 |


Схема с централизованными данными
|
|
|
|
 |
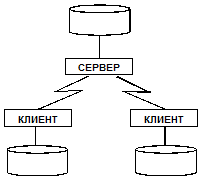
Все данные располагаются централизованно на едином сервере (рис. 3.2), к которому пользователи обращаются с клиентских мест.
Рис. 3.2. Схема с централизованными данными
Иерархия зависимых данных
 |
Данные в машинах нижнего уровня тесно связаны с данными в машинах верхнего уровня (рис. 3.3). Часто они являются подмножеством данных верхнего уровня, используемых в локальных приложениях. На машине верхнего уровня осуществляется объединение всей информации. Примером данной архитектуры является организация ведения реестров в рамках ведомственных вертикалей, например ведение Единого государственного реестра юридических лиц в Федеральной налоговой службе.
Рис. 3.3. Иерархическая схема распределения данных
Иерархия независимых данных
В этой схеме все процессоры представляют независимые замкнутые системы обработки данных (рис. 3.3). Структура данных на машинах нижнего уровня значительно отличается от структуры данных верхнего уровня. Как правило, на нижнем уровне выполняются повторяющиеся массовые (рутинные) операции (например, прием заказов, контроль за выпуском продукции, управление складом). На машинах верхнего уровня собирается агрегированная информация для поддержки принятия стратегических решений.
Схема с расщепленными данными
В этом случае имеется несколько систем с идентичной структурой данных (рис. 3.4). Большинству обрабатываемых транзакций требуются только те данные, которые находятся в обрабатывающей системе. Но в некоторых случаях могут потребоваться данные другого района. При этом объектами передачи из одного района в другой через сеть могут стать либо транзакции, либо данные (тиражирование информации). Примером данной архитектуры может являться сеть филиалов сбербанка.
|
|
|
Рис. 
3.4. Схема с расщепленными данными
Схема с разделенными данными
В каждом узле выполняется своя обработка информации (рис. 3.5). В случае необходимости использования внешних данных посылается запрос, который собирает всю необходимую информацию из узлов сети (так называемый распределенный запрос).
Рис. 
3.5. Схема с разделенными данными
Схема с реплицированными данными
 |
Идентичные копии данных хранятся в разных местах (рис. 3.6). Такая организация имеет место, когда объем обновлений данных незначителен и обосновано тиражирование данных по узлам сети.
Рис. 3.6. Схема с реплицированными данными
Гетерогенная схема
Данная схема предполагает работу в глобальной вычислительной сети. Поддерживается система имен серверов и соответственно система адресации, по которой любой клиент может обратиться к любому серверу для доступа к его информации. При этом может иметь место санкционирование доступа или свободный доступ. Например, сеть Интернет обеспечивает клиентам свободный доступ к большинству информационных ресурсов. Закрытые сети (биржевая система, система библиотек университетов США) обеспечивают санкционированный доступ к соответствующим ресурсам.
3.2. Виды автоматизированных
информационных систем
Автоматизированные информационные системы (АИС) предназначены для хранения, обработки, поиска, распространения, передачи и представления информации. Рассмотрим наиболее часто применяемые виды АИС – документальные поисковые, фактографические аналитические и географические информационные системы.
3.2.1. Документальные
информационно-поисковые системы
Большая часть информации существует в виде документов. Этот вид информации называется слабоструктурированным. Термин «документ» можно определить как средство закрепления различным способом на специальном материале информации о фактах, событиях, явлениях объективной действительности и мыслительной деятельности человека. Документальный поиск – поиск сведений о документе (библиографическое описание, аннотация, реферат), собственно самого документа или его копии. Различают документоцентричные и датоцентричные документы. Датоцентричные документы характеризуются строго регулярной структурой, мелкой зернистостью данных (т.е. самый маленький кусочек данных находится на уровне атрибутов), они отличаются отсутствием или малым количеством смешанного содержимого. Примерами таких документов являются торговые заказы, регистрационные карточки, паспорта оборудования, нормативно-технические документы и т. п. Документоцентричные документы созданы для восприятия человеком. Это книги, сообщения электронной почты, реклама, произведения искусства. Они характеризуются менее регулярной или иррегулярной структурой, крупно-зернистыми данными (самые маленькие независимые части данных имеют уровень элементов со смешанным содержимым или целого документа) и содержат много смешанного содержимого.
|
|
|
Документальные информационные системы прошли несколько стадий развития.
В середине 80-х годов появились первые документальные информационно-поисковые системы. Информационно-поисковая система (ИПС) – это совокупность языковых, программных и технических средств, предназначенных для организации сбора, хранения, поиска и постобработки накопленной информации.
Для организации ИПС применялись распространенные коммерческие СУБД. В основу организации поиска в документальных ИПС положено индексирование документов и запросов (рис. 3.7). Индексирование – это процесс выражения содержания поисковых образов документов (ПОД) и поисковых образов запросов (ПОЗ) на информационно-поисковом языке (ИПЯ). Различают классификационный и дескрипторный ИПЯ. В основе ИПЯ классификационного типа лежит систематическая классификация понятий в виде древовидной структуры (например, классификаторы УДК, ГРНТИ). В основе ИПЯ дескрипторного типа лежит алфавитный перечень лексических единиц, выраженных словами или словосочетаниями (дескрипторов). В целях эффективного поиска для каждого дескриптора указываются синонимы, родовидовые, ассоциативные и другие понятия. Такой словарь называют тезаурусом.
|
|
|
Рис. 
