 |


Интеллектуальный анализ данных (Data Mining)
|
|
|
|
Интеллектуальный анализ данных (ИАД) ориентирован на поиск закономерностей в накопленной информации. При этом используются методы искусственного интеллекта, прикладной статистики, теории баз данных. Выделяются пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65 % купивших кукурузные чипсы берут также и кока-колу, а при наличии скидки за такой комплект колу приобретают в 85 % случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45 % случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60 % новоселов обзаводятся холодильником. Выявленные ассоциации и последовательности позволяют выполнять анализ покупательской корзины для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.

Рис. 3.13. Фрагмент сформированного отчета по поставкам деталей
С помощью классификации выявляются признаки, характеризующие однотипные группы объектов – классы, для того чтобы по известным значениям этих характеристик можно было отнести новый объект к тому или иному классу. Ключевым моментом выполнения этой задачи является анализ множества классифицированных объектов. Типичный пример использования классификации – исследование характерных признаков мошенничества с кредитными карточками в банковском деле. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
|
|
|
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации самостоятельно выделяются различные однородные группы данных. Так, например, можно выделить родственные группы клиентов с тем, чтобы определить характеристики неустойчивых клиентов («группы риска») – клиентов, готовых уйти к другому поставщику. При этом необходимо найти оптимальную стратегию их удержания (например, посредством предоставления скидок, льгот или даже с помощью индивидуальной работы с представителями «группы риска»).
Основой для систем прогнозирования служит историческая информация, хранящаяся в виде временных рядов. Если удается построить шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать поведение системы в будущем. Например, создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением (покупающих товары известных дизайнеров или посещающих распродажи). Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
В общем случае процесс ИАД состоит из трёх стадий:
1) выявления закономерностей;
2) использования выявленных закономерностей для предсказания неизвестных значений;
3) анализа исключений, предназначенного для выявления и толкования аномалий в найденных закономерностях.
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining.
|
|
|
Традиционные методы прикладной статистики
- Статистическое исследование структуры и характера взаимосвязей, существующих между анализируемыми количественными переменными. Сюда относят корреляционный, факторный, регрессионный анализ, анализ временных рядов. Необходимо отметить, что проблема статистического исследования зависимостей по своему значению заметно превосходит две другие.
- Методы классификации объектов и признаков. В данной группе выделяют, в частности, дискриминантный и кластерный анализ.
- Снижение размерности исследуемого признакового пространства в целях лаконичного объяснения природы анализируемых данных. К данному разделу относят метод главных компонент, многомерное шкалирование и латентно структурный анализ.
В качестве примеров наиболее мощных и распространенных статистических пакетов, реализующих указанные методы, можно назвать SAS, SPSS, STATGRAPHICS, STATISTICA и др.
Нейронные сети
Искусственные нейронные сети (ИНС) представляют парадигму обработки информации, базирующуюся на той или иной упрощенной математической модели биологических нейронных систем. ИНС организует свою работу путем распределения процесса обработки информации между нейроэлементами, связанными между собой посредством синаптических связей. Выявление закономерностей в данных осуществляется путем обучения ИНС, в процессе которого происходит корректировка величин синаптических связей. Круг задач, решаемых при помощи данных методов, также довольно широк: распознавание образов, адаптивное управление, прогнозирование, построение экспертных систем и др. Основными недостатками нейросетевой парадигмы являются: необходимость большого объема обучающей выборки, отсутствие универсальных топологий и настроек сети. Другой существенный недостаток заключается в том, что ИНС представляет собой «черный ящик», не поддающийся интерпретации человеком. Примеры нейросетевых систем – BrainMAker, NeuroShell, OWL, Neural Analyzer в программном комплексе Deductor (BaseGroup).
