 |


Пример эконометрического исследования
|
|
|
|
На основе статистических данных по показателям влияния уровня средней заработной платы и индекса потребительских цен на уровень бедности населения 1998 по 2015 год проводится эконометрическое исследования в соответствие с методикой п.2.1(таблица 1).
Таблица 1
Зависимость показателя уровня бедности от средней заработной платы и индекса потребительских цен в России (источник Росстат)
| Годы | Средняя заработная плата, руб. | Индекс потребителских цен, % | Численность населения с денежными доходами ниже величины прожиточного минимума, млн. чел. |
| 101,51 | 34,3 | ||
| 108,38 | 41,6 | ||
| 102,33 | 42,3 | ||
| 102,76 | 40,0 | ||
| 103,09 | 35,6 | ||
| 102,4 | 29,3 | ||
| 101,75 | 25,2 | ||
| 102,62 | 25,4 | ||
| 102,43 | 21,6 | ||
| 101,68 | 18,8 | ||
| 102,31 | 19,0 | ||
| 102,37 | 18,4 | ||
| 101,64 | 17,7 | ||
| 102,37 | 17,9 | ||
| 100,5 | 15,4 | ||
| 100,97 | 15,5 | ||
| 100,59 | 16,1 | ||
| 104,11 | 19,2 |
Представление исходных данных в MS Excel представлено в таблице 2.
Таблица 2
Представление исходных данных в MS Excel

1. Спецификация модели уравнения регрессии включает графический анализ корреляционной зависимости зависимой переменной (х1 – средняя заработная плата, х2 – индекс потребительских цен) от каждой объясняющей переменной (у – уровень бедности, численность населения с денежными доходами ниже величины прожиточного минимума).
Исходные данные представим графически (Рисунок 1, 2).
> 
Рисунок 1. Уровень бедности от Х1 (средняя заработная плата)

Рисунок 2. Уровень бедности от Х2 (индекса потребительских цен, %)
2. Параметризация уравнения регрессии.
Результаты регрессионного анализа представлены на рисунке 3.

Рисунок 3. Результаты регрессионного анализа
|
|
|
Искомое уравнение имеет вид
У= -116,47-0,0063х1 +1,472 х2+ е.
Коэффициент 0,0063 показывает, что при снижении заработной платы на 1 усл.ед уровень бедности увеличивается в среднем на 0,0063усл.ед.
Коэффициент 1,472 показывает, что при росте индекса цен 1 усл.ед уровень бедности увеличивается в среднем на 1,472 усл.ед.
3. Верификация уравнения регрессии проводится на основе результатов автоматизированного регрессионного анализа по следующим показателям: «R-квадрат», «Значимость F», «P-значение» (по каждому параметру регрессии), а также по графикам подбора и остатков.
Значимость коэффициентов полученной модели проверяется по t-тесту:
Р-значение (b0)= 0,141>0,05;
Р-значение (b1)= 0,000001 < 0,05;
Р-значение (b2)= 0,060602>0,05.
При этом b0 и b2 не значимы, что не считается критически с точки зрения качества модели.
Следовательно, коэффициенты значимы при 5% уровне значимости. Таким образом, коэффициенты регрессии значимы и модель адекватна исходным данным.
Качество модели оценивается коэффициентом детерминации R2. Величина R2= 0,7762 означает, что факторами средней заработной платы и индексом потребительских цен можно объяснить 77,62% вариации (разброса) показателя уровня бедности населения.
Значимость R2 проверяется по F – тесту:
Значимость F= 0,000001< 0,05.
Следовательно, R2 значим при 5%-ном уровне значимости.
Отклонения (остатки) e и графический анализ остатков представлен на следующих рисунках:

