 |


Билет № 2. Оценка параметров классической линейной модели регрессии методом максимального правдоподобия.
|
|
|
|
Ограничения в классической линейной модели регрессии. Свойства оценок коэффициентов при регрессорах, получаемых методом наименьших квадратов. Теорема Гаусса-Маркова.
Корреляция и регрессия взаимосвязаны между собой – корреляция исследует силу(тесноту) связи, регрессия исследует её форму. И та и другая служат для установления соотношения между явлениями, для определения наличия или отсутствия связи. По форме зависимости различают линейную регрессию (уравнение прямой Ῡx = a0 + a1x) и нелинейную (парабола Ῡx=a0 + a1 * x + a2*x^2, гипербола и т.д.). Направление связи – прямая, обратная.
Целью регрессионного анализа является оценка функциональной зависимости математического ожидания результативного признака У от факторных (х1, х2,…).
Метод наименьших квадратов (МНК, OLS, Ordinary Least Squares) — один из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным. Метод основан на минимизации суммы квадратов остатков регрессии.
Оценки, полученные по МНК, обладают следующими свойствами:
1. Оценки параметров являются несмещенными, т. е. M(b1) = β1, M(b0) = β0 (математические ожидания оценок параметров равны их теоретическим значениям). Это вытекает из того, что M(εi) = 0, и говорит об отсутствии систематической ошибки в определении положения линии регрессии. Оценка, для которой смещение – разность между значением параметра и его оценкой – стремится к нулю при возрастании выборки – является асимптотически несмещенной.
2. Оценки параметров состоятельны, если при увеличении объема выборки надежность оценок увеличивается (b1 наверняка близко к β1, b0 — близко к β0), т.е. D(b0) → 0, D(b1) → 0 при n → ∞.
|
|
|
3. Оценки параметров эффективны, т. е. они имеют наименьшую дисперсию по сравнению с другими оценками данных параметров, линейными относительно величин yi.
Т.е. МНК-оценки являются несмещенными линейными оценками с минимальной дисперсией, имеющими нормальное распределение.
В полученном уравнении регрессии параметр а0 показывает усредненное влияние на результативный признак неучтенных факторов; параметр а1, а2 и т.д. показывает, насколько в среднем изменяется значение результативного признака при увеличении факторного на единицу собственного измерения.
Теорема Гаусса-Маркова.
Известно, что для получения по МНК наилучших результатов требуется, чтобы выполнялся ряд предпосылок относительно случайного отклонения. Их также называют предпосылками Гаусса-Маркова. Теорема Гаусса-Маркова гласит, что наилучшие оценки параметров уравнения регрессии могут быть получены при обязательном соблюдении следующих предпосылок:
1. Математическое ожидание случайного отклонения еi равно нулю: M(еi) = 0 для всех наблюдений.
Данное условие означает, что случайное отклонение в среднем не оказывает влияния на зависимую переменную, случайный член может быть положительным или отрицательным, но он не должен иметь систематического смещения.
2. Дисперсия случайных отклонений постоянна: D(εij) = σ2 = const для любых наблюдений i и j.
Условие независимости дисперсии ошибки от номера наблюдения называется гомоскедастичностью (homoscedasticity). Невыполнимость этой предпосылки называется гетероскедастичностью (heteroscedasticity).
Поскольку D(ε)=M((εj - Mεj))2 = M(ε2), то эту предпосылку можно переписать в форме: M(е2i) = σ2.
3. Случайные отклонения εi и εj являются независимыми друг от друга для i ≠ j. Выполнимость этой предпосылки предполагает, что отсутствует систематическая связь между любыми случайными отклонениями. Величина и определенный знак любого случайного отклонения не должны быть причинами величины и знака любого другого отклонения.
|
|
|
Выполнимость данной предпосылки влечет следующее соотношение:
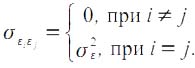
Если данное условие выполняется, то можно говорить об отсутствии автокорреляции.
4. Случайное отклонение должно быть независимо от объясняющих переменных.
Данное условие предполагает выполнимость следующего соотношения:

