 |


Методы поиска по дереву.
|
|
|
|
Определение: Деревом называется конечное множество, состоящее из одного или более элементов, называемых узлами, таких, что:
- между узлами имеет место отношение типа "исходный-порожденный";
- есть только один узел, не имеющий исходного. Он называется корнем;
- все узлы за исключением корня имеют только один исходный; каждый узел может иметь несколько порожденных;
- отношение "исходный-порожденный" действует только в одном направлении, т.е. ни один потомок некоторого узла не может стать для него предком.
Число порожденных отдельного узла (число поддеревьев данного корня) называется его степенью. Узел с нулевой степенью называют листом или концевым узлом. Максимальное значение степени всех узлов данного дерева называется степенью дерева.
Если в дереве между порожденными узлами, имеющими общий исходный, считается существенным их порядок, то дерево называется упорядоченным. В задачах поиска почти всегда рассматриваются упорядоченные деревья.
Упорядоченное дерево, степень которого не больше 2 называется бинарным деревом. Бинарное дерево особенно часто используется при поиске в оперативной памяти. Алгоритм поиска: вначале аргумент поиска сравнивается с ключом, находящимся в корне. Если аргумент совпадает с ключом, поиск закончен, если же не совпадает, то в случае, когда аргумент оказвается меньше ключа, поиск продолжается в левом поддереве, а в случае когда больше ключа - в правом поддереве. Увеличив уровень на 1 повторяют сравнение, считая текущий узел корнем.
Пример: Пусть дан список студентов, содержащий их фамили и средний бал успеваемости (см. таблицу 1.1). В качестве ключа используется фамилия студента. Предположим, что все записи имеют фиксированную длину, тогда в качестве указателя можно использовать номер записи. Смещение записи в файле в этом случае будет вычислятся как ([номер_записи] -1) * [длина_записи] . Пусть аргумент поиска "Петров". На рисунке 1.2 показаны одно из возможных для этого набора данных бинарных деревьев поиска и путь поиска.
|
|
|
| Таблица 1.1. | |
| Студент | Балл |
| Васильев | 4,2 |
| Иванов | 3,4 |
| Кузнецов | 3,5 |
| Петров | 3,2 |
| Сидоров | 4,6 |
| Тихомиров | 3,8 |

Рис. 1.2.Поиск по бинарному дереву.
Заметим, что здесь используется следующее правило сравнения строковых переменных: считается, что значение символа соответствует его порядковому номеру в алфавите. Поэтому "И" меньше "К", а "К" меньше "С". Если текущие символы в сравниваемых строках совпадают, то сравниваются символы в следующих позициях.
Бинарные деревья особенно эффективны в случае когда множество ключей заранее неизвестно, либо когда это множество интенсивно изменяется. Очевидно, что при переменном множестве ключей лучше иметь сбалансированное дерево.
Определение: Бинарное дерево называют сбалансированным (balanced), если высота левого поддерева каждого узла отличается от высоты правого поддерева не более чем на 1.
При поиске данных во внешней памяти очень важной является проблема сокращения числа перемещений данных из внешней памяти в оперативную. Поэтому, в данном случае по сравнению с бинарными деревьями более выгодными окажутся сильно ветвящиеся деревья - т.к. их высота меньше, то при поиске потребуется меньше обращений к внешней памяти. Наибольшее применение в этом случае получили В-деревья (В - balanced)
Определение: В-деревом порядка n называется сильно ветвящееся дерево степени 2n+1, обладающее следующими свойствами:
- Каждый узел, за исключением корня, содержит не менее n и не более 2n ключей.
- Корень содержит не менее одного и не более 2n ключей.
- Все листья расположены на одном уровне.
- Каждый нелистовой узел содержит два списка: упорядоченный по возрастанию значений список ключей и соответсвующий ему список указателей (для листовых узлов список указателей отсутствует).
Для такого дерева:
|
|
|
- сравнительно просто может быть организован последовательный доступ, т.к. все листья расположены на одном уровне;
- при добавлении и изменении ключей все изменения ограничиваются, как правило, одним узлом.

