 |


Пользовательские потоки и потоки ядра
|
|
|
|
Потоки (threads) и многопоточное выполнение программ (multi-threading)
Однопоточные и многопоточные процессы
Последовательный (однопоточный) процесс – это процесс, который имеет только один поток управления (control flow), характеризующийся изменением его счетчика команд. Поток (thread) – это запускаемый из некоторого процесса особого рода параллельный процесс, выполняемый в том же адресном пространстве, что и процесс-родитель. Схема организации однопоточного и многопоточного процессов изображена на рис. 1.

Рис. 11. Однопоточный и многопоточный процессы.
Как видно из схемы, однопоточный процесс использует, как обычно, код, данные в основной памяти и файлы, с которыми он работает. Процесс также использует определенные значения регистров и стек, на котором исполняются его процедуры. Многопоточный процесс организован несколько сложнее. Он имеет несколько параллельных потоков, для каждого из которых ОС создает свой стек и хранит свои собственные значения регистров. Потоки работают в общей основной памяти и используют то же адресное пространство, что и процесс-родитель, а также разделяют код процесса и файлы.
Многопоточность имеет большие преимущества:
- Увеличение скорости (по сравнению с использованием обычных процессов). Многопоточность основана на использовании облегченных процессов (lightweight processes),работающих в общем пространстве виртуальной памяти. Благодаря многопоточности, не возникает больше неэффективных ситуаций, типичных для классической системы UNIX.
- Использование общих ресурсов. Потоки одного процесса используют общую память и файлы.
- Экономия. Благодаря многопоточности, достигается значительная экономия памяти, по причинам, объясненным выше. Также достигается и экономия времени, так как переключение контекста на облегченный процесс, для которого требуется только сменить стек и восстановить значения регистров, значительно быстрее, чем на обычный процесс.
Использование мультипроцессорных архитектур. Это особенно важно в настоящее время, в период широкого использования многоядерных гибридных и многопроцессорных систем. Именно многопоточность программ, основанная на многоядерности процессора, дает возможность, наконец, почувствовать реальные преимущества параллельного выполнения.
|
|
|
Пользовательские потоки и потоки ядра
Модели многопоточности. Реализация многопоточности в ОС, как и многих других возможностей, имеет несколько уровней абстракции. Самый высокий из них – пользовательский уровень. С точки зрения пользователя и его программ, управление потоками реализовано через библиотеку потоков пользовательского уровня (user threads) Отметим, что существует несколько моделей потоков пользовательского уровня.
Низкоуровневые потоки, в которые отображаются пользовательские потоки, называются потоками ядра (kernel threads). Они поддержаны и используются на уровне ядра операционной системы. Как и подходы к пользовательским потокам, подходы к архитектуре и реализации системных потоков и к отображению пользовательских потоков в системные в разных ОС различны. Например, собственные модели потоков ядра со своей спецификой реализованы в следующих ОС:
- Windows 95/98/NT/2000/XP/2003/2008/7;
- Solaris;
- Tru64 UNIX;
- BeOS;
- Linux.
Существуют различные модели многопоточности – способы отображения пользовательских потоков в потоки ядра. Теоретически возможны (и на практике реализованы) следующие модели многопоточности:
- Модель много / один (many-to-one) – отображение нескольких пользовательских потоков в один и тот же поток ядра. Используется в операционных системах, не поддерживающих множественные системные потоки (например, с целью экономии памяти). Данная модель изображена на рис. 2.
|
|
|
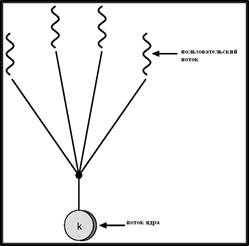
Рис. 10.2. Схема модели многопоточности "много / один".
- Модель один / один (one-to-one) – взаимно-однозначное отображение каждого пользовательского потока в определенный поток ядра. Примеры ОС, использующих данную модель, - Windows 95/98/NT/2000/XP/2003/2008/7; OS/2. Данная модель изображена на рис. 3.