3.7. Структура документальной ИПС
В основу организации поиска в документальных ИПС положен поиск по ключевым словам. Перечислим основные проблемы, связанные с этим видом поиска:
- определение ключевых слов представляет собой достаточно субъективный процесс;
- индексирование является трудоемкой процедурой;
- поиск по ключевым словам – это четкий поиск; пользователь должен точно знать, что он ищет;
- ключевые слова могут со временем меняться.
В ИПС, созданных на основе реляционных баз данных, индексирование выполняется с использованием справочников, которые могут быть организованы в виде списка, дерева, справочника категорий (рис. 3.8).
 |
Следует отметить, что в качестве справочников по возможности следует применять готовые зарегистрированные классификаторы с унифицированными кодами. При этом в конкретном приложении возможно их сокращение с развитием и уточнением нижних уровней существующей классификации. Примерами готовых классификаторов являются Общероссийский классификатор административно-территориальных образований (ОКАТО), Общероссийский классификатор форм собственности (ОКФС), Общероссийский классификатор видов экономической деятельности (ОКВЭД) и т. д.
Рис. 3.8. Варианты организации справочников в ИПС
В 90-е годы появились системы управления электронными документами (Electronic Document Management Systems – EDMS). Поиск в них основан на механизме полнотекстового поиска, который реализуется с помощью технологии индексирования на основе инвертированной матрицы. Суть подхода заключается в том, что при создании индексного файла (инвертированной матрицы) в него вносятся все значимые слова (без союзов и предлогов) из всех документов в алфавитном порядке. Эти слова затем объединяются в пары с указателями на соответствующие документы.
Принципиальным технологическим новшеством явилось использование технологии оптического распознавания символов (Optical Character Recognition – OCR). При этом выполняется сканирование документов, распознавание символов, организация хранения электронных версий с полнотекстовым индексированием для последующего поиска. Среди «узких мест» полнотекстового поиска можно выделить следующее:
|
|
|
- индекс обычно составляет от 200 до 400 % от объема исходного текста документа;
- механизм четкого поиска через инвертированную матрицу не позволит найти информацию, если были допущены ошибки при распознавании символов в документе или при написании запроса.
EDMS-системы не исключают использования поиска по ключевым словам при наличии в предметном приложении соответствующих классификаторов.
Наряду с организацией хранения документов в EDMS-системах поддерживается коллективная работа с документами. При этом выделяется два класса систем:
- системы groupware, поддерживающие коллективный доступ пользователей к базе документов;
- 
системы workflow, поддерживающие возможность разделения работ на основе модели группового взаимодействия с распределением ролей, очередности обращения к документам, контроля исполнения и т.д.
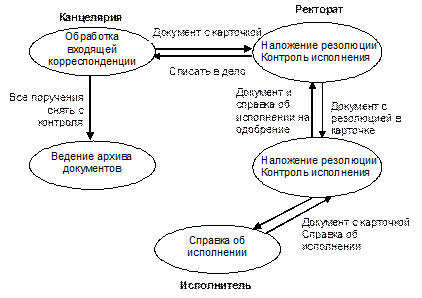
Рис. 3.9. Функциональная диаграмма управления движением документов
в EDMS-системе
Системы управления электронными документами ориентированы на создание архивов документов, управление движением документов, тиражирование ноу-хау, организацию коммерции на информационных ресурсах в сети Интернет через корпоративные порталы (корпоративный портал поддерживает интеграцию корпоративных информационных ресурсов с Интернет-сервисами).
При создании архива документов поддерживается иерархическая классификация документов по типам; ведение истории жизни документа; возможность получения информации о других документах, связанных с конкретным документом; объединение документов во временные иерархические группы с различными уровнями доступа (папки) без изменения физического размещения в архиве. На рис. 3.9 показан фрагмент функциональной диаграммы управления движением документов в университетской системе.
К системам класса groupware можно отнести продукт Lotus Notes/Domino (Lotus Development). Класс workflow может быть представлен системами Staffware (Staffware plc) и Action Workflow (Action Technologies).
