 |


Поиск и чтение записи с заданным значением ключа
|
|
|
|
Читается верхний индекс. Сравниваем заданное значение ключа со значением ключа записей индекса. Если заданное значение ключа больше, чем значение ключа очередной записи индекса (если такая запись имеется), или равно ему, то по адресу связи, указанному в текущей записи, читается блок записей индекса следующего уровня. Далее процесс повторяется.
Считаем, что все блоки расположены в ВП. Тогда число обращений к ВП при поиске информации будет равно числу уровней дерева. Число уровней дерева равно минимальному значению l, при котором выполняется условие kl ≥ N (N – число логических записей).
Модификация (корректировка) записи
После поиска и чтения записи изменяются корректируемые поля. Если корректируется не ключ записи, то измененная запись заносится на свое место. Если изменено значение ключа, то старая запись удаляется (в соответствующем блоке появляется «пустая» запись), а измененная запись заносится так же, как вновь добавляемая.
Удаление записи
После поиска найденная запись удаляется (в соответствующий блок на место этой записи заносится «пустая» запись).
Добавление записи
Прежде всего определяется, где должна быть расположена добавляемая запись с заданным значением ключа. Процедура поиска блока, где должна быть расположена эта запись, аналогична вышеописанной процедуре поиска записей с заданным значением ключа. Если в найденном блоке низшего уровня есть «пустая» запись, добавляемая запись заносится в этот блок (с необходимым переупорядочением записей внутри блока).
Если в соответствующем блоке низшего уровня нет пустого места, блок делится на два блока. В первый из них заносится [ k /2] записей, во второй заносятся остальные. Значением ключа каждого из указанных блоков будет являться, как и описано ранее, минимальное значение ключей у записей, входящих в блок. Добавляемая запись заносится в тот блок, значение ключа которого меньше значения ключа добавляемой записи. Появление нового блока с новым значением ключа обусловливает необходимость формирования соответствующей новой записи в индексе на предыдущем уровне. Эта запись содержит новое значение ключа нового блока и указатель на его месторасположение. Процедура добавления такой записи аналогична описанной выше. Находится блок предыдущего уровня, куда должна быть помещена эта запись. Если в блоке есть пустое место, запись добавляется в блок, если блок полон, он делится на два блока, запись заносится в один из блоков, формируется запись индекса предыдущего уровня и т.д.
|
|
|
Возможен вариант, когда придется делить блок самого верхнего уровня и формировать еще один уровень дерева.
Рассмотрим для примера, изображенного на рис. 27, добавление записи с ключом 10.
1. Сравнение на первом уровне.
2<10<43
Движение по левой ветви.
2. Сравнение на втором уровне.
2<10<15
Движение по левой ветви.
3. Сравнение на третьем уровне.
2<8<10
Движение по правой ветви.
Искомый блок 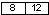
1.4. Блок заполнен.
Он делится на 2 блока


Сравнение 8<10<12.
Запись с ключом 10 заносится в блок 1
2. 
На низшем уровне появилась новая запись с значением ключа 12. Необходимо добавление новой записи с ключом 12 и указателем на запись низшего уровня к индексу предыдущего уровня.
3.5. Запись с ключом 12 уровня 3 должна добавляться в блок  . Блок полон, он делится на два блока
. Блок полон, он делится на два блока
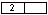

Сравнение 8<12.
Запись добавляется во второй блок 
4.6. На уровне 3 появился блок с новым ключом 8. Необходимо добавление новой записи с ключом 8 и указателем на соответствующий блок уровня 3 на уровне 2.
5.7. Запись с ключом 8 уровня 2 должна добавиться в блок 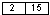 . Блок полон, он делится на два блока.
. Блок полон, он делится на два блока.
|
|
|


2<8<15
Запись добавляется в блок 1 .
6.8. На уровне 2 появился блок с новым ключом 15, необходимо добавление новой записи с ключом 15 и указателем на соответствующий блок уровня 2 на уровне 1.
7.9. Запись с ключом 15 уровня 1 должна добавляться в блок  . Блок полон, он делится на два блока.
. Блок полон, он делится на два блока.

2<15<43
Запись с ключом 15 добавляется в первый блок
8.10. Необходимо сформировать еще один уровень дерева .
Полученная структура будет иметь вид, представленный на рисунке 9.8.

Рис. 9.8. В-дерево после добавления элемента
Необходимо заметить, что используемый прием деления пополам полностью заполненного блока при добавлении в него записи приведет к тому, что блоки будут заполнены, в среднем, наполовину. Тогда процедура добавления записи будет существенно менее трудоемкой (если в нужном блоке есть место, запись добавляется в этот блок и вышестоящие уровни не перестраиваются).
Структура хранения в виде B-дерева позволяет эффективно проводить операции поиска, чтения, удаления, модификации с оценкой числа обращений к внешней памяти числом уровней дерева l (l ≈ logkN), что существенно меньше числа обращений при переборе  .
.
Процедура добавления записи тоже достаточно эффективна. Соответствующая структура хранения, в частности, используется в отечественной СУБД НИКА (ранее использовалась в системе ИНЕС) и на реальных задачах показала высокую эффективность.
9.4.5. Размещение записей с использованием хэширования
Как в любом другом способе организации структур хранения, логические записи группируются в физические записи (блоки) по k штук. Однако в отличие от всех других способов организации структур хранения здесь выбран особенный способ группировки. Определенным образом выбирается так называемая хэш-функция f. Аргументом этой функции является значение x первичного ключа логической записи. Тогда f(x) указывает адрес расположения блока, в котором должна находиться логическая запись со значением ключа x.
Функция f должна, по возможности, равномерно распределять значения x по физическим блокам. Обсуждению возможных хэш-функций посвящено достаточно много литературы, поэтому здесь мы не будем касаться этого вопроса. Можно лишь добавить, что иногда, исходя из специфики множества значений x первичного ключа, можно построить функцию f, удовлетворяющую всем необходимым условиям. Таким образом, логическая запись таблицы со значением x первичного ключа размещается в блоке внешней памяти по адресу f(x). В этом блоке может находиться не более k записей. Может оказаться, что выбранная функция отображает в один адрес памяти (один блок) более k записей. Возникает так называемая коллизия. Возможным способом разрешения коллизий является использование дополнительной области переполнения следующим образом. Если очередная запись распределяется с помощью функции хэширования в блок, а он полностью заполнен, то в области переполнения формируется список записей, соответствующих этому блоку, с включением в него указанной записи, а в сам блок заносится указатель – адрес связи на первую запись этого списка. Возможны и другие способы разрешения коллизий.
|
|
|
Рассмотрим реализацию основных операций и дадим оценку числа обращений к ВП при их выполнении.
|
|
|