Рисунок 4. Графическое изображение остатков по наблюдениям
Из рисунка 4 видно: что есть нелинейная зависимость в остатках.
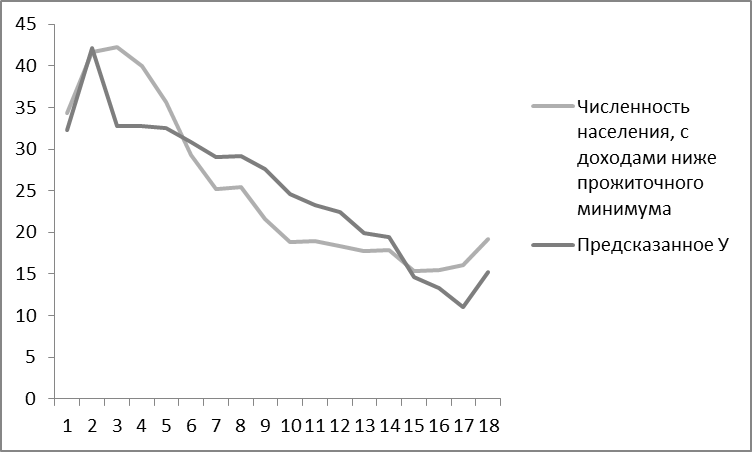
Рисунок 5. Графическое изображение фактических и предсказанных данных
Из рисунка 5 видно: частое пересечение Y и Y^

Рисунок 6. Анализ характера зависимости между остатками и предыдущими значениям
Из рисунка 6 в видно: что есть нелинейная зависимость между остатками и предыдущими значениям

Рисунок 7. Анализ остатков от предсказанного У
|
|
|
Из рисунка 7 видно: добавленные линии тренда на графиках имеют несущественный наклон, поэтому можно предположить отсутствие проблем гетероскедастичности.
Анализ наличия автокорреляции остатков проводится по тесту Дарбина-Уотсона. Для вычисления статистики Дарбина-Уотсона необходимы следующие данные, которые представлены в таблице 3.
Искомое уравнение имеет виду У= 116,47-0,0063х1 +1,472 х2+ е.
Таблица 3
Анализ наличия автокорреляции остатков проводится по тесту Дарбина-Уотсона
| t | X1 | X2 | y | et | et-1 | et ^2 | (et-et-1)^2 |
| 101,51 | 34,3 | 1,9722 | - | 3,8896 | - | ||
| 108,38 | 41,6 | -0,5446 | 1,9722 | 0,2966 | 6,3343 | ||
| 102,33 | 42,3 | 9,5071 | -0,5446 | 90,3850 | 101,0367 | ||
| 102,76 | 40,0 | 7,2181 | 9,5071 | 52,1010 | 5,2395 | ||
| 103,09 | 35,6 | 3,0416 | 7,2181 | 9,2513 | 17,4432 | ||
| 102,4 | 29,3 | -1,5210 | 3,0416 | 2,3134 | 20,8173 | ||
| 101,75 | 25,2 | -3,8779 | -1,5210 | 15,0381 | 5,5550 | ||
| 102,62 | 25,4 | -3,8093 | -3,8779 | 14,5108 | 0,0047 | ||
| 102,43 | 21,6 | -6,0127 | -3,8093 | 36,1526 | 4,8550 | ||
| 101,68 | 18,8 | -5,8341 | -6,0127 | 34,0367 | 0,0319 | ||
| 102,31 | 19,0 | -4,2201 | -5,8341 | 17,8092 | 2,6050 | ||
| 102,37 | 18,4 | -4,0547 | -4,2201 | 16,4406 | 0,0274 | ||
| 101,64 | 17,7 | -2,2141 | -4,0547 | 4,9022 | 3,3878 | ||
| 102,37 | 17,9 | -1,5581 | -2,2141 | 2,4277 | 0,4303 | ||
| 100,5 | 15,4 | 0,7603 | -1,5581 | 0,5781 | 5,3750 | ||
| 100,97 | 15,5 | 2,1716 | 0,7603 | 4,7158 | 1,9918 | ||
| 100,59 | 16,1 | 5,0432 | 2,1716 | 25,4339 | 8,2461 | ||
| 104,11 | 19,2 | 3,9325 | 5,0432 | 15,4646 | 1,2337 | ||
| Итого | - | - | - | - | - | 345,7471 | 184,6145 |
Результаты вычислений в МS Eхсel представлены на рисунке 8.