Методы обнаружения логических закономерностей в данных
|
|
|
Данные методы апеллируют к информации, заключенной не только в отдельных признаках, но и в сочетаниях значений признаков. Они вычисляют частоты комбинаций простых логических событий в подгруппах данных. На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциаций в данных, для классификации, прогнозирования. Результаты работы данных методов оформляются в виде деревьев решений или правил типа «ЕСЛИ…, ТО…». Популярность данного подхода связана с наглядностью и понятностью полученных результатов анализа. Проблемой логических методов обнаружения закономерностей является необходимость перебора вариантов за приемлемое время и поиск оптимальной композиции предложенных правил. Представителями систем, реализующих данные методы, являются системы See5/C5.0, WizWhy, Tree Analyzer (BaseGroup).
Методы рассуждения на основе аналогичных случаев
Идея методов CBR (case based reasoning) довольно проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и
выбирают тот же ответ, который был для них правильным. Главным минусом такого подхода считают то, что данные системы вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт. В выборе решения они основываются на всем массиве доступных исторических данных. Поэтому существует проблема выбора объема множества прецедентов, которые необходимо хранить для достижения удовлетворительной классификации или прогноза. Примеры систем, использующих CBR – KATE tools, Pattern Recognition Workbench.
Эволюционные и генетические алгоритмы
Данные методы предназначены в основном для оптимизации в задачах поиска зависимости целевой переменной от других переменных. Примером может служить обучение нейронной сети, то есть подбор таких оптимальных значений весов, при которых достигается минимальная ошибка. В основе указанных методов лежит метод случайного поиска, модифицированный за счет использования ряда биологических принципов, открытых при изучении эволюции и происхождения видов, для отбора наилучшего решения. В частности, используются процедуры репродукции (скрещивания), изменчивости (мутаций), генетической композиции, конкурирования в рамках естественного отбора наилучшего решения. В силу своей специфики данные методы часто используются в качестве дополнительного инструментария к какому-либо другому методу. Пример реализации эволюционного алгоритма – отечественная система PolyAnalist. GeneHanter – пример системы, использующей генетические алгоритмы.
|
|
|
Методы визуализации многомерных данных
Эти методы позволяют ассоциировать с анализируемыми данными различные параметры диаграмм рассеивания: цвет, форму, ориентацию относительно собственной оси, размеры и другие свойства графических элементов. При этом они не выполняют автоматического поиска закономерностей, но реализуемые на их основе выводы чрезвычайно удобны для интерпретации и объяснения. В той или иной мере средства для графического отображения данных поддерживаются абсолютным большинством систем Data Mining, однако внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции. Примером может служить программа DataMiner 3D.
Следует отметить, что использование автономных инструментов Data mining менее предпочтительно по сравнению с их внедрением в среду OLAP или СУБД.
3.2.3. Геоинформационные системы
Геоинформационная система (ГИС) – это программно-аппаратный комплекс, осуществляющий сбор, отображение, обработку, анализ и распространение информации о пространственно распределенных объектах и явлениях на основе электронных карт и связанных с ними баз данных. ГИС – это особый случай автоматизированной информационной системы, где база данных состоит из наблюдений за пространственно распределенными явлениями, процессами и событиями, которые могут быть определены как точки, линии или контуры.
Функции ГИС:
- создание высококачественной картографической продукции; процесс преобразования данных с бумажных карт в компьютерные файлы называется оцифровкой;
- геокодирование – процесс установления пространственной привязки объектов с атрибутивной информацией;
- манипулирование и визуализация информации;
- пространственный анализ и моделирование;
- интеграция информации различных источников.
Существует два подхода к представлению пространственных объектов:
- растровый (ячейки или клетки на карте);
- векторный (точки, линии, полигоны).
Вся карта представлена набором слоев. Каждый слой соответствует определенному информационному объекту базы данных. Слои могут быть точечными, площадными и полигонными. Кроме этого, выделяются надписи. Объекты разных слоев могут иметь пространственную связь между собой. Связь такого рода называется топологией. Несколько связанных слоев могут образовывать покрытие.
|
|
|
Пространственный анализ включает в себя следующие методы: навигацию, поиск информации, моделирование.
