 |


Математическая постановка задачи классификации информационных сообщений СМИ
|
|
|
|
Пусть дано множество статей Х, множество ключевых слов статьи W и множество названий статей A. Каждое множество описывается своим набором элементов:
X = {x1, x2, …, xc},
где xi – i- я статья;
c – количество статей;
W = {w1, w2, …, wc},
где wi – строка ключевых слов i-ой статьи,  ;
;
A = {a1, a2, … ac},
где ai – название i-ой статьи,  .
.
Имеется рубрикатор, состоящий из четырех уровней:
R1 = {r11, r12, … r1k},
где k – количество элементов рубрикатора 1;
R2 = {r21, r22, … r2l},
где l – количество элементов рубрикатора 2;
R3 = {r31, r32, … r3m},
где m – количество элементов рубрикатора 3;
R4 = {r41, r42, … r4n},
где n – количество элементов рубрикатора 4.
К каждому элементу рубрикаторов 3-го и 4-го уровней привязаны словари со своими множествами:
D3j = {d31j, d32j, … d3yj},  ;
;
D4j = {d41j, d42j, … d4zj},  ,
,
где j – индекс элемента рубрики;
y, z – количество элементов в словаре для конкретной рубрики.
Функция нечеткого поиска задается следующим образом:

здесь U = {{X},{W},{A}};
dpqj – ключевое слово,
где j – индекс элемента рубрики,  или
или  ;
;
p – уровень рубрикатора 3-й или 4-й;
q – индекс элементов в словарях D3j и D4j;
 или
или  ;
;
pн.п – порог нечеткого поиска.
Далее для каждой статьи применяем функцию нечеткого поиска:

где  - общее количество совпадений по i-ой статье из словаря 3-го и 4-го уровней;
- общее количество совпадений по i-ой статье из словаря 3-го и 4-го уровней;
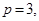
 ;
;
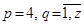 .
.
Затем для ключевых слов статьи также применяем функцию нечеткого поиска:

где  общее количество совпадений по строке ключевых слов i-ой статьи из словаря 3-го и 4-го уровней;
общее количество совпадений по строке ключевых слов i-ой статьи из словаря 3-го и 4-го уровней;

 ;
;
 .
.
Для названий статей тоже применяем функцию нечеткого поиска:

где  - общее количество совпадений по названию i-ой статьи из словаря 3-го и 4-го уровней;
- общее количество совпадений по названию i-ой статьи из словаря 3-го и 4-го уровней;
|
|
|
;
.
Далее для отнесения каждой статьи к той или иной рубрике используется метод ранжирования. Для этого определяются границы трех интервалов:
1) статью однозначно нельзя отнести к рубрике;
2) консультант ОТОИ принимает решение о принадлежности статьи к данной рубрике;
3) статья с заданной вероятностью относится к данной рубрике.
Границей является количество слов, которые должны встретиться в тексте, названии статьи или в списке ключевых слов, относящихся к этой статье.
Метод ранжирования заключается в следующем:

где  границы интервалов по тексту i-ой статьи;
границы интервалов по тексту i-ой статьи;
 границы интервалов по строке ключевых слов i-ой статьи;
границы интервалов по строке ключевых слов i-ой статьи;
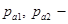 границы интервалов по названию i-ой статьи.
границы интервалов по названию i-ой статьи.
Описание метода нечеткого поиска
Для нечеткого поиска информации используется алгоритм, основанный на процентном отношении совпадения двух строк. Процесс поиска начинается со сравнения каждого элемента одной строки с каждым элементом другой и заканчивается сравнением строк целиком. Эта процедура повторяется дважды для одной и той же пары строк. В первом случае первая строка принимается за эталон, во втором – вторая. В процессе сравнения подсчитывается число совпадений и общее число рассматриваемых случаев, после чего вычисляется их процентное соотношение. На основе этого соотношения принимается решение – считать найденную информацию удовлетворяющей условиям поиска или нет. Описанная процедура применяется ко всем записям информационной базы, в результате пользователь получает всю информацию, удовлетворяющую запросу.
Изменяя минимальный процент совпадения можно уменьшать или увеличивать точность соответствия найденной информации искомой. В данной системе используется 50% совпадения, так как (из практики) этого достаточно для нахождения информации. Схема программы поиска данных по алгоритму нечеткого поиска приведена на рисунке 4.2.1, схема программы сравнения строк приведена на рисунке 4.2.2.
|
|
|

