполнить следующие действия: Calc > Calculator На экране появится следующее диалоговое окно:

Рис.1. Внешний вид окна Mathematical Expressions.
Для получение описательной статистики данных, находящихся в одной колонке необходимо выполнить следующие действия: Stat > Basic Statistics > Descriptive Statistics. На экране появится следующее диалоговое окно, которое изображено на рис 2. Необходимо указать название колонки с данными, например, колонка С1-(SALARY).
 |
Рис. 2. Внешний вид окна Descriptive Statistics.
 В результате выполнение данной операции (см. рисунок 3) в окне результатов (Session Window) появится следующие данные:
В результате выполнение данной операции (см. рисунок 3) в окне результатов (Session Window) появится следующие данные:
Рис. 3. Окно результатов (Session Window).
где N – количество данных в столбце SALARY
MEAN – среднее значение;
MEDIAN – значение медианы;
STDEV – среднеквадратическое отклонение;
MIN и MAX – минимальное и максимальное значение валового дохода.
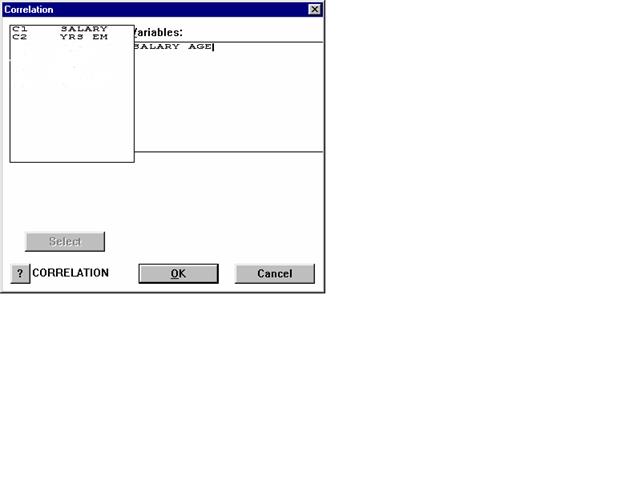 Для расчета коэффициента корелляции необходимо выполнить следующие действия: Stat > Basic Statistics > Correlation. На экране появится следующее диалоговое окно:
Для расчета коэффициента корелляции необходимо выполнить следующие действия: Stat > Basic Statistics > Correlation. На экране появится следующее диалоговое окно:
Рис. 4. Внешний вид окна Correlation.
Для получения коэффициента корреляции между валовым доходом и расходом на продукты необходимо указать в окне «Переменные» (Variables) колонки С1 и С2.
В результате выполнение данной операции в окне результатов (Session Window) появится следующие данные:
Pearson correlation of Salary and Расход на продукту = 0,975.
Мы можем сделать вывод, что между этими показателями присутствует прямая связь, и что показатель расходы на продукцию зависит от валового дохода.
Для получения суммарного показателя по столбцу (суммы, среднего) и т.д. необходимо зайти Calc > Column statistics и заполнить диалоговое окно, как это показано на рисунке 5.
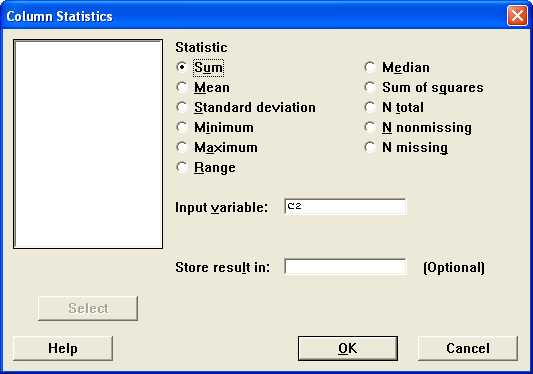
Рис. 5. Диалоговое окно статистики по столбцам.
Ранжирование данных осуществляется следующим образом: Manip > Rank. На экране появится окно, которое показано на рис. 6.

Рис. 6. Внешний вид окна Rank.
Для ранжирования данных необходимо указать следующие характеристики: название колонки, которая будет ранжирована (для этого необходимо дважды щелкнуть мышкой по названию колонки, расположенной на экране с левой стороны) и название колонки, в которой будут храниться ранги колонки.
Для построения графиков необходимо выполнить следующие действия: Graph > (Plot, Chart, Histogram, Boxplot, Time Series Plot). После выбора команды Graph необходимо выбрать один из типов графиков, которые перечислены в скобках. Если выбрали Plot, то в результате на экране появится диалоговое окно, которое показано на рисунке 7.