Рис. 1.3.Сбалансированное дерево.
В -дерево, в котором истинные значения содержатся только в листьях (концевых узлах), называется В+ -деревом. Во внутренних узлах такого дерева содержатся ключи-разделители, задающие диапазон изменения ключей для поддеревьев.
Подробнее о различных видах сбалансированных деревьев, а также методах их реализации можно прочитать в литературе, список которой приведен в конце страницы. Следует отметить, что B - деревья наилучшим образом подходят только для организации доступа к достаточно простым (одномерным) структурам данных. Для доступа к более сложным структурам, таким, например, как пространственные (многомерные) данные в последнее время все чаще используют R -деревья.
R -дерево (R -Tree) это индексная структура для доступа к пространственным данным, предложенная А.Гуттманом (Калифорнийский университет, Беркли). R-дерево допускает произвольное выполнение операций добавления, удаления и поиска данных без периодической переиндексации.
Для представления данных используются записи, каждая из которых имеет уникальный идентификатор (tuple-identifier). В каждом концевом узле (листе) дерева содержится запись вида (I,tuple-identifier), где I - n -мерный параллелепипед, содержащий указатели на пространственные данные (его также называют minimal bounding rectangle, MBR), а каждый элемент в tuple-identifier содержит верхнюю и нижнюю границу параллелепипеда в соответствующем измерении.
Неконцевые узлы содержат записи вида (I, childnode-pointer), где I минимальный ограничивающий параллелепипед для MBR всех узлов, производных по отношению к данному. Childnode-pointer - это указатель на производные узлы.
Пусть M и m <= M/2 соответственно максимальное и мимимальное количество элементов, которое может быть размещено в узле. Тогда свойства R-дерева можно описать следующим образом:
|
|
|
- R-Tree является сильно сбалансированным деревом, т.е. все листья находятся на одном уровне.
- Корневой узел имеет, как минимум, двух потомков.
- Для каждого элемента (I, childnode-pointer) в неконцевом узле I является наименьшим возможным параллелепипедом, т.е. содержит все параллелепипеды производных узлов.
- Каждый концевой узел (лист) содержит от m до M индексных записей.
- Для каждой индексной записи (I, tuple-identifier) в концевом узле I является параллелепипедом, который содержит n -мерный объект данных, на который указывает tuple-identifier
Хеширование.
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского "to hash" - резать, измельчать). Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи организуются в виде таблицы, называемой хеш-таблицей.
Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов.
2.1.Представление данных с помощью модели "сущность-связь".
Назначение модели.
Прежде, чем приступать к созданию системы автоматизированной обработки информации, разработчик должен сформировать понятия о предметах, фактах и событиях, которыми будет оперировать данная система. Для того, чтобы привести эти понятия к той или иной модели данных, необходимо заменить их информационными представлениями. Одним из наиболее удобных инструментов унифицированного представления данных, независимого от реализующего его программного обеспечения, является модель "сущность-связь" (entity - relationship model, ER - model).
Модель "сущность-связь" основывается на некой важной семантической информации о реальном мире и предназначена для логического представления данных. Она определяет значения данных в контексте их взаимосвязи с другими данными. Важным для нас является тот факт, что из модели "сущность-связь" могут быть порождены все существующие модели данных (иерархическая, сетевая, реляционная, объектная), поэтому она является наиболее общей.
|
|
|
Отметим, что модель "сущность-связь" не является моделью данных в том смысле, как это было определено в параграфе 1.1.2, поскольку не определяет операций над данными и ограничивается описанием только их логической структуры.
Модель "сущность-связь" была предложена в 1976 г. Питером Пин-Шэн Ченом, русский перевод его статьи 'Модель "сущность-связь" - шаг к единому представлению данных' опубликован в журнале "СУБД" N 3 за 1995 г.
Элементы модели.
Любой фрагмент предметной области может быть представлен как множество сущностей, между которыми существует некоторое множество связей. Дадим определения:
Сущность (entity) - это объект, который может быть идентифицирован неким способом, отличающим его от других объектов. Примеры: конкретный человек, предприятие, событие и т.д.
Набор сущностей (entity set) - множество сущностей одного типа (обладающих одинаковыми свойствами). Примеры: все люди, предприятия, праздники и т.д. Наборы сущностей не обязательно должны быть непересекающимися. Например, сущность, принадлежащая к набору МУЖЧИНЫ, также принадлежит набору ЛЮДИ.