Навигация включает в себя:
- изменение масштаба;
- перемещение по карте;
- выдачу необходимого набора слоев;
- задание атрибутов слоя;
- порядок прорисовки слоев.
Поиск информации включает:
- поиск конкретного объекта по карте по атрибутивным данным (например, поиск улицы по названию);
- поиск атрибутивной информации об объекте на карте;
- построение буферных зон, анализ близости;
- поиск по геометрическим признакам (например, нахождение одного объект или его части внутри другого, нахождение смежных объектов).
Моделирование используется при построении, например, моделей инженерных сетей (тепловых, электрических).
Приведем примеры пространственных запросов. Сколько домов находится в 100 метрах от заданного водоема? (пример анализа близости); Сколько покупателей живет не далее 1 км от данного магазина?; Какие почвы встречаются в заданной охраняемой территории? (выполняется наложение почвенной карты на карту охраняемых объектов).
Наиболее распространенными представителями ГИС являются продукты MapInfo, ArcInfo.
3.3. МетодЫ анализа и проектирования
информационных систем
Характерными чертами корпоративных информационных систем являются длительность жизненного цикла, масштабность и сложность решаемых задач, пересечение множества предметных областей, ориентация на аналитическую обработку данных, территориальная распределенность, наличие нескольких уровней иерархического подчинения и др. Перечисленные свойства послужили стимулом к развитию и использованию инструментальных средств для анализа и проектирования автоматизированных систем – CASE-средств (Computer Aided Software Engineering). Обычно к CASE-средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла автоматизированной системы и обладающее следующими основными характерными особенностями, такими как:
- мощные графические средства для описания и документирования системы, обеспечивающие удобный интерфейс с разработчиком и развивающие его творческие возможности;
- интеграция отдельных компонентов CASE-средств, обеспечивающая управляемость процессом разработки системы;
- использование специальным образом организованного хранилища проектных метаданных (репозитория).
Интегрированное CASE-средство (или комплекс средств, поддерживающих полный жизненный цикл программного обеспечения) содержит следующие компоненты:
- репозиторий, являющийся основой CASE-средства; он должен обеспечивать хранение версий проекта и его отдельных компонентов, синхронизацию поступления информации от различных разработчиков при групповой разработке, контроль метаданных на полноту и непротиворечивость;
- графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически связанных диаграмм, образующих модели автоматизированных систем;
- средства разработки приложений;
- средства конфигурационного управления;
- средства документирования;
- средства тестирования;
- средства управления проектом;
- средства реинжиниринга.
В основе CASE-средства лежит определенная методология анализа и проектирования автоматизированной системы. При этом имеют место два основных подхода – структурный и объектный.
Структурный подход основан на декомпозиции функций, реализуемых системой. В его основе лежит функциональная модель (Data Flow Diagrams – DFD), информационная модель (Entity Relationship Diagrams – ERD) и событийная модель состояний (State Translation Diagrams – STD). Процессу проектирования системы предшествует анализ бизнес-процессов, имеющих место в предметной области. При этом используется методология структурного анализа систем (Structured Analysis and Design – SADT), на основе которой принят стандарт моделирования бизнес-процессов IDEF0.
Сочетание DFD- и ERD- диаграмм дает относительно полные модели анализа, которые фиксируют все функции и данные на требуемом уровне абстракции независимо от особенностей аппаратного и программного обеспечения. Построенные модели анализа преобразуются в проектные модели, которые обычно выражаются в понятиях реляционных баз данных.
Следует заметить, что структурный подход направлен на разработку негибких решений, которые способны удовлетворить набор определенных бизнес-функций, но которые в будущем может быть трудно масштабировать и расширять. Вместе с тем до сих пор структурный подход широко используется при проектировании информационных систем.