Рис. 10.3. Схема модели многопоточности "один / один".
- Модель много / много (many-to-many) – модель, допускающая отображение нескольких пользовательских потоков в несколько системных потоков. Такая модель позволяет ОС создавать большое число системных потоков. Характерным примером ОС, использующей подобную модель, является ОС Solaris, а также Windows NT / 2000 / XP / 2003 / 2008 / 7 с пакетом ThreadFiber. Данная модель изображена на рис. 4.

Рис. 4. Схема модели многопоточности "много / много".
Потоки в Windows 2000
Как уже отмечалось, в системе Windows реализована модель многопоточности "один / один". Каждый поток содержит:
- идентификатор потока (thread id);
- набор регистров
- отдельные стеки для пользовательских и системных процедур;
- область памяти для локальных данных потока (thread-local storage – TLS).
Проблемы многопоточности
Многопоточность – весьма сложная, еще не полностью изученная и, тем более, не полностью формализованная область, в которой имеется много интересных проблем. Рассмотрим некоторые из них.
Семантика системных вызовов fork() и exec(). Как уже отмечалось, в классической ОС UNIX системный вызов fork создает новый "тяжеловесный" процесс со своим адресным пространством, что значительно "дороже", чем создание потока. Однако, с целью поддержания совместимости программ снизу вверх, приходится сохранять эту семантику, а многопоточность вводить с помощью новых системных вызовов.
Прекращение потоков. Важной проблемой является проблема прекращения потоков: например, если родительский поток прекращается, то должен ли при этом прекращаться дочерний поток? Если прекращается стандартный процесс, создавший несколько потоков, то должны ли прекращаться все его потоки? Ответы на эти вопросы в разных ОС неоднозначны.
Обработка сигналов. Сигналы в UNIX – низкоуровневый механизм обработки ошибочных ситуаций. Примеры сигналов: SIGSEGV -нарушение сегментации (обращение по неверному адресу, чаще всего по нулевому); SIGKILL – сигнал процессу о выполнении команды kill его уничтожения. Пользователь может определить свою процедуру-обработчик сигнала системным вызовом signal. Проблема в следующем: как распространяются сигналы в многопоточных программах и каким потоком они должны обрабатываться? В большинстве случаев этот вопрос решается следующим образом: сигнал обрабатывается потоком, в котором он сгенерирован, и влияет на исполнение только этого потока. В более современных ОС (например, Windows 2000 и более поздних версиях Windows), основанных на объектно-ориентированной методологии, концепция сигнала заменена более высокоуровневой концепцией исключения (exception). Исключение распространяется по стеку потока в порядке, обратном порядку вызовов методов, и обрабатывается первым из них, в котором система находит подходящий обработчик. Аналогичная схема обработки исключений реализована в Java и в.NET.
|
|
|
Группы потоков. В сложных задачах, например, задачах моделирования, при большом числе разнородных потоков, возникает потребность в их структурировании и помощью концепции группы потоков – совокупности потоков, имеющей свое собственное имя, над потоками которой определены групповые операции. Наиболее удачно, с нашей точки зрения, группы потоков реализованы в Java (с помощью класса ThreadGroup). Следует отметить также эффективную реализацию пулов потоков (ThreadPool) в.NET.
Локальные данные потока (thread-local storage - TLS) – данные, принадлежащие только определенному потоку и используемые только этим потоком. Необходимость в таких данных очевидна, так как многопоточность – весьма важный метод распараллеливания решения большой задачи, при котором каждый поток работает над решением порученной ему части. Все современные операционные системы и платформы разработки программ поддерживают концепцию локальных данных потока.