Сущность фактически представляет из себя множество атрибутов, которые описывают свойства всех членов данного набора сущностей.
Пример:
рассмотрим множество работников некого предприятия. Каждого из них можно описать с помощью характеристик табельный номер, имя, возраст. Поэтому, сущность СОТРУДНИК имеет атрибуты ТАБЕЛЬНЫЙ_НОМЕР, ИМЯ, ВОЗРАСТ. Используя нотацию языка Pascal этот факт можно представить как:
В дальнейшем для определения сущности и ее атрибутов будем использовать обозначение вида
СОТРУДНИК (ТАБЕЛЬНЫЙ_НОМЕР, ИМЯ, ВОЗРАСТ).
Например отделы,на которые подразделяется предприятие, и в которых работают сотрудники, можно описать как ОТДЕЛ(НОМЕР_ОТДЕЛА, НАИМЕНОВАНИЕ).
Множество значений (область определения) атрибута называется доменом. Например, для атрибута ВОЗРАСТ домен (назовем его ЧИСЛО_ЛЕТ) задается интервалом целых чисел больших нуля, поскольку людей с отрицательным возрастом не бывает.
В упомянутой статье П.Чена атрибут определяется как функция, отображающая набор сущностей в набор значений или в декартово произведение наборов значений. Так атрибут ВОЗРАСТ производит отображение в набор значений (домен) ЧИСЛО_ЛЕТ. Атрибут ИМЯ производит отображение в декартово произведение наборов значений ИМЯ, ФАМИЛИЯ и ОТЧЕСТВО.
|
|
|
Отсюда определяется ключ сущности - группа атрибутов, такая, что отображение набора сущностей в соответствующую группу наборов значений является взаимнооднозначным отображением. Другими словами: ключ сущности - это один или более атрибутов уникально определяющих данную сущность. В нашем примере ключем сущности СОТРУДНИК является атрибут ТАБЕЛЬНЫЙ_НОМЕР (конечно, только в том случае, если все табельные номера на предприятии уникальны).
Связь (relationship) - это ассоциация, установленная между несколькими сущностями. Примеры:
- поскольку каждый сотрудник работает в каком-либо отделе, между сущностями СОТРУДНИК и ОТДЕЛ существует связь "работает в" или ОТДЕЛ-РАБОТНИК;
- так как один из работников отдела является его руководителем, то между сущностями СОТРУДНИК и ОТДЕЛ имеется связь "руководит" или ОТДЕЛ-РУКОВОДИТЕЛЬ;
- могут существовать и связи между сущностями одного типа, например связь РОДИТЕЛЬ - ПОТОМОК между двумя сущностями ЧЕЛОВЕК;
(В скобках здесь следует отметить, что в методике проектирования данных есть своеобразное правило хорошего тона, согласно которому сущности обозначаются с помощью имен существительных, а связи - глагольными формами. Данное правило, однако, не является обязательным)
К сожалению, не существует общих правил определения, что считать сущностью, а что связью. В рассмотренном выше примере мы положили, что "руководит" - это связь. Однако, можно рассматривать сущность "руководитель", которая имеет связи "руководит" с сущностью "отдел" и "является" с сущностью "сотрудник".
Связь также может иметь атрибуты. Например, для связи ОТДЕЛ-РАБОТНИК можно задать атрибут СТАЖ_РАБОТЫ_В_ОТДЕЛЕ.
Роль сущности в связи - функция, которую выполняет сущность в данной связи. Например, в связи РОДИТЕЛЬ-ПОТОМОК сущности ЧЕЛОВЕК могут иметь роли "родитель" и "потомок". Указание ролей в модели "сущность-связь" не является обязательным и служит для уточнения семантики связи.
Набор связей (relationship set) - это отношение между n (причем n не меньше 2) сущностями, каждая из которых относится к некоторому набору сущностей.
Пример:
сущности наборы сущностей ---------- ---------------- e1 принадлежит E1 e2 принадлежит E2... en принадлежит En тогда [e1,e2,...,en] - набор связей RХотя, сторого говоря, понятия "связь" и "набор связей" различны (первая является элементом второго), их, тем не менее, очень часто смешивают. Поэтому, мы, не претендуя на академическую строгость, в дальнейшем также будем часто пользоваться терминами "связь" имея в виду "набор связей" и "сущность" имея в виду "набор сущностей".
В случае n=2, т.е. когда связь объединяет две сущности, она называется бинарной. Доказано, что n -арный набор связей (n>2) всегда можно заменить множеством бинарных, однако первые лучше отображают семантику предметной области.
То число сущностей, которое может быть ассоциировано через набор связей с другой сущностью, называют степенью связи. Рассмотрение степеней особенно полезно для бинарных связей. Могут существовать следующие степени бинарных связей:
- один к одному (обозначается 1: 1). Это означает, что в такой связи сущности с одной ролью всегда соответствует не более одной сущности с другой ролью. В рассмотренном нами примере это связь "руководит", поскольку в каждом отделе может быть только один начальник, а сотрудник может руководить только в одном отделе. Данный факт представлен на следующем рисунке, где прямоугольники обозначают сущности, а ромб - связь. Так как степень связи для каждой сущности равна 1, то они соединяются одной линией.