Наиболее распространенными CASE-средствами, основанными на структурном подходе, являются BPwin (поддерживает нотации IDEF0, DFD, IDEF3) для функционального моделирования и ERwin для информационного моделирования систем. Фирма ORACLE, в частности, поддерживает свой продукт Designer/2000. Представляет интерес продукт PowerDesigner (поддерживает нотации IDEF1X, DFD,UML).
Объектно-ориентированный подход основан на глубинном изучении предметной области с позиции объектов и их поведения. Ассоциация производителей программного обеспечения Object Managament Group утвердила в качестве стандартного средства моделирования для этого подхода язык UML (Unified Modeling Language – унифицированный язык моделирования). По сравнению со структурным подходом объектно-ориентированный подход в большей степени ориентирован на данные. Он соответствует итеративному процессу разработки с наращиванием возможностей. Единая модель конкретизируется на этапах анализа, проектирования и реализации.
Для объектного анализа и проектирования систем возможно использование продуктов Rational Rose (Rational Software), Paradigm Plus (Computer Associates) и др.
Рассмотрим наиболее распространенные методы анализа и проектирования информационных систем.
3.3.1. Моделирование бизнес-процессов (IFEF0)
С точки зрения менеджеров, наиболее подходящим языком моделирования бизнес-процессов на стадии создания моделей предметной области является IDEF0. Этот язык моделирования появился в результате применения методологии структурного анализа и проектирования систем (Structured Analysis and Design Technique - SADT). На основе этой методологии создан стандарт моделирования бизнес-процессов IDEF0. Его успеху в немалой степени способствовала фирма Logic Works (США), создав на основе IDEF0 свой популярный среди менеджеров программный продукт BPwin. В 2000 году в нашей стране введен в действие руководящий документ РД IDEF0-2000 «Методология функционального моделирования IDEF0».
Стандарт IDEF0 используется при проектировании корпоративных информационных систем, при документировании созданных систем, а также используется в процессе совершенствования (реинжиниринга) деятельности организации при построении новой модели бизнес-процессов.
В нотации IDEF0 описание системы (модель) организовано в виде иерархически упорядоченных и взаимосвязанных диаграмм. Вершина этой древовидной структуры представляет собой самое общее описание системы и ее взаимодействия с внешней средой, а в ее основании находятся наиболее детализированные описания выполняемых системой функций. Диаграммы содержат функциональные блоки, соединенные дугами. Дуги отображают взаимодействия и взаимосвязи между блоками. Функциональный блок на диаграммах изображается прямоугольником и представляет собой функцию или активную часть системы, поэтому названиями блоков служат глаголы или глагольные обороты. Каждая сторона блока имеет особое, вполне определенное назначение. К левой стороне блока подходят дуги входов, к верхней – дуги управления, к нижней – механизмов реализации выполняемой функции, а из правой – выходят дуги выходов. Такое соглашение предполагает, что, используя управляющую информацию об условиях и ограничениях и реализующий ее механизм, функция блока преобразует свои входы в соответствующие выходы.
На диаграмме блоки упорядочены по степени важности, начиная с левого верхнего угла диаграммы и кончая нижним правым углом. Для обеспечения наглядности и лучшего понимания моделируемых процессов рекомендуется использовать от 3 до 6 блоков на одной диаграмме. Такое представление модели устраняет неоднозначность, присущую естественному языку. Благодаря этому достигается необходимая для понимания и анализа лаконичность и точность описания без потери деталей и качества.
Рассмотрим основные компоненты IDEF0 синтаксиса.
 |
Блоки изображают функции, представляющие собой действия или процессы. Каждый блок должен иметь имя и номер внутри границ блока (рис. 3.14). Имя должно начинаться с глагола, который описывает функцию. Каждый блок на диаграмме должен содержать внутри номер блока. Номер блока используется для идентификации подчиненного блока в связанном тексте.