Рисунок 8. Результаты вычислений в МS Eхсel
Предыдущие остатки и остатки в квадрате графически изображены на рисунке 9.

Рисунок 9. Предыдущие остатки

Рисунок 10. Остатки в квадрате
 DW= 184,6145/345,7471 = 0,5340.
DW= 184,6145/345,7471 = 0,5340.
По таблице распределения Дарбина-Уотсона находим
d1 =1,16 и d2 = 1,39.
Получаем соотношение 1,16<0,5340<4-1.39 (=2.61)
Поскольку d2 < DW < 4- d2, то нет оснований отклонять гипотезу Н 0 об отсутствии автокорреляции в остатках.
Следовательно, уравнение степенной регрессии имеет вид
У= 1496,78+4,33х1 +0,01 х2+ е., характеризуется высоким качеством и отсутствием проблем в остатках и может быть использована при предсказании исходных данных.
Для анализа модели на гетероскедастичность по тесту ранговой корреляции Спирмена необходимы следующие данные (таблицы 4-5).
Таблица 4
Расчет для х1
| t | X1 | Ранг | et | Ранг | D | D2 |
| 1,9722 | ||||||
| 0,5446 | -1 | |||||
| 9,5071 | ||||||
| 7,2181 | ||||||
| 3,0416 | ||||||
| 1,5210 | -3 | |||||
| 3,8779 | ||||||
| 3,8093 | ||||||
| 6,0127 | ||||||
| 5,8341 | ||||||
| 4,2201 | ||||||
| 4,0547 | ||||||
| 2,2141 | -6 | |||||
| 1,5581 | -10 | |||||
| 0,7603 | -13 | |||||
| 2,1716 | -10 | |||||
| 5,0432 | -3 | |||||
| 3,9325 | -7 | |||||
| Итого |
|
|
|
На основе этих данных вычислен коэффициент ранговой корреляции:

Тестовая статистика составляет

Коэффициент ранговой корреляции меньше, чем /tкр/, и следовательно, нулевая гипотеза об отсутствии гетероскедастичности не отклоняется.
Таблица 4
Расчет для х2
| t | X2 | Ранг | et | Ранг | D | D2 |
| 101,51 | 1,9722 | -14 | ||||
| 108,38 | 0,5446 | |||||
| 102,33 | 9,5071 | -7 | ||||
| 102,76 | 7,2181 | |||||
| 103,09 | 3,0416 | |||||
| 102,4 | 1,5210 | -1 | ||||
| 101,75 | 3,8779 | -5 | ||||
| 102,62 | 3,8093 | |||||
| 102,43 | 6,0127 | |||||
| 101,68 | 5,8341 | -3 | ||||
| 102,31 | 4,2201 | |||||
| 102,37 | 4,0547 | |||||
| 101,64 | 2,2141 | -1 | ||||
| 102,37 | 1,5581 | |||||
| 100,5 | 0,7603 | -3 | ||||
| 100,97 | 2,1716 | |||||
| 100,59 | 5,0432 | |||||
| 104,11 | 3,9325 | |||||
| Итого |
На основе этих данных вычислен коэффициент ранговой корреляции:

Тестовая статистика составляет

Коэффициент ранговой корреляции меньше, чем /tкр/, и следовательно, нулевая гипотеза об отсутствии гетероскедастичности не отклоняется.
2. Дополнительное исcледование предполагает прогнозирование исходных данных.
Рекомендуется проводить ретроспективный прогноз, для прогнозирования берется последняя 1/3 наблюдений.
Точечный прогноз.
На данном этапе прогнозируются значения Yэмп. по модели. Так как проводится ретроспективный прогноз, фактические значения факторных переменных и предсказанные по ним значения зависимой переменной (последняя 1/3) будут считаться прогнозными.
|
|
|
С помощью инструмента Microsoft Excel «График» строится график фактических и предсказанных значений зависимой переменной по наблюдениям, делается вывод о близости фактических значений к предсказанным значениям в прогнозном периоде.