Другой важной характеристикой связи помимо ее степени является класс принадлежности входящих в нее сущностей или кардинальность связи. Так как в каждом отделе обязательно должен быть руководитель, то каждой сущности "ОТДЕЛ" непременно должна соответствовать сущность "СОТРУДНИК". Однако, не каждый сотрудник является руководителем отдела, следовательно в данной связи не каждая сущность "СОТРУДНИК" имеет ассоциированную с ней сущность "ОТДЕЛ".
Таким образом, говорят, что сущность "СОТРУДНИК" имеет обязательный класс принадлежности (этот факт обозначается также указанием интервала числа возможных вхождений сущности в связь, в данном случае это 1,1), а сущность "ОТДЕЛ" имеет необязательный класс принадлежности (0,1). Теперь данную связь мы можем описать как 0,1:1,1. В дальнейшем кардинальность бинарных связей степени 1 будем обозначать следующим образом:

- один ко многим (1: n). В данном случае сущности с одной ролью может соответствовать любое число сущностей с другой ролью. Такова связь ОТДЕЛ-СОТРУДНИК. В каждом отделе может работать произвольное число сотрудников, но сотрудник может работать только в одном отделе. Графически степень связи n отображается "древообразной" линией, так это сделано на следующем рисунке.

Данный рисунок дополнительно иллюстрирует тот факт, что между двумя сущностями может быть определено несколько наборов связей.
Здесь также необходимо учитывать класс принадлежности сущностей. Каждый сотрудник должен работать в каком-либо отделе, но не каждый отдел (например, вновь сформированный) должен включать хотя бы одного сотрудника. Поэтому сущность "ОТДЕЛ" имеет обязательный, а сущность "СОТРУДНИК" необязательный классы принадлежности. Кардинальность бинарных связей степени n будем обозначать так:
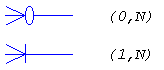
- много к одному (n: 1). Эта связь аналогична отображению 1: n. Предположим, что рассматриваемое нами предприятие строит свою деятельность на основании контрактов, заключаемых с заказчиками. Этот факт отображается в модели "сущность-связь" с помощью связи КОНТРАКТ-ЗАКАЗЧИК, объединяющей сущности КОНТРАКТ(НОМЕР, СРОК_ИСПОЛНЕНИЯ, СУММА) и ЗАКАЗЧИК(НАИМЕНОВАНИЕ, АДРЕС). Так как с одним заказчиком может быть заключено более одного контракта, то связь КОНТРАКТ-ЗАКАЗЧИК между этими сущностями будет иметь степень n: 1.

В данном случае, по совершенно очевидным соображениям (каждый контракт заключен с конкретным заказчиком, а каждый заказчик имеет хотя бы один контракт, иначе он не был бы таковым), каждая сущность имеет обязательный класс принадлежности.
- многие ко многим (n: n). В этом случае каждая из ассоциированных сущностей может быть представлена любым количеством экземпляров. Пусть на рассматриваемом нами предприятии для выполнения каждого контракта создается рабочая группа, в которую входят сотрудники разных отделов. Поскольку каждый сотрудник может входить в несколько (в том числе и ни в одну) рабочих групп, а каждая группа должна включать не менее одного сотрудника, то связь между сущностями СОТРУДНИК и РАБОЧАЯ_ГРУППА имеет степень n: n.