Рис. 7. Внешний вид диалогового окна Plot.
Необходимо указать какая из колонок будет являться X, а какая Y. После этого нажать OK или клавишу «Enter». На экране появится график, изображенный на рисунке 8.
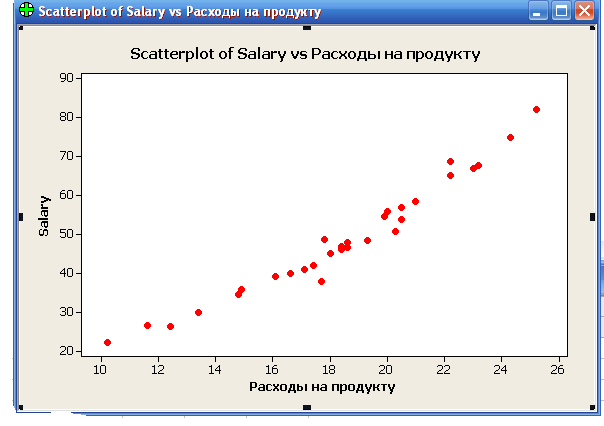
Рис. 8. График, полученный при построении в режиме Plot.
3.2. Дисперсионный анализ показателей уровня жизни населения
Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную. Применим дисперсионный анализ при изучении показателей уровня жизни в следующем пункте.
Дисперсионный анализ – анализ изменчивости признака под влиянием каких-либо контролируемых переменных факторов. С помощью дисперсионного анализа изучим показатели уровня жизни населения, представленные в таблице 13 (см. приложение 8).
Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную. Применим дисперсионный анализ при изучении показателей уровня жизни в следующем пункте.
При исследовании зависимости средней оценки Y по математической статистике в группе от показателей уровня жизни (В1 — расходы на здравоохранение на душу населения, В2— количество больничных коек на 10000 человек, В3— количество человек на 1 врача, В4 — обеспеченность водой на душу населения, В5—протяженность автомобильных дорог,В6—количество человек на 1 транспортное средство), стран (А1—Россия, А2—Азербайджан, А3—Белоруссия, А4—Грузия, А5—Казахстан, А6—Молдавия, А7—Таджикистан, А8—Узбекистан) и их взаимодействия было выделено случайным образом 48 групп, которые приписывались в равных количествах. Данные необходимые для проведения двухфакторного дисперсионного анализа приведены в табл.13(см. приложение8).
1. Детерминированная модель двухфакторного дисперсионного анализа (с повторениями) средней оценки по математической статистике в группе имеет следующий вид:

 =1,2,3,4,5,6;
=1,2,3,4,5,6;  =1,2,3,4,5,6,7
=1,2,3,4,5,6,7
где 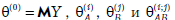 — неслучайные эффекты влияния на наблюдение
— неслучайные эффекты влияния на наблюдение  уровней
уровней  факторов A и B и взаимодействия этих уровней,
факторов A и B и взаимодействия этих уровней,  — случайный эффект влияния прочих неконтролируемых факторов.
— случайный эффект влияния прочих неконтролируемых факторов.
К этой модели предъявляются следующие требования:
· Все n = 6*7=42 случайных величин  или, иначе все 36 наблюдений
или, иначе все 36 наблюдений  должны быть независимыми;
должны быть независимыми;
· 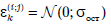 или, иначе,
или, иначе,  , т.е при каждой комбинации уровней факторов наблюдения должны проводиться в одинаковых (нормальных) вероятностных условиях с дисперсией, не изменяющейся при переходе от одной комбинации уровней факторов к другой;
, т.е при каждой комбинации уровней факторов наблюдения должны проводиться в одинаковых (нормальных) вероятностных условиях с дисперсией, не изменяющейся при переходе от одной комбинации уровней факторов к другой;
· 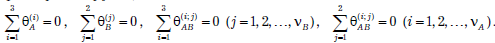
2. Введем исходные данные в рабочий лист Microsoft Excel (рис.9).
Для исследования модели воспользуемся программой «Двухфакторный
дисперсионный анализ с повторениями», выбрав соответствующий пункт меню надстройки «Анализ данных».
В появившемся окне ввода данных (рис. 10) укажем входной интервал
A1:G8, в который мы ввели исходные данные (с заголовками групп строк и столбцов — обозначениями уровней факторов), число строк для выборки
(число наблюдений при каждой комбинации уровней факторов), уровень значимости Альфа (по условию α = 0,05). Укажем, что результаты работы программы необходимо вывести на новый рабочий лист.
Результаты работы программы представлены на рис. 9.