Рис. 3.14. Изображение блока
Рис.
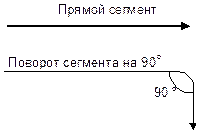 |
3.15. Изображение дуги
Рис.
 |
3.16. Варианты объединения дуг
Дуги изображают данные или объекты, связанные функциями. Дуга состоит из одного или нескольких сегментов линии со стрелкой, направленной в один конец. Как показано на рис. 3.15, сегмент дуги может быть прямым или изогнутым (на угол, кратный 90°). Дуги передают данные или объекты, связанные функциями, которые нужно выполнить (рис. 3.16).
Правила определяют, как используются вышеуказанные компоненты:
1) блок должен быть достаточного размера, чтобы в него убралось имя блока;
2) блок должен иметь прямоугольную форму и квадратные углы;
3) блок должен изображаться сплошными линиями;
4) угол изгиба дуг должен быть кратным 90°;
5) дуги должны изображаться сплошными линиями;
6) дуги должны изображаться вертикально или горизонтально, но не по диагонали.
7) концы дуги должны касаться внешнего периметра функционального блока;
8) дуги должны присоединяться к сторонам блока, а не к углам.
Диаграммы представляют собой объединения блоков и дуг, изображенных в соответствии с правилами. Место соединения дуги с блоком определяет тип интерфейса. Управляющая информация входит в блок сверху, в то время как информация, которая подвергается обработке, показана с левой стороны блока, а результаты выхода показаны с правой стороны (рис. 3.17). Механизм (человек или автоматизированная система), который осуществляет операцию, представляется дугой, входящей в блок снизу.
 |
Одной из наиболее важных особенностей методологии SADT является постепенное введение все больших уровней детализации по мере создания диаграмм, отображающих модель.
Рис. 3.17. Функциональный блок и интерфейсные дуги
Построение модели бизнес-процессов начинается с представления всей системы в виде простейшего компонента − одного блока и дуг, изображающих интерфейсы с функциями вне системы. Поскольку единственный блок представляет всю систему как единое целое, имя, указанное в блоке, является общим. Это верно и для интерфейсных дуг − они также представляют полный набор внешних интерфейсов системы в целом. Затем блок, который представляет систему в качестве единого модуля, детализируется на другой диаграмме с помощью нескольких блоков, соединенных интерфейсными дугами. Эти блоки представляют
основные подфункции системы. Данная декомпозиция выявляет полный набор подфункций, каждая из которых представляется блоком, границы которого определены интерфейсными дугами. Каждая из этих подфункций может также быть декомпозирована подобным образом для более детального представления. Модель представляет собой серию диаграмм с сопроводительной документацией, разбивающих сложный объект на составные части, которые представлены в виде блоков (рис.
 |
3.18).
Рис. 3.18. Декомпозиция диаграмм
Во всех случаях каждая подфункция может содержать только те элементы, которые входят в исходную функцию. Кроме того, модель не может опустить какие-либо элементы, т.е., как уже отмечалось, родительский блок и его интерфейсы обеспечивают контекст. К нему нельзя ничего добавить, и из него не может быть ничего удалено.
Дуги, входящие в блок и выходящие из него на диаграмме верхнего уровня, являются точно теми же самыми, что и дуги, входящие в диаграмму нижнего уровня и выходящие из нее, потому что блок и диаграмма представляют одну и ту же часть системы.
 |
Приведены варианты выполнения функций и соединения дуг с блоками (рис. 3.19 – 3.21).
Рис.
 |
3.19. Одновременное выполнение функций
Рис. 3.20. Полное и непротиворечивое соответствие между диаграммами
Рис.
 |
3.21. Обратная связь по управлению
 |
Для того чтобы указать положение любой диаграммы или блока в иерархии, используются номера диаграмм (рис. 3.22). Например, А21 является диаграммой, которая детализирует блок 1 на диаграмме А2. Аналогично А2 детализирует блок 2 на диаграмме А0, которая является самой верхней диаграммой модели. Приведен пример анализа бизнес-процессов (рис. 3.23).