Если существование сущности x зависит от существования сущности y, то x называется зависимой сущностью (иногда сущность x называют "слабой", а "сущность" y - сильной). В качестве примера рассмотрим связь между ранее описанными сущностями РАБОЧАЯ_ГРУППА и КОНТРАКТ. Рабочая группа создается только после того, как будет подписан контракт с заказчиком, и прекращает свое существование по выполнению контракта. Таким образом, сущность РАБОЧАЯ_ГРУППА является зависимой от сущности КОНТРАКТ. Зависимую сущность будем обозначать двойным прямоугольником, а ее связь с сильной сущностью линией со стрелкой:

Заметим, что кардинальность связи для сильной сущности всегда будет (1,1). Класс принадлежности и степень связи для зависимой сущности могут быть любыми. Предположим, например, что рассматриваемое нами предприятие пользуется несколькими банковскими кредитами, которые представляются набором сущностей КРЕДИТ(НОМЕР_ДОГОВОРА,СУММА, СРОК_ПОГАШЕНИЯ, БАНК). По каждому кредиту должны осуществляться выплаты процентов и платежи в счет его погашения. Этот факт представляется набором сущностей ПЛАТЕЖ(ДАТА, СУММА) и набором связей "осуществляется по". В том случае, когда получение запланированного кредита отменяется, информация о нем должна быть удалена из базы даных. Соответственно, должны быть удалены и все сведения о плановых платежах по этому кредиту. Таким образом, сущность ПЛАТЕЖ зависит от сущности КРЕДИТ.

2.2.Диаграмма "сущность-связь".
Очень важным свойством модели "сущность-связь" является то, что она может быть представлена в виде графической схемы. Это значительно облегчает анализ предметной области. Существует несколько вариантов обозначения элементов диаграммы "сущность-связь", каждый из которых имеет свои положительные черты. Краткий обзор некоторых из этих нотаций будет сделан в параграфе 2.4. Здесь мы будем использовать некий гибрид нотаций Чена (обозначение сущностей, связей и атрибутов) и Мартина (обозначение степеней и кардинальностей связей). В таблице 2.1 приводится список используемых здесь обозначений.
Таблица 2.1
| Обозначение | Значение |

| Набор независимых сущностей |

| Набор зависимых сущностей |

| Атрибут |

| Ключевой атрибут |

| Набор связей |
Атрибуты с сущностями и сущности со связями соединяются прямыми линиями. При этом для указания кардинальностей связей используются обозначения, введенные в предыдущем параграфе.
В процессе построения диаграммы можно выделить несколько очевидных этапов:
- Идентификация представляющих интерес сущностей и связей.
- Идентификация семантической информации в наборах связей (например, является ли некоторый набор связей отображением 1:n).
- Определение кардинальностей связей.
- Определение атрибутов и наборов их значений (доменов).
- Организация данных в виде отношений "сущность-связь".
В качестве примера построим диаграмму, отображающую связь данных для подсистемы учета персонала предприятия.
Выделим интересующие нас сущности и связи:
- Прежде всего преприятие состоит из отделов, в которых работают сотрудники. Оклад каждого сотрудника зависит от занимаемой им должности (инженер, ведущий инженер, бухгалтер, уборщик и т.д.). Далее предположим, что на нашем предприятии допускается совместительство должностей, т.е. каждый сотрудник может иметь более чем одну должность (и работать более чем в одном отделе), причем может занимать неполную ставку. В то же время, одну и ту же должность могут занимать одновременно несколько сотрудников. В результате этих рассуждений мы должны ввести наборы сущностей
- ОТДЕЛ(ИМЯ_ОТДЕЛА),
- СОТРУДНИК(ТАБЕЛЬНЫЙ_НОМЕР, ИМЯ),
- ДОЛЖНОСТЬ(ИМЯ_ДОЛЖНОСТИ, ОКЛАД),
и и набор связей РАБОТАЕТ_В с атрибутом ставка между ними. Атрибут ставка может принимать значения из интервала ]0,1] (больше нуля, но меньше или равен единице), он определяет какую часть должностного оклада получает данный сотрудник.