Рисунок 11. Данные точечного прогноза
Таблица 5
Прогнозные значения факторных переменных
| № П/П | Х1 | Х2 | У |
| 101,51 | 34,3 | ||
| 108,38 | 41,6 | ||
| 102,33 | 42,3 | ||
| 102,76 | 40,0 | ||
| 103,09 | 35,6 | ||
| 102,4 | 29,3 | ||
| 101,75 | 25,2 | ||
| 102,62 | 25,4 | ||
| 102,43 | 21,6 | ||
| 101,68 | 18,8 | ||
| 102,31 | 19,0 | ||
| 102,37 | 18,4 | ||
| 101,64 | 17,7 | ||
| 102,37 | 17,9 | ||
| 100,5 | 15,4 | ||
| 100,97 | 15,5 | ||
| 100,59 | 16,1 | ||
| 104,11 | 19,2 | ||
| 101,33 | 13,60 | ||
| 101,04 | 12,63 | ||
| 101,31 | 11,95 | ||
| 101,21 | 11,45 |
Далее для сравнения добавляются фактические значения.
Таблица 6
Анализ прогнозных и фактических значений
| № П/П | Х1 | Х2 | У прогн | У |
| 101,51 | 32,3 | 34,3 | ||
| 108,38 | 42,1 | 41,6 | ||
| 102,33 | 32,8 | 42,3 | ||
| 102,76 | 32,8 | 40,0 | ||
| 103,09 | 32,6 | 35,6 | ||
| 102,4 | 30,8 | 29,3 | ||
| 101,75 | 29,1 | 25,2 | ||
| 102,62 | 29,2 | 25,4 | ||
| 102,43 | 27,6 | 21,6 | ||
| 101,68 | 24,6 | 18,8 | ||
| 102,31 | 23,2 | 19,0 | ||
| 102,37 | 22,5 | 18,4 | ||
| 101,64 | 19,9 | 17,7 | ||
| 102,37 | 19,5 | 17,9 | ||
| 100,5 | 14,6 | 15,4 | ||
| 100,97 | 13,3 | 15,5 | ||
| 100,59 | 11,1 | 16,1 | ||
| 104,11 | 15,3 | 19,2 | ||
| 101,33 | 11,15 | 13,60 | ||
| 101,04 | 9,09 | 12,63 | ||
| 101,31 | 7,84 | 11,95 | ||
| 101,21 | 6,04 | 11,45 |

Рисунок 12. Фактические и прогнозные данные
Согласно рисунку 12, прогноз сохраняет возрастающую тенденцию, а также все прогнозные значения близки к фактическим.
Стандартные ошибки для интервального прогноза определяются с помощью фиктивных переменных Салкевера, причем количество фиктивных переменных равно количеству прогнозных периодов (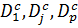 ), где p – количество прогнозных периодов,
), где p – количество прогнозных периодов,  =1, при условии, что данная переменная отвечает за первый прогнозный шаг, в противном случае, она равна нулю.
=1, при условии, что данная переменная отвечает за первый прогнозный шаг, в противном случае, она равна нулю.
Таблица 7
Стандартные ошибки для интервального прогноза определяются с помощью фиктивных переменных Салкевера
| № П/П | Х1 | Х2 | D1 | D2 | D3 | D4 | У |
| 101,51 | 34,3 | ||||||
| 108,38 | 41,6 | ||||||
| 102,33 | 42,3 | ||||||
| 102,76 | 40,0 | ||||||
| 103,09 | 35,6 | ||||||
| 102,4 | 29,3 | ||||||
| 101,75 | 25,2 | ||||||
| 102,62 | 25,4 | ||||||
| 102,43 | 21,6 | ||||||
| 101,68 | 18,8 | ||||||
| 102,31 | 19,0 | ||||||
| 102,37 | 18,4 | ||||||
| 101,64 | 17,7 | ||||||
| 102,37 | 17,9 | ||||||
| 100,5 | 15,4 | ||||||
| 100,97 | 15,5 | ||||||
| 100,59 | 16,1 | ||||||
| 104,11 | 19,2 | ||||||
| 101,33 | 13,60 | ||||||
| 101,04 | 12,63 | ||||||
| 101,31 | 11,95 | ||||||
| 101,21 | 11,45 |
|
|
|
Результат регрессии