Рис. 3.22. Иерархия диаграмм
Рис. 
3.23. Пример анализа бизнес-процессов
3.3.2. функциональное моделирование (DFD)
Построение диаграмм потоков данных (DFD), являясь методом функционального моделирования, позволяет показать набор задач (функций/процессов), которые необходимо решать для поддержания деятельности автоматизированной системы, и информационные потоки между ними. DFD-диаграммы используются для описания процессов обработки информации в АИС.
Рассмотрим основные компоненты DFD-синтаксиса.
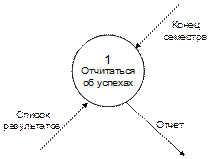
Процессы показывают, что делает система (рис. 3.24). Каждый процесс имеет одну или несколько точек ввода данных и одну или несколько точек вывода данных. Процессы в DFD обычно изображаются в виде кругов. Каждый процесс имеет уникальное имя и номер.
Рис.
 |
3.24. Изображение процесса
 |
Накопители данных содержат данные, поддерживаемые системой. Процессы могут поместить данные в накопитель и извлечь их из него. Накопители данных обычно изображаются в DFD при помощи тонкой линии, каждый накопитель имеет уникальное имя (рис. 3.25). Имя может быть расположено над или под линией, изображающей накопитель данных.
Рис. 3.25. Изображение накопителя данных
 |
Внешние сущности либо передают данные в систему (в этом случае они называются источниками), либо получают данные из системы (в этом случае они называются приемниками). Внешние сущности изображаются в виде прямоугольника и имеют уникальное имя (рис. 3.26).
Рис. 3.26. Изображение внешней сущности
Потоки данных определяют передачу данных в системе и изображаются стрелками, соединяющими компоненты системы. Направление стрелки указывает на направление потока. Каждый поток имеет имя, отображающее его содержание (рис. 3.27).
Рис.
 |
3.27. Изображение потока данных
Потоки данных могут иметь место:
- между двумя процессами;
- от накопителя к процессу;
- от процесса к накопителю;
- от источника к процессу;
- от процесса к приемнику.
При моделировании определяются только перечисленные потоки. Не возможно определять потоки между внешними сущностями, а также между накопителями данных в силу их пассивности.
 |
Существует ряд нотаций представления DFD-диаграмм (рис. 3.28 – 3.30).
Рис.
 |
3.28. Диаграммы потоков данных в нотации Yourdon / De Marco
Рис. 3.29. Диаграммы потоков данных в нотации SSADM
Рис.
 |
3.30. Диаграммы потоков данных в нотации Gane/Sarson
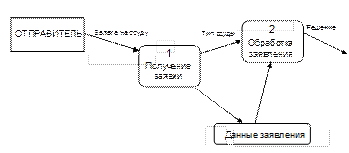
 Процесс построения модели потоков данных выполняется сверху вниз, начиная с контекстной диаграммы (рис. 3.31), на которой система представлена в виде одного процесса. Кроме того, в контекстной диаграмме показаны все внешние сущности, взаимодействующие с системой, и все потоки данных между ними и системой. Цель контекстной диаграммы – определить, как система связана и взаимодействует с другими сущностями, составляющими ее окружение (среду данных).
Процесс построения модели потоков данных выполняется сверху вниз, начиная с контекстной диаграммы (рис. 3.31), на которой система представлена в виде одного процесса. Кроме того, в контекстной диаграмме показаны все внешние сущности, взаимодействующие с системой, и все потоки данных между ними и системой. Цель контекстной диаграммы – определить, как система связана и взаимодействует с другими сущностями, составляющими ее окружение (среду данных).