Как уже отмечалось выше, каждый n -арный набор связей можно заменить несколькими бинарными наборами. Сейчас как раз представляется удобный случай, чтобы оценить преимущества каждого из этих способов представления связей.
- Тренарная связь, показанная здесь, безусловно несет более полную информацию о предметной области. Действительно, она однозначно отображает тот факт, что оклад сотрудника зависит от его должности, отдела, где он работает, и ставки. Однако, в этом случае возникают некоторые проблемы с определением степени связи. Хотя, как было сказано, каждый работник может занимать несколько должностей, а в штате каждого отдела существуют вакансии с различными должностями, тем не менее класс принадлежности сущности ДОЛЖНОСТЬ на приведенном рисунке установлен в (1,1). Это объясняется тем, что ДОЛЖНОСТЬ ассоциируется фактически не с сущностями СОТРУДНИК и ОТДЕЛ, а со связью между ними. Обозначать этот факт предлагается так, как это показано на следующей диаграмме:

Здесь сущности СОТРУДНИК, ОТДЕЛ и связь РАБОТАЕТ_В аггрегируются в некую новую абстрактную сущность, которая ассоциируется с сущностью ДОЛЖНОСТЬ с помощью связи степени n:1. (Это обозначение заимствовано из книги Silberschatz, Korth and Sudarshan Database System Concepts, 1997).
- Попытаемя отобразить ассоциации сотрудников, отделов и должностей с помощью бинарных связей.

В этом случае для адекватного описания семантики предметной области необходимо ввести еще одну сущность ШТАТНАЯ_ЕДИНИЦА, которая фактически заменяет собой связь РАБОТАЕТ_В в абстрактной сущности и поэтому имеет атрибут ставка.
Переход от n -арной связи через аггрегацию сущностей к набору бинарных связей можно рассматривать как последовательные этапы одного процесса, который приводит к однозначному порождению реляционной модели данных. При построении диаграммы "сущность- связь" можно использовать любой из этих трех способов представления данных.
- Перечисли ряд объектов, описанных в предыдущем праграфе, которые будут полезны при моделировании данных рассматриваемого предприятия. Им соответствуют следующие сущности:
- ЗАКАЗЧИК(ИМЯ_ЗАКАЗЧИКА,АДРЕС)
- КОНТРАКТ(НОМЕР,СРОК_НАЧАЛА,СРОК_ОКОНЧАНИЯ,СУММА)
- РАБОЧАЯ ГРУППА(ПРОЦЕНТ_ВОЗНАГРАЖДЕНИЯ)
Атрибут "процент_вознаграждения" отражает ту долю стоимости контракта, которая предназначена для оплаты труда членов соответствующей рабочей группы. Смысл остальных атрибутов понятен без дополнительных пояснений. Связи между перечисленными сущностями также описаны в предыдущем параграфе.
Как правило, один из членов рабочей группы является руководителем по отношению к другим сотрудникам, входящим в ее состав. Для отражения этого факта мы должны ввести связь "руководит" с кардинальностью 1,1:0,n между сущностями СОТРУДНИК и РАБОЧАЯ_ГРУППА (сотрудник может руководить в произвольном числе рабочих групп, но каждая рабочая группа имеет одного и только одного руководителя).
- Рассмотрим теперь более внимательно информационный объект "заказчик". На практике очень часто возникает необходимость различать национальную прнадлежность юридических лиц, с которыми предприятие вступает в договорные отношения. Это свзано с тем, что для зарубежных фирм необходимо хранить, например, сведения о валюте, в которой осуществляются расчеты, языке, на котором подписан котракт и т.д. В свою очередь, для отечественных компаний необходимо иметь сведения о их форме собственности (частная или государственная), поскольку от этого может зависеть порядок налогообложения средств, полученных за выполнение работ по контракту.
Таким образом, мы приходим к выводу, что необходимо ввести в рассмотрение еще два непересекающихся множества ЗАРУБЕЖНОЕ_ПРЕДПРИЯТИЕ(ВАЛЮТА, ЯЗЫК) и ОТЕЧЕСТВЕННОЕ_ПРЕДПРИЯТИЕ(ФОРМА_СОБСТВЕННОСТИ), объединение которых составляет полное множество ЗАКАЗЧИК. Ассоциацию между этими объектами называют отношением наследования или иерархической связью, так как сущности ЗАРУБЕЖНОЕ_ПРЕДПРИЯТИЕ и ОТЕЧЕСТВЕННОЕ_ПРЕДПРИЯТИЕ наследуют атрибуты сущности ЗАКАЗЧИК(ИМЯ_ЗАКАЗЧИКА, АДРЕС). Для того, чтобы определить к какому подмножеству относится конкретная сущность из набора ЗАКАЗЧИК (и, соответственно, какой набор атрибутов она имеет) необходимо ввести атрибут "национальная принадлежность", называемый дискриминантом. Этот тип связи предлагается отображать на диаграмме следующим образом:

Обобщая все проведенные выше рассуждения, получим диаграму "сущность-связь", показанную на слудющем рисунке.