Рисунок 13 Результат регрессии
Тогда стандартная ошибка коэффициента при фиктивной переменной равна стандартной ошибке предсказания (Si):
Для периода 19 – 5,33
для периода 20 – 5,44
для периода 21 – 5,57
для периода 22 – 5,70
Полученные стандартные ошибки коэффициентов при фиктивных переменных Салкевера равны стандартным ошибкам прогноза (Sпрj). Границы интервального прогноза рассчитываются по следующим формулам:
Yminn+j = Yэмп.n+j-Sпрj*tкр,
Ymaxn+j = Yэмп.n+j+Sпрj*tкр,
где tкр. - критическая точка распределения Стьюдента, определяемая по формуле СТЬЮДРАСПОБР(0,05;n-m-1), Yэмп.n+j – предсказанные значения в j прогнозном периоде
t крит=2,262
Таблица 8
Стандартные ошибки
| № П/П | У прогн | Уэмп | Sпрогн | У min | Уmax |
| 32,3 | 34,3 | ||||
| 42,1 | 41,6 | ||||
| 32,8 | 42,3 | ||||
| 32,8 | 40,0 | ||||
| 32,6 | 35,6 | ||||
| 30,8 | 29,3 | ||||
| 29,1 | 25,2 | ||||
| 29,2 | 25,4 | ||||
| 27,6 | 21,6 | ||||
| 24,6 | 18,8 | ||||
| 23,2 | 19,0 | ||||
| 22,5 | 18,4 | ||||
| 19,9 | 17,7 | ||||
| 19,5 | 17,9 | ||||
| 14,6 | 15,4 | ||||
| 13,3 | 15,5 | ||||
| 11,1 | 16,1 | ||||
| 15,3 | 19,2 | ||||
| 11,15 | 13,60 | 5,33 | 5,82 | 16,48 | |
| 9,09 | 12,63 | 5,44 | 3,65 | 14,53 | |
| 7,84 | 11,95 | 5,57 | 2,27 | 13,41 | |
| 6,04 | 11,45 | 5,70 | 0,34 | 11,74 |
Далее с помощью инструмента Microsoft Excel «График» строится график по фактическим и предсказанным значениям результативной переменной, верхним и нижним границам прогноза по наблюдениям (рис.12).
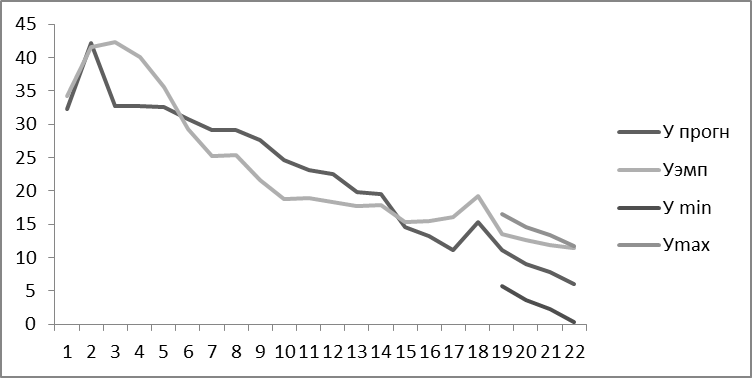
Рисунок 14. Границы прогноза
Согласно графику, прогнозные значения вписываются в границы интервального прогноза, что говорит о хорошем качестве прогноза.
Для оценки точности и надежности прогноза рассчитываются следующие показатели:
Абсолютная ошибка прогноза (Δ*абс) определяется как разность между эмпирическими и прогнозными значениями признака и вычисляется по формуле:
 ,
,
где:  - прогнозное значение зависимой переменной,
- прогнозное значение зависимой переменной,
уt - фактическое значение зависимой переменной.