Рис. 3.31. Контекстная DFD- диаграмма
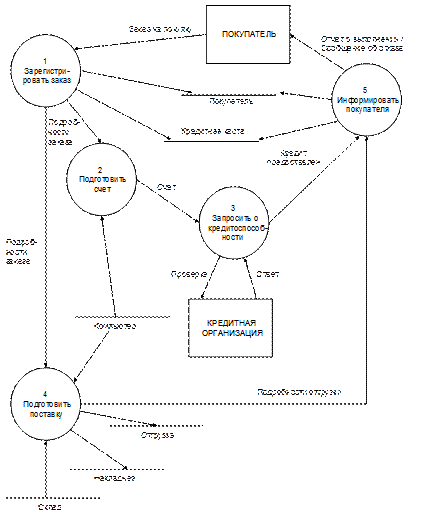 DFD верхнего уровня (рис. 3.32) обеспечивает более детальное описание системы. Она определяет главные процессы системы (максимум 6 или 7), потоки данных между ними, внешние сущности и накопители данных. Каждый процесс имеет уникальное имя и номер, причем порядок обработки данных соответствует номерам процессов.
DFD верхнего уровня (рис. 3.32) обеспечивает более детальное описание системы. Она определяет главные процессы системы (максимум 6 или 7), потоки данных между ними, внешние сущности и накопители данных. Каждый процесс имеет уникальное имя и номер, причем порядок обработки данных соответствует номерам процессов.
Рис. 3.32. DFD-диаграмма верхнего уровня
Для нумерации процессов используется десятичная система: в диаграмме второго уровня, детализирующей процесс 3 диаграммы верхнего уровня, процессы имеют номера 3.1, 3.2, 3.3 и т. д.; процессы DFD третьего уровня, описывающие процесс 3.3, имеют номера 3.3.1, 3.3.2 и т. д. Поток данных DFD нижнего уровня получает в точности тот же «входной» поток данных и передает такой же «выходной» поток, как и процесс верхнего уровня, который он описывает.
Во избежание ошибок, возникающих при разработке диаграмм потоков данных, необходимо учитывать следующее:
-
 |
потоки данных не могут расщепляться на несколько других потоков (рис. 3.33);
Рис. 3.33. Ошибка, связанная с расщеплением потоков данных
-
 |
между процессами не может быть циклов и повторений (рис. 3.34);
Рис. 3.34. Ошибка, связанная с использованием циклов
-
 |
процессы не могут активизироваться входными сигналами (рис. 3.35).
Рис. 3.35. Ошибка, связанная активацией процессов входными сигналами
Чтобы сделать DFD читаемой, необходимо придерживаться следующих правил.
- Процессы должны описываться коротким словосочетанием с глаголом, например «вычислить недельный оклад».
- копители данных должны содержать только один конкретный набор структур и обозначаться сложным существительным, например «заказ пользователя».
- Потоки данных должны обозначаться одним существительным, описывающим поток, например «счет» или «заказ»; в больших системах можно использовать словосочетания для поддержки уникальности имен потоков, например «подробности заказа» или «подробности отгрузки».
3.3.3. Унифицированный язык моделирования (UML)
В январе 1997 года три теоретика в области объектного моделирования Гради Буч, Джим Рамбо и Айвар Якобсон, объединившиеся под эгидой компании Rational Software, подготовили и выпустили версию 1.0 спецификации нового языка объектно–ориентированного моделирования UML, отразившего сильные стороны методологий Booch, OMT и OOSE.
UML изначально задумывался авторами не как язык моделирования данных, а как язык объектного проектирования. Создатели UML позиционировали его как язык для определения, представления, проектирования и документирования программных систем, бизнес-систем и прочих систем непрограммного обеспечения. UML представляет собрание лучших технических методов, которые успешно доказали свою применимость при моделировании больших и сложных систем.