К третьему поколению информационных систем относятся системы, поддерживающие нечеткий поиск. В этом случае содержание всех документов заменяется бинарным кодом. Так компания Excalibur Technologies разработала технологию адаптивного распознавания образов, которая была положена в основу системы управления документами Excalibur EFS (Excalibur Technologies Corp). Индексирование в системе основано на работе нейронной сети. Создан комплекс алгоритмов, самостоятельно адаптирующихся к особенностям обрабатываемой информации и позволяющих осуществлять поиск образов, составленных из двоичных символов.
|
|
|
3.2.2. Фактографические
информационно-аналитические системы
Фактографический поиск – это поиск данных, фактов, извлеченных из документов (характеристик приборов, свойств веществ и материалов, показателей деятельности организаций и т.д.). Фактографическая информация организуется, как правило, в целях последующей аналитической обработки, автоматизации поддержки принятия решений. Возможности сетевой обработки данных, развитие методов моделирования и аналитической обработки данных, а также теории менеджмента привели к распространению корпоративных информационных систем (КИС) в различных сферах автоматизации. Так для контроля технологическими объектами и процессами создаются системы диспетчерского контроля и накопления данных SCADA (Supervisory Control And Data Acquisition), автоматизированные системы управления технологическими процессами (АСУ ТП). К системам подготовки и учета производственной деятельности относятся системы планирования потребности в материалах (Material Requirement Planning – MRP), системы планирования ресурсов производства (Manufacturing Resource Planning – MRP II), автоматизированные системы проектирования и подготовки производства (Computing Aided Design and Manufacturing – CAD/CAM), автоматизированные рабочие места (АРМ) и др.
Наибольший интерес с точки зрения организации и обработки информации представляют системы планирования и анализа производственной деятельности, используемые для принятия стратегических решений, оказывающих влияние на деятельность предприятия в целом. К указанным системам относятся системы планирования ресурсов предприятия (Enterprise Resource Planning – ERP), системы управления эффективностью бизнеса (Business Performance Management – BPM), автоматизированные системы управления предприятием (АСУП) и др.
С учетом определенных функциональных возможностей можно выделить локальные системы, предназначенные для ведения учета по одному или нескольким направлениям (бухгалтерия, сбыт, склады, учет кадров), финансово-управляющие системы, предназначенные для учета и управления ресурсами непроизводственных компаний; средние интегрированные системы, предназначенные для управления производственным предприятием и интегрированного планирования производственного процесса; крупные интегрированные системы, ориентированные на управление производством, управление сложными финансовыми потоками, корпоративную консолидацию, глобальное планирование и бюджетирование и пр. Крупные интегрированные системы отличаются от средних систем набором вертикальных рынков и глубиной поддержки процессов управления больших многофункциональных групп предприятий. Так для малых предприятий, предприятий без производства (торговля, услуги) подходят локальные и финансово-управляющие системы. На производственных предприятиях используются средние интегрированные системы. Для управленческих структур (холдингов) используются крупные интегрированные системы, предназначенные для корпоративного планирования и бюджетирования, корпоративной консолидации и получения управленческой отчетности, многомерного анализа данных в целях поддержки принятия стратегических решений.
В основе автоматизации поддержки принятия решений лежит концепция хранилищ данных корпоративных информационных систем (рис. 3.10). Корпорация – это стабильная многопрофильная территориально распределённая структура, обладающая всеми необходимыми системами жизнеобеспечения и функционирующая на принципах децентрализованного управления (принятие решений оперативного и тактического характера делегировано на местах и находится в компетенции подразделений, входящих в состав корпорации). Системы поддержки принятия решений (СППР) – программные средства для руководства среднего звена, занимающегося управлением и планированием. Существует четыре подхода к поддержке принятия решений в КИС.
1. Генерация нерегламентированных запросов и отчетов. Обеспечение возможности гибкой навигации по хранилищу данных в целях реализации нерегламентированных выборок и оформления их в виде отчетов. Навигаторы через удобный пользовательский интерфейс позволяют в терминалах концептуальной модели хранилища данных генерировать SQL-запросы (процесс генерации скрыт от пользователя) и оформлять результаты в виде отчетов. Для этого используются навигационные метаданные хранилища, которые описывают семантику концептуальной модели предметной области.
2. Многомерная аналитическая обработка данных (On-Line Analytical Processing – OLAP). В основе концепции лежит многомерное представление данных. По Э.Ф. Кодду (именно он в 1993 году предложил концепцию многомерного анализа данных), многомерное аналитическое представление информации– это множественная перспектива, состоящая из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает одно или несколько направлений консолидации данных, состоящих из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. При этом в хранилище данных генерируется гиперкубическая модель (аналитические метаданные), которая поддерживает агрегированные значения показателей, сопровождаемые соответствующими кодами справочников измерений. Аналитику предоставляется прозрачный интерфейс (12 принципов организации такого интерфейса декларировал Э.Ф. Кодд), позволяющий генерировать различные сводные табличные отчёты, диаграммы деловой графики, раскрашенные картограммы.
Интеллектуальный анализ данных (Data Mining). Процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом используются методы искусственного интеллекта, прикладной статистики, теории баз данных.
Генерация регламентированных отчетов. Процесс разработки шаблонов отчетов и сценариев их заполнения, а также генерации готовых отчетов по имеющимся шаблонам на основе заданных значений аргументов. Система регламентированных отчетов может быть положена в основу информационной системы руководителя (Executive Information Systems – EIS). Развитые инструменты объединяют в себе возможности пакетной генерации регламентированных отчетов с настольными генераторами запросов, средства рассылки отчетов и их оперативного обновления. К средствам генерации отчетов можно отнести системы Crystal Reports, Oracle Reports Developer и др.

Рис. 3.10. Структура корпоративной информационной системы
|
|
|