Рисунок 4.2.1 - Схема программы поиска данных по алгоритму нечеткого поиска

Рисунок 4.2.2 - Схема программы сравнения строк «Matching»
Описание запросов
Для данной работы необходимо создать следующие запросы: «Рубрикатор», «Классификация 3-го уровня», «Классификация 4-го уровня», «Классифицированные сообщения», «Обработанные сообщения 3-го уровня», «Обработанные сообщения 4-го уровня».
Запрос «Рубрикатор» необходим для вывода всей информации по всем уровням рубрикатора и словарям 3-го и 4-го уровней. Структура запроса «Рубрикатор» в режиме SQL:
SELECTРубрикатор_1.Индекс_1,Рубрикатор_2.Индекс_2,Рубрикатор_3.Индекс_3, IIf(IsNull([Индекс_4]),0,[Индекс_4])ASИндекс_4,Trim(Str([Рубрикатор_1].[Индекс_1]))+"."+Trim(Str([Рубрикатор_2]
[Индекс_2]))+"."+Trim(Str([Рубрикатор_3].[Индекс_3]))+"."+Trim(Str(IIf(IsNull([Индекс_4]),0,[Индекс_4])))+"."AS Индекс, Рубрикатор_1.Наименование_1,Рубрикатор_2.Наименование_2,Рубрикатор_3.Наименование_3, Рубрикатор_4. Наименование_4, Рубрикатор_1.Код_1, Рубрикатор_2.Код_2, Рубрикатор_3.Код_3, Рубрикатор
_4.Код_4
FROM ((Рубрикатор_1 LEFT JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1= Рубрикатор_2.Код_1) LEFT JOIN Рубрикатор_3 ON Рубрикатор_2.Код_2 = Рубрикатор_3.Код_2) LEFT JOIN Рубрикатор_4 ON Рубрикатор_3.
Код_3 = Рубрикатор_4.Код_3
ORDER BY Рубрикатор_1.Индекс_1,Рубрикатор_2.Индекс_2,Рубрикатор_3.Индекс_3, IIf(IsNull ([Индекс_4]), 0,[Индекс_4]);
Запрос «Классификация 3-го уровня» необходим для вывода информации по результатам классификации по 3-му уровню рубрикатора. Структура запроса «Классификация 3-го уровня» в режиме SQL:
SELECT Trim(Str([Рубрикатор_1].[Индекс_1]))+"."+Trim(Str([Рубрикатор_2].[Индекс_2]))+"."+Trim(Str([Рубрикатор_
3].[Индекс_3]))+"."ASИндекс,[Рубрикатор_1].[Наименование_1]+"."+[Рубрикатор_2].[Наименование_2]+"."+[Рубрикатор_3].[Наименование_3]ASНаименованиерубрики,[Классификация].[Уровеньрубрики], [Классификация].
[Наименование статьи], [Классификация].[Текст статьи], [Классификация].[Ключевые слова], [Классификация]. [Результат], [Классификация].[Код статьи], [Рубрикатор_3].[Код_3] AS Код статьи
FROM (Рубрикатор_1 INNER JOIN Рубрикатор_2 ON [Рубрикатор_1].[Код_1]=[Рубрикатор_2].[Код_1]) INNER JOIN (Рубрикатор_3 INNER JOIN Классификация ON [Рубрикатор_3].[Код_3]=[Классификация].[Код рубрики]) ON [Рубрикатор_2].[Код_2]=[Рубрикатор_3].[Код_2]
|
|
|
WHERE ((([Классификация].[Уровень рубрики])=3));
Запрос «Классификация 4-го уровня» необходим для вывода информации по результатам классификации по 4-му уровню рубрикатора. Структура запроса «Классификация 4-го уровня» в режиме SQL:
SELECT Trim(Str(Рубрикатор_1.Индекс_1))+"."+Trim(Str(Рубрикатор_2.Индекс_2))+"."+Trim(Str(Рубрикатор_3.
Индекс_3))+"."+Trim(Str(Рубрикатор_4.Индекс_4))+"."ASИндекс,Рубрикатор_1.Наименование_1+". "+Рубрикатор