В заключение этого раздела читателю предлагается несколько вопросов для самостоятельной проработки:
- Как изменится диаграмма "сущность - связь" в том случае, если процент вознаграждения по всем контрактам будет одинаков?
- Что изменится в диаграмме, если будет запрещено совместительство должностей, т.е. каждый сотрудник будет иметь право занимать только одну должность со ставкой 1?
Ответы:
- В первом случае отпадает необходимость в сущности РАБОЧАЯ_ГРУППА. Все ее связи перейдут к сущности КОНТРАКТ.
- Во втором случае связь "занимает" не будет иметь атрибутов. При декомпозиции ее на бинарные связи получим сущность ШТАТНАЯ_ЕДИНИЦА, также не имеющую атрибутов.
Целостность данных.
Модель "сущность-связь" также полезна для понимания и спецификации ограничений, направленных на поддержание целостности данных. В модели имеется три типа ограничений на значения:
- ограничения на допустимые значения в наборе значений (домене). Домен можно трактовать как область определения атрибута, которая может быть задана либо непрерывным или дискретным интервалом, либо фиксированным списком значений.
- ограничения на разрешенные значения для каждого атрибута. Например, возраст сотрудников может быть ограничен интервалом от 18 до 65 лет.
- ограничения на существующие значения в базе данных. Например, сумма отчислений с зарплаты сотрудника не должна превышать самой зарплаты.
2.4.Обзор нотаций, используемых при построении диаграмм "сущность-связь"
Нотация Чена.
| Элемент диаграммы | Обозначает |

| независимая сущность |

| зависимая сущность |

| родительская сущность в иерархической связи |

| Связь |

| идентифицирующая связь |

| Атрибут |

| первичный ключ |

| внешний ключ (понятие внешнего ключа вводится в реляционной модели данных) |

| многозначный атрибут |

| получаемый (наследуемый) атрибут в иерархических связях |
Связь соединяется с ассоциируемыми сущностями линиями. Возле каждой сущности на линии, соединяющей ее со связью, цифрами указывается класс принадлежности. Пример:

Нотация Мартина
| Элемент диаграммы | Обозначает |
|
| независимая сущность |
|
| зависимая сущность |
|
| родительская сущность в иерархической связи |
Список атрибутов приводится внутри прямоугольника, обозначающего сущность. Ключевые атрибуты подчеркиваются. Связи изображаются линиями, соединяющими сущности, вид линии в месте соединения с сущностью определяет кардинальность связи:
| Обозначение | Кардинальность |

| нет |

| 1,1 |

| 0,1 |

| M,N |

| 0,N |

| 1,N |
Имя связи указывается на линии ее обозначающей. Пример:

Нотация IDEF1X.
Обозначения сущностей:
| Элемент диаграммы | Обозначает |
|
| независимая сущность |

| зависимая сущность |
Список атрибутов приводится внутри прямоугольника, обозначающего сущность. Атрибуты, составляющие ключ сущности, группируются в верхней части прямоугольника и отделяются горизонтальной чертой.
Обозначения связей:
| Элемент диаграммы | Обозначает |
|
| идентифицирующая связь |

| неидентифицирующая связь> |
Обозначение кардинальности связей:
| Элемент диаграммы | Обозначает |
|
| 1,1 |

| 0,M |

| 0,1 |

| 1,M |

| точно N (N - произвольное число) |
Пример:

Кроме того, в IDEF1X вводится понятие “отношение категоризации”, по смыслу эквивалентное рассмотренной нами иерархической связи. Отношение полной категоризации (сущности-категории составляют полное множество потомков родительской сущности) обозначается:

Также может существовать отношение неполной категоризации (сущности-категории составляют неполное множество потомков общей сущности):

Нотация Баркера.
Сущности обозначаются прямоугольниками, внутри которых приводится список атрибутов. Ключевые атрибуты отмечаются символом # (решетка). Связи обозначаются линиями с именами, место соединения связи и сущности определяет кардинальность связи:
| Обозначение | Кардинальность |
|
| 0,1 |
|
| 1,1 |

| 0,N |

| 1,N |
Пример:

Для обозначения отношения категоризации вводится элемент "дуга":

|
|
|