Синхронизация потоков. Поскольку потоки, как и процессы могут использовать общие ресурсы и реагировать на общие события, необходимы средства их синхронизации.
|
|
|
Тупики (deadlocks) и их предотвращение. Как и процессы, потоки могут взаимно блокировать друг друга (т.е. может создаться ситуация deadlock), при их неаккуратном программировании.
42. Файловые системы. Обзор.
Напомним, что под файлом обычно понимают набор данных, организованных в виде совокупности записей одинаковой структуры. Для управления этими данными создаются соответствующие системы управления файлами. Возможность иметь дело с логическим уровнем структуры данных и операций, выполняемых над ними в процессе их обработки, предоставляет файловая система. Таким образом,
Файловая система – это набор спецификаций и соответствующее им программное обеспечение, которые отвечают за создание, уничтожение, организацию, чтение, запись, модификацию и перемещение файловой информации, а также за управление доступом к файлам и за управление ресурсами, которые используются файлами. Именно файловая система определяет способ организации данных на диске или на каком-нибудь ином носителе данных. В качестве примера можно привести файловую систему FAT, реализация для которой имеется в абсолютном большинстве ОС, работающих в современных ПК1.
Система управления файлами является основной подсистемой в абсолютном большинстве современных операционных систем, хотя в принципе можно обходиться и без неё. Во-первых, через систему управления файлами связываются по данным все системные обрабатывающие программы. Во-вторых, с помощью этой системы решаются проблемы централизованного распределения дискового пространства и управления данными. В-третьих, благодаря использованию той или иной системы управления файлами пользователям предоставляются следующие возможности:
- ♦ создание, удаление, переименование (и другие операции) именованных наборов данных (именованных файлов) из своих программ или посредством специальных управляющих программ, реализующих функции интерфейса пользователя с его данными и активно использующих систему управления файлами;
- ♦ работа с не дисковыми периферийными устройствами как с файлами;
- ♦ обмен данными между файлами, между устройствами, между файлом и уст-
ройством (и наоборот);
- ♦ работа с файлами с помощью обращений к программным модулям системы
управления файлами (часть API ориентирована именно на работу с файлами);
- ♦ защита файлов от несанкционированного доступа.
В некоторых ОС может быть несколько систем управления файлами, что обеспечивает им возможность работать с несколькими файловыми системами. Можно сказать, что основное назначение файловой системы и соответствующей ей системы управления файлами – организация удобного доступа к данным, организованным как файлы, то есть вместо низкоуровневого доступа к данным с указанием конкретных физических адресов нужной нам записи используется логический доступ с указанием имени файла и записи в нём.
|
|
|
Другими словами, термин «файловая система» определяет, прежде всего,
принципы доступа к данным, организованным в файлы. Этот же термин часто ис-
пользуют и по отношению к конкретным файлам, расположенным на том или ином
носителе данных. А термин «система управления файлами» следует употреблять
по отношению к конкретной реализации файловой системы, то есть это – комплекс
программных модулей, обеспечивающих работу с файлами в конкретной операци-
онной системе.
Следует ещё раз заметить, что любая система управления файлами не сущест-
вует сама по себе – она разработана для работы в конкретной ОС. В качестве при-
мера можно сказать, что всем известная файловая система FAT (file allocation table)
имеет множество реализации как система управления файлами. Так, система, полу-
чившая это название и разработанная для первых персональных компьютеров, на-
зывалась просто FAT (сейчас её называют FAT-12). Её разрабатывали для работы с
дискетами, и некоторое время она использовалась при работе с жесткими дисками.
Потом её усовершенствовали для работы с жесткими дисками большего объёма, и
эта новая реализация получила название FAT-16. Это название файловой системы
мы используем и по отношению к системе управления файлами самой MS-DOS.