_2.Наименование_2+". "+Рубрикатор_3.Наименование_3+"."+Рубрикатор_4.Наименование_4 AS Наименование рубрики, Классификация.Уровень рубрики, Классификация.Наименование статьи, Классификация.Текст статьи, Классификация.Ключевые слова, Классификация.Результат, Классификация.Код рубрики, Рубрикатор_4.Код_4 AS Код статьи FROM ((Рубрикатор_1 INNER JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1=Рубрикатор_2.Код_1) INNER JOIN Рубрикатор_3 ON Рубрикатор_2.Код_2=Рубрикатор_3.Код_2) INNER JOIN (Рубрикатор_4 INNER JOIN Классификация ON Рубрикатор_4.Код_4=Классификация.Код рубрики) ON Рубрикатор_3.Код_3=
Рубрикатор_4.Код_3 WHERE (((Классификация.Уровень рубрики)=4));
Запрос «Классифицированные сообщения» необходим для создания отчета по результатам классификации. Структура запроса «Обработанные сообщения» в режиме SQL:
SELECT DISTINCT Статьи.Код статьи
FROM Статьи INNER JOIN Рубрики ON Статьи.Код статьи = Рубрики.Код рубрики;
Запрос «Обработанные сообщения 3-го уровня» необходим для вывода информации по обработанным сообщениям СМИ, отнесенным к 3-му уровню рубрикатора. Структура запроса «Обработанные сообщения 3-го уровня» в режиме SQL:
SELECT Trim(Str(Рубрикатор_1.Индекс_1))+"."+Trim(Str(Рубрикатор_2.Индекс_2))+"."+Trim(Str(Рубрикатор_3
.Индекс_3))+"." AS Индекс, Статьи.Файл, Статьи.Код газеты, Статьи.Код региона, Статьи.Код статьи, Статьи.Наименование статьи, Статьи.Ключевые слова, Статьи.Текст статьи, Статьи.Дата, Статьи.автор, Статьи.Код рубрики, Статьи.Уровень рубрики, Рубрикатор_1.Наименование_1+"."+Рубрикатор_2.Наименование
|
|
|
_2+". "+Рубрикатор_3. Наименование_3 AS Наименование рубрики
FROM (Рубрикатор_1 INNER JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1 = Рубрикатор_2.Код_1) INNER JOIN (Рубрикатор_3 INNER JOIN Стать ON Рубрикатор_3.Код_3 = Статьи.Код рубрики) ON Рубрикатор_2.Код_2 = Рубрикатор_3.Код_2
WHERE (((Статьи.Уровень рубрики)=3));
Запрос «Обработанные сообщения 4-го уровня» необходим для вывода информации по обработанным сообщениям СМИ, отнесенным к 4-му уровню рубрикатора. Структура запроса «Обработанные сообщения 4-го уровня» в режиме SQL:
SELECT Trim(Str(Рубрикатор_1.Индекс_1))+"."+Trim(Str(Рубрикатор_2.Индекс_2))+"."+Trim(Str(Рубрикатор_3.
Индекс_3))+"."+Trim(Str(Рубрикатор_4.Индекс_4))+"." AS Индекс, Статьи.Файл, Статьи.Код газеты, Статьи.Код региона, Статьи.Код рубрики, Статьи.Наименование статьи, Статьи.Ключевые слова, Статьи.Текст статьи, Статьи.Дата, Статьи.автор, Статьи.Код рубрики, Статьи.Уровень рубрики, Рубрикатор_1.Наименование_1+". "+Рубрикатор_2.Наименование_2+". "+Рубрикатор_3.Наименование_3+"."+Рубрикатор_4.Наименование_4 AS Наименование рубрики
FROM ((Рубрикатор_1 INNER JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1=Рубрикатор_2.Код_1) INNER JOIN Рубрикатор_3 ON Рубрикатор_2.Код_2=Рубрикатор_3.Код_2) INNER JOIN (Рубрикатор_4 INNER JOIN Статьи ON Рубрикатор_4.Код_4=Статьи.Код рубрики) ON Рубрикатор_3.Код_3=Рубрикатор_4.Код_3
WHERE (((Статьи.Уровень рубрики)=4));
|
|
|