Заметим, что выполнимость этой предпосылки не столь критична для эконометрических моделей.
5. Модель является линейной относительно параметров. Для случая множественной линейной регрессии существенными являются еще две предпосылки.
6. Отсутствие мультиколлинеарности. Между объясняющими переменными отсутствует сильная линейная зависимость.
7. Случайные отклонения εi, i = 1, 2,..., n, имеют нормальное распределение.
Выполнимость данной предпосылки важна для проверки статистических гипотез и построения интервальных оценок.
Наряду с этим, есть еще некоторые предположения. Например:
· объясняющие переменные не являются случайными величинами;
· число наблюдений намного больше числа объясняющих переменных (числа факторов уравнения);
· отсутствуют ошибки спецификации, т. е. правильно выбран вид уравнения и в него включены все необходимые переменные.
Билет № 2. Оценка параметров классической линейной модели регрессии методом максимального правдоподобия.
Пример из учебника Доугерти про матожидание между 4 и 6.
Этот метод требует знания общего вида распределения анализируемых случайных величин. Для оценивания неизвестных параметров используется следующий факт: распределение переменной yi, условное по совокупности переменных xi, известно вплоть до небольшого количества неизвестных параметров, и следует подбирать эти параметры таким образом, чтобы получающееся распределение «насколько возможно лучше соответствовало наблюдаемым данным».
Допустим, мы имеем урну, наполненную красными и желтыми шарами. Нас интересует доля p красных шаров. Чтобы получить информацию о p, мы извлекаем случайную выборку из N шаров, yi = 1 если шар красный, и yi = 0 если желтых, P (yi=1) = 1. Предположим, что выборка содержит  красных шаров и N – N1 желтых. Вероятность получения такой выборки в заданном виде является
красных шаров и N – N1 желтых. Вероятность получения такой выборки в заданном виде является
|
|
|
P (N1, N-N1) = pN1(1-p)N-N1. Это выражение, интерпретируемое как функция от неизвестного параметра p, называется функцией правдоподобия. Оценивание методом максимального правдоподобия неизвестного параметра p означает, что мы выбираем такое значение p, что вероятность является максимальной. Это значение является оценкой методом максимального правдоподобия (ММП-оценкой). В вычислительных целях удобно максимизировать натуральный логарифм вероятности. Это приводит к логарифмической ф-ии правдоподобия
log L(p) = N1 log(p) + (N-N1) log (1-p)
Максимизация этой функции даёт условие первого порядка

из которого получается решение для неизвестного параметра p, являющееся оценкой методом максимального правдоподобия

Т.о. ММП-оценка соответствует выборочной доле красных шаров, и, вероятно, соответствует наилучшей догадке о параметре p, основанной на извлеченной выборке.
Билет № 3. Проверка значимости и интерпретация коэффициентов классической линейной регрессионной модели. Доверительные интервалы для регрессионной модели и для прогнозных значений зависимой переменной
3.1) Проверка значимости и интерпретация коэффициентов классической линейной регрессионной модели.
Значимость коэффициентов регрессии осуществляется с помощью t-критерия Стьюдента:

Внизу – дисперсия коэффициента регрессии. Параметр модели признаётся статистически значимым, если tp > tкр (α, n = n – k – 1). В скобках – уровень значимости критерия проверки гипотезы о равенстве нулю параметров, измеряющих связь, и число степеней свободы, характеризующих свободно варьирующие элементы совокупности).
Дисперсию можно определить двумя способами: простой, но менее точный
σ2ai=σ2y/k (дисперсия результативного признака на число факторных признаков). Более сложный, но более точный
σai= (σy * (√1-R2))/(σxi * √n * √(1-Ri))
Ri – величина множественного коэффициента корреляции по фактору xi с остальными факторами.
Проверка адекватности всей модели осуществляется с помощью расчета F-критерия и величины средней ошибки аппроксимации ε.
|
|
|
Рассчётное значение Fp сравнивается с Fα, и если Fp> Fα при α=0,05 или 0,01, то Но – гипотеза о несоответствии заложенных в уравнение регрессии связей реально существующим отвергается. Fα определяется по специальным таблицам на основании величины α и числа степеней свободы v1=k-1; v2=n-k (k-число факторных признаков).
Значение средней ошибки аппроксимации не должно превышать 10-15%.

В полученном уравнении регрессии параметр а0 показывает усредненное влияние на результативный признак неучтенных факторов; параметр а1, а2 и т.д. показывает, насколько в среднем изменяется значение результативного признака при увеличении факторного на единицу собственного измерения.
3.2) Доверительные интервалы для регрессионной модели и для прогнозных значений зависимой переменной
стр. 27 учебника?!
|
|
|