В основе языка лежит совокупность диаграмм, посредством которых моделируется статика и динамика процессов, происходящих в системе. Сначала выполняется анализ требований к системе на основе выявления прецедентов − вариантов использования системы (use case) с точки зрения внешнего окружения. Разрабатываемая модель видов деятельности (activity model) отражает внутрисистемную точку зрения. Диаграмма видов деятельности показывает алгоритм вычисления в рамках каждого прецедента.
Внутреннее состояние системы задается в модели классов (class model). Выделяются классы-сущности (entity class), которые представляют постоянно хранимые объекты базы данных. Также выделяются пограничные классы (boundary class) для определения интерфейсов системы и управляющие классы (control class) для определения программной логики. На этапе анализа прецедентов, как правило, формируются классы-сущности. Моделирование классов других типов выполняется на этапе проектирования системы.
Далее проводится анализ поведения классов в определенных вариантах использования. При моделировании взаимодействий (interaction modeling) между классами определяются наборы сообщений, свойственных поведению системы. Каждое сообщение обращается к операции в вызываемом объекте. Таким образом, исследование взаимодействий между классами приводит к выявлению операций. Если модель взаимодействий (interaction model) является источником детализированной спецификации прецедента, то разрабатываемая модель состояний (statechart model) служит детализированным описанием класса (динамических изменений состояний класса). Диаграмма состояний, присоединенная к классу, определяет способ реагирования объектов класса на события.
Построенная на этапе анализа модель классов детализируется на этапе проектирования системы. В процессе архитектурного проектирования системы решаются проблемы, связанные с построением клиентской и серверной частей системы. Выделяются следующие части системы: пользовательский интерфейс, презентационная логика (логика представления), прикладные функции приложения (логика программы), функции доступа к данным. Выполняется преобразование (отображение) классов UML-модели в логическую модель базы данных (реляционной, объектно-ориентированной или объектно-реляционной). Решается вопрос о реализации логики программы (исполняемые модули, динамически компонуемые библиотеки, хранимые процедуры, триггеры, ограничения целостности базы данных).
Рассмотрим несколько подробнее структурный уровень моделирования в UML.
Структурные сущности представляют собой статические части модели, соответствующие концептуальным или физическим частям системы. Существует несколько разновидностей структурных сущностей: класс, объект, интерфейс, прецедент, узел, компонент.
Класс (Class) – это описание совокупности объектов с общими атрибутами, операциями, отношениями и семантикой. Класс реализует один или несколько интерфейсов. Класс графически изображается в виде прямоугольника с прямыми углами, разделенного на три части. Верхняя часть содержит имя класса. Средняя секция содержит список атрибутов. Нижняя (если есть) содержит описание поведения (список методов).
Объект (Object) – это экземпляр сущности, представленной классом.
Интерфейс (Interface) – это совокупность методов, которые определяют сервис (набор услуг), предоставляемый классом или компонентом. Графически интерфейс изображается в виде круга, под которым написано его имя.
Компонент (Component) – это физическая заменяемая часть системы, которая соответствует некоторому набору интерфейсов и обеспечивает его реализацию. Графически компонент изображается в виде прямоугольника с вкладками, содержащего обычно только имя.
Узел (Node) – это физический элемент, существующий во время выполнения приложения и представляющий собой тип вычислительного устройства. Графически узел изображается в виде куба.
Атрибуты в UML могут характеризоваться одним или несколькими параметрами:
1. Видимость. В терминах объектно-ориентированного кода видимость имеет три уровня:
- public (+) – открытый для всех;
- protected (#) – защищенный, виден только для потомков данного класса;
- private (-) – закрытый для других классов.
2. Имя – обязательное свойство (не допускаются пробелы).
3. Множественность. Объектная ориентация UML снимает ограничение реляционной модели, допускающей только одно значение атрибута для одного объекта.
4. Тип данных атрибута (число, символ и т. д.).
5. Значение по умолчанию.
6. Стереотип. Представляет собой дополнительный элемент, позволяющий расширяющий стандартный словар
|
|
|