Рис. 9. Числовые данные для программы
«Двухфакторный дисперсионный анализ с повторениями»

Рис.10. Окно ввода данных программы
 «Двухфакторный дисперсионный анализ»
«Двухфакторный дисперсионный анализ»
Рис.11. Результаты работы программы
«Двухфакторный дисперсионный анализ»
Таблица «Дисперсионный анализ», полученная в результате работы программы (рис. 11), представляет собой дисперсионную таблицу.
В этой таблице «Выборка» — это фактор A, «Столбцы» — это фактор В, «Взаимодействие» — это взаимодействие факторов Aи B, «Внутри» — это неконтролируемые факторы, «SS» — сумма квадратов, «df» — число степеней свободы, «MS» – средняя сумма квадратов, равная отношению SS к df, «F» — числовое значение статистики F, соответствующей проверяемой гипотезе, «P-
значение» — это рассчитанный уровень значимости, «F критическое» —
100α%-ная критическая точка распределения Фишера — Снедекора с соответствующими числами степеней свободы.
| Источник вариации величины Y | Показатель вариации (SS) | Число степеней свободы(df) | Оценка дисперсии

|
|
| Фактор А(выборка) |  =0 =0
|  =6 =6
|  =65535 =65535
| |
| Фактор В(столбцы) | 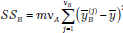 =0 =0
|  =5 =5
|  =
=30922890603 =
=30922890603
| |
| Взаимодействие факторов А и В |  =65535 =65535
|  =1 =1
|  =
=65535 =
=65535
| |
| Остаточные факторы(внутри) |  =15595873525 =15595873525
|  =0 =0
|  =
=623834941 =
=623834941
| |
| Общая вариация |  =27967435937 =27967435937
|  =41 =41
|
Рассмотрим дисперсионную таблицу ниже:
В условиях задачи  =7,
=7,  =6,
=6,  =6.
=6.
 ;
;  ;
;  .
.
Проверим на 5%-ном уровне значимости гипотезу  об отсутствии влияния на среднюю оценку Y фактора A — метода обучения.
об отсутствии влияния на среднюю оценку Y фактора A — метода обучения.
Наблюдаемое значение статистики

равно 65535/623834941=0,00010505.
Если гипотеза  верна, то статистика
верна, то статистика  имеет распределение
имеет распределение
Фишера — Снедекора с =6 и =0 степенями свободы. При проверке гипотезы Р-значение (которое приводится в результатах работы программы в таблице «Дисперсионный анализ» на рис. 9) равно вероятности Р={ 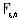 >65535}=0,001554348 (т. е. рассчитанному уровню значимости гипотезы ), и гипотеза , поскольку отвергается, поскольку P < α.
>65535}=0,001554348 (т. е. рассчитанному уровню значимости гипотезы ), и гипотеза , поскольку отвергается, поскольку P < α.
Другой способ получить тот же вывод — сравнить наблюдаемое значение статистики  («F» из таблицы на рис.9) с соответствующей критической точкой
(«F» из таблицы на рис.9) с соответствующей критической точкой  («F критическое» из таблицы на рис.9):гипотеза HA отвергается на 5%-ном уровне значимости, так как наблюдаемое значение статистики (в данном случае 65535) больше критической точки; 2; 12 (в данном случае 1,56781203).
(«F критическое» из таблицы на рис.9):гипотеза HA отвергается на 5%-ном уровне значимости, так как наблюдаемое значение статистики (в данном случае 65535) больше критической точки; 2; 12 (в данном случае 1,56781203).
Аналогичным образом отвергаются гипотезы 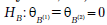 об отсутствии влияния на среднюю оценку Y по математической статистике фактора B — будущей специальности) и
об отсутствии влияния на среднюю оценку Y по математической статистике фактора B — будущей специальности) и  (об отсутствии влияния на среднюю
(об отсутствии влияния на среднюю
оценку Y взаимодействия метода обучения и будущей специальности). Таким образом, метод обучения, будущая специальность и их взаимодействие
влияют на среднюю оценку по математической статистике в группе. Оценим силу этого влияния, вычислив соответствующие коэффициенты детерминации.
3. Поскольку коэффициент детерминации  =0/27967435937=0, то 0% общей вариации средней оценки Y обусловлено неизменчивостью фактора А.
=0/27967435937=0, то 0% общей вариации средней оценки Y обусловлено неизменчивостью фактора А.
Так как  =12371562412/27967435937=0,44, то 44% общей вариации средней оценки Y обусловлено изменчивостью фактора В. Ввиду того, что
=12371562412/27967435937=0,44, то 44% общей вариации средней оценки Y обусловлено изменчивостью фактора В. Ввиду того, что  =0/27967435937=0, 0% общей вариации средней оценки Y обусловлено взаимодействием А и В.
=0/27967435937=0, 0% общей вариации средней оценки Y обусловлено взаимодействием А и В.
Влиянием неконтролируемых факторов обусловлен 100 – 0 – 44 – 0 =66 % вариации средней оценки по математической статистике.
3.3 Практическое применение средних величин показателей вариации при изучении уровня жизни населения
По данным таблицы 10 (см. приложение 7) имеются данные по домашним хозяйствам населения района в тыс.руб.
Построим статистический ряд распределения по признаку валовый доход в среднем на одного члена домохозяйства в год, образовав 5 групп с равными интервалами.
Приступаем к расчетам: х –валовой доход, у – расходы, n = 5, N = 30. Находим величину интервало
|
|
|