Таблица 9
Расчет абсолютной ошибки прогноза
| № П/П | У прогн | Уэмп | D |
| 32,3 | 34,3 | ||
| 42,1 | 41,6 | -0,5 | |
| 32,8 | 42,3 | 9,5 | |
| 32,8 | 40,0 | 7,2 | |
| 32,6 | 35,6 | ||
| 30,8 | 29,3 | -1,5 | |
| 29,1 | 25,2 | -3,9 | |
| 29,2 | 25,4 | -3,8 | |
| 27,6 | 21,6 | -6 | |
| 24,6 | 18,8 | -5,8 | |
| 23,2 | 19,0 | -4,2 | |
| 22,5 | 18,4 | -4,1 | |
| 19,9 | 17,7 | -2,2 | |
| 19,5 | 17,9 | -1,6 | |
| 14,6 | 15,4 | 0,8 | |
| 13,3 | 15,5 | 2,2 | |
| 11,1 | 16,1 | ||
| 15,3 | 19,2 | 3,9 | |
| Итого |
Относительная ошибка прогноза (d*отн) может быть определена как отношение абсолютной ошибки прогноза (Δ*):
а) к фактическому значению зависимой переменной (уt):
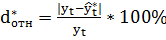 .
.
б) к прогнозному значению зависимой переменной ( :
:
 .
.
Таблица 10
Относительная ошибка прогноза
| № П/П | У прогн | Уэмп | У2 | {D} | {D}2 | 
|
| 32,3 | 34,3 | 1176,49 | 0,1166 | |||
| 42,1 | 41,6 | 1730,56 | 0,5 | 0,25 | 0,0060 | |
| 32,8 | 42,3 | 1789,29 | 9,5 | 90,25 | 2,1336 | |
| 32,8 | 40,0 | 7,2 | 51,84 | 1,2960 | ||
| 32,6 | 35,6 | 1267,36 | 0,2528 | |||
| 30,8 | 29,3 | 858,49 | 1,5 | 2,25 | 0,0768 | |
| 29,1 | 25,2 | 635,04 | 3,9 | 15,21 | 0,6036 | |
| 29,2 | 25,4 | 645,16 | 3,8 | 14,44 | 0,5685 | |
| 27,6 | 21,6 | 466,56 | 1,6667 | |||
| 24,6 | 18,8 | 353,44 | 5,8 | 33,64 | 1,7894 | |
| 23,2 | 19,0 | 4,2 | 17,64 | 0,9284 | ||
| 22,5 | 18,4 | 338,56 | 4,1 | 16,81 | 0,9136 | |
| 19,9 | 17,7 | 313,29 | 2,2 | 4,84 | 0,2734 | |
| 19,5 | 17,9 | 320,41 | 1,6 | 2,56 | 0,1430 | |
| 14,6 | 15,4 | 237,16 | 0,8 | 0,64 | 0,0416 | |
| 13,3 | 15,5 | 240,25 | 2,2 | 4,84 | 0,3123 | |
| 11,1 | 16,1 | 259,21 | 1,5528 | |||
| 15,3 | 19,2 | 368,64 | 3,9 | 15,21 | 0,7922 | |
| Итого | - | - | 12960,91 | 67,2 | 344,42 | 13,4672 |
Средняя абсолютная ошибка прогноза ( ), которая определяется как средняя арифметическая простая из абсолютных ошибок прогноза по формуле вида:
), которая определяется как средняя арифметическая простая из абсолютных ошибок прогноза по формуле вида:
 ,
,
где: n – объем выборки.

