 |


Измерение связи и значимости для порядковых переменных
|
|
|
|
Для порядковых переменных чаще всего используется коэффициент связи G, или гамма, работающий по тому же принципу ограничения ошибки, что и λ, но особо ценный тем, что он не просто определяет количество признаков в той или иной категории, а ранжируетих, т.е. выясняет их относительную позицию. Вопрос, решаемый с помощью G, состоит в том, какова степень, до которой ранжирование случаев одной порядковой переменной может быть определено при условии знания рангов случаев другой порядковой переменной.
Когда мы анализируем две подобные переменные, то возможны два случая зависимости. Первый, при котором случаи ранжируются в одном и том же порядке в обеих переменных (большие значения – с большими, меньшие – не меньшими), называется полное согласие. Второй, в котором случаи расположены в прямо противоположном порядке (большие значения одной переменной связаны с меньшими значениями другой и наоборот), называется полная инверсия. Тогда возможность предсказания (т.е.степень связи между двумя переменными) будет следствием того, насколько тесно ранги одной переменной связаны с рангами другой либо по типу “полное соответствие” (если G положительна и приближается к единице), либо но типу “полная инверсия” (если G отрицательна и приближается к –1). Значение коэффициента G, равное 0, [c.423] свидетельствует об отсутствии связи. Формула для исчисления G такова:
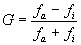
где f а = частота соответствий в ранжировании двух переменных;
f i = частота инверсий в ранжировании двух переменных.
G основана на относительном расположении набора случаев по двум переменным. Случаи сначала располагаются в восходящем порядке по независимой переменной. Затем это сравнивается с порядком расположения по зависимой переменной. Считается, что те переменные, для которых заданный порядок сохраняется, находятся в соответствии, а те, для которых этот порядок меняется на противоположный, связаны по типу инверсии. Недостаток места не позволяет нам рассмотреть эти процедуры детальноили обсудить способы подсчета G для вариантов, когда количество признаков мало и/или между рангами не встречается одинаковых значений (параллелей). Лучше мы подробнее остановимся на процедурах, необходимых для подсчета G для более распространенных условий: когда есть параллели (более одного признака с одним и тем же рангом), а само количество признаков достаточно велико 4.
|
|
|
Здесь, как и ранее, следует обратиться к таблице взаимной сопряженности признаков, такой, какой является табл. 15.5.
Таблица 15.5.
Обобщенная таблица взаимной сопряженности признаков
| Значения независимой переменной | Значения зависимой переменной | ||
| низкие | средние | высокие | |
| Низкие Средние Высокие | a d g | f e h | c f i |
Для того чтобы измерить связь между этими двумя переменными, необходимо определить количество соответствий и инверсий, относящихся к каждой ячейке таблицы. [c.424] Соответствия расположены во всех ячейках под (по направлению к более высоким значениям независимой переменной) и справа (по направлению к более высоким значениям зависимой переменной) от любой определенной ячейки. Так, соответствия относительно случаев ячейки о включают все случаи в ячейках e, f, h и i, поскольку эти случаи имеют более высокие ранги, чем случаи ячейки a по обеим переменным. Инверсии расположены во всех ячейках под (по направлению к более высоким значениям независимой переменной) и слева (по направлению к более низким значениям зависимой переменной) от любой определенной ячейки. Так, инверсии относительно случаев ячейки с включают все случаи в ячейках d, е, g и h поскольку это случаи более высоких по сравнению с ячейкой с значений по одной переменной и более низких – по другой. Частота соответствий (f а в уравнении), таким образом, для каждой ячейки есть сумма всех случаев по каждой ячейке, умноженных на количество случаев во всех ячейках ниже и справа (a [ e+f+h+i ] +b [ f+i ] +e [ i ]). Частота инверсий (f i в уравнении) – это сумма всех случаев по каждой ячейке, умноженная на количество случаев во всех ячейках ниже и слева (b [ d+g ] +c [ d+e+g+h ] +f [ g+h ]). Полученные значения просто подставляются в уравнение.
|
|
|
f a = 45(23+5+2+5)+5(5+5)+2(2+5)+23(5) = 1575+50+14+115 = 1754
f i = 5(2+3)+10(2+23+3+2)+23(3)+5(3+2) = 25+300+69+25 = 419

Эта цифра говорит о том, что во взаимном расположении двух переменных на 61% больше соответствий, чем несоответствий. Если f i превышает f а, G будет иметь отрицательный знак, что означает наличие инверсионного типа взаимосвязей.
Проверка статистической значимости коэффициента основана на том факте, что распределение G в выборке из совокупности, где нет значимых связей, приближается к нормальному, так же как распределение гипотетического коэффициента в выборке, которую мы обсуждали раньше. Если это так, то мы можем проверить, не является ли [c.425] любое конкретное значение G следствием случайности, путем вычисления его стандартной оценки (z), определения ее расположения под нормальной кривой и оценки таким образом этой возможности. Целиком подсчет zG (стандартной оценки гаммы) здесь не будет представлен, поскольку формула сложна и ее понимание требует более детального знания статистики по сравнению с уровнем нашей книги. Некоторые сведения о формуле можно найти в книге Фримана (см. прим. 1), и ее подсчет предусмотрен такими пакетами прикладных программ, как SPSS. Достаточно сказать, что когда G превышает ±1645 (когда G удалена от медианы на 1645 единиц стандартного отклонения), G достаточна, чтобы иметь доверительный уровень в 0,05, а если zg превышает ±2326 (когда G удалена от медианы в том или ином направлении на 2326 единиц стандартного отклонения), G достигает значимости на уровне 0,01. Интерпретация этих результатов та же, что в приведенном выше, более общем примере. [c.426]
|
|
|