Средняя квадратическая ошибка прогноза, определяемая по формуле:
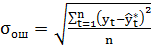 ,
,
(в знаменателе (n-m-1), m- число параметров модели). Средняя квадратическая ошибка показывает величину возможного отклонения полученной в результате выборки средней арифметической от такой же средней по всей совокупности.
 =26,83
=26,83
Средняя ошибка аппроксимации рассчитывается по формуле:
 .
.
Данный показатель является относительным показателем точности прогноза и не отражает размерность изучаемых признаков, выражается в процентах и на практике используется для сравнения точности прогнозов полученных как по различным моделям, так и по различным объектам. Интерпретация оценки точности: < 10% - высокая; 10% - 20% - хорошая; 20% - 50% - удовлетворительная; > 50% - не удовлетворительная.
Модель обладает достаточно высокой точности, так как интерпретация оценки точности: < 10%.
Коэффициент несоответствия рассчитывается по формуле:
 .
.
Интерпретация: КН1=0 при полном совпадении фактических и прогнозных значений; прогноз положительный
 .
.
Таким образом, методика успешно апробирована, может быть рекомендована для подобных исследований.
ЗАКЛЮЧЕНИЕ
В курсовом проекте на основе статистических данных по показателям валового внутреннего продукта и чистых налогов на производство и импорт проводилось эконометрическое исследование на предмет установления взаимосвязи между изучаемыми явлениями.
Спецификация модели уравнения регрессии включает графический анализ корреляционной зависимости зависимых переменных (х) от каждой объясняющей переменной (у).
Согласно представленным графически данным можно предположить прямую линейную зависимость, т.е. рост заработной платы способствует снижению бедности населения, и наоборот, с рост цен количество людей с доходами ниже прожиточного минимума возрастает.
В результате модель уравнения регрессии имеет
У= -116,47-0,0063х1 +1,472 х2+ е.
Коэффициент 0,0063 показывает, что при снижении заработной платы на 1 усл.ед уровень бедности увеличивается в среднем на 0,0063усл.ед.
Коэффициент 1,472 показывает, что при росте индекса цен 1 усл.ед уровень бедности увеличивается в среднем на 1,472 усл.ед.
Значимость коэффициентов полученной модели проверяется по t-тесту:
Р-значение (b0)= 0,141>0,05;
Р-значение (b1)= 0,000001 < 0,05;
Р-значение (b2)= 0,060602>0,05.
При этом b0 и b2 не значимы, что не считается критически с точки зрения качества модели.
Следовательно, коэффициенты значимы при 5% уровне значимости. Таким образом, коэффициенты регрессии значимы и модель адекватна исходным данным.
Качество модели оценивается коэффициентом детерминации R2. Величина R2= 0,7762 означает, что факторами средней заработной платы и индексом потребительских цен можно объяснить 77,62% вариации (разброса) показателя уровня бедности населения.
Значимость R2 проверяется по F – тесту:
Значимость F= 0,000001< 0,05.
Следовательно, R2 значим при 5%-ном уровне значимости.
Графический анализ остатков показал, что добавленные линии тренда на графиках имеют несущественный наклон.
Анализ остатков на наличие проблем автокореляции и гетероскедастичности, с использованием тестов Дарбина-Уотсона и Спирмена,соответственно, показали отсутствие проблем автокорреляции остатков, но наличие их гетероскедастичности.
Следовательно, полученное уравнение характеризуется высоким качеством и отсутствием проблем в остатках и может быть использована при планировании исходных данных.
Результаты показали, что средняя заработная плата будет расти, следовательно, уменьшается уровень бедности на прогнозный период.
Таким образом, разработанное информационно-методическое обеспечение апробировано и может быть рекомендовано для практического применения при аналогичных эконометрических исследованиях.
|
|
|