Реализацию же системы управления файлами для OS/2, которая использует основ-
ные принципы системы FAT, называют super-FAT; основное отличие – возмож-
ность поддерживать для каждого файла расширенные атрибуты. Есть версия системы управления файлами с принципами FAT и для Windows 95/98, для Windows
NT и т. д. Другими словами, для работы с файлами, организованными в соответствии с некоторой файловой системой, для каждой ОС должна быть разработана соответствующая система управления файлами. Эта система управления файлами будет работать только в той ОС, для которой она и создана; но при этом она позволит работать с файлами, созданными с помощью системы управления файлами другой ОС, работающей по тем же основным принципам файловой системы.
Файловая система FAT
Как мы уже отмечали, аббревиатура FAT (file allocation table) расшифровывается как «таблица размещения файлов». Этот термин относится к линейной табличной структуре со сведениями о файлах – именами файлов, их атрибутами и другими данными,
определяющими местонахождение файлов (или их фрагментов) в среде FAT. Элемент FAT определяет фактическую область диска, в которой хранится начало физического файла. В файловой системе FAT логическое дисковое пространство любого логиче-
ского диска делится на две области (рис. 4.6): системную область и область дан-
ных.
Рис.4.6. Структура логического диска
R | Sec | Fat1 | Fat2 | Dir | Каталоги и файлы
________________________________________________________
Системная область | Область данных
Системная область логического диска создается и инициализируется при форматировании, а впоследствии обновляется при манипулировании файловой структурой. Область данных логического диска содержит файлы и каталоги, подчинённые корневому. Она, в отличие от системной области, доступна через пользовательский интерфейс DOS. Системная область состоит из следующих компонентов, расположенных в логическом адресном пространстве подряд:
- загрузочной записи (boot record, BR);
- зарезервированных секторов (reserved sector, ResSecs);
- таблицы размещения файлов (file allocation table, FAT);
- корневого каталога (root directory, RDir).
Таблица размещения файлов
Таблица размещения файлов является очень важной информационной структурой. Можно сказать, что она представляет собой карту (образ) области данных, в которой описывается состояние каждого участка области данных. Область данных разбивают на так называемые кластеры. Кластер представляет собой один или несколько смежных секторов в логическом дисковом адресном пространстве (точнее – только в области данных). В таблице FAT кластеры, принадлежащие одному файлу (некорневому каталогу), связываются в цепочки. Для указания номера кластера и системе управления файлами FAT-16 используется 16-битовое слово, следовательно, можно иметь до 216 = 65536 кластеров (с номерами от 0 до 65535). Кластер – это минимальная адресуемая единица дисковой памяти, выделяемая файлу (или некорневому каталогу). Файл или каталог занимает целое число кластеров. Последний кластер при этом может быть задействован не полностью, что приведет к заметной потере дискового пространства при большом размере кластера. На дискетах кластер занимает один или два сектора, а на жёстких дисках – в зависимости от объёма раздела.
FAT32 — последняя версия файловой системы FAT и улучшение предыдущей версии, известной как FAT16. Она была создана, чтобы преодолеть ограничения на размер тома в FAT16, позволяя при этом использовать старый код программ MS-DOS и сохранив формат. FAT32 использует 32-разрядную адресацию кластеров. FAT32 появилась вместе с Windows 95 OSR2.
NTFS (от англ. New Technology File System — «файловая система новой технологии») — стандартная файловая система для семейства операционных систем Microsoft Windows NT.
NTFS заменила использовавшуюся в MS-DOS и Microsoft Windows файловую систему FAT. NTFS поддерживает системуметаданных
и использует специализированные структуры данных для хранения информации о файлах для улучшения производительности, надёжности и эффективности использования дискового пространства. NTFS хранит информацию о файлах в главной файловой таблице — Master File Table (MFT). NTFS имеет встроенные возможности разграничивать доступ к данным для различных пользователей и групп пользователей (списки контроля доступа — Access Control Lists (ACL)), а также назначать квоты (ограничения на максимальный объём дискового пространства, занимаемый теми или иными пользователями). NTFS использует систему журналирования USN для повышения надёжности файловой системы.
43. Управление памятью в операционной системе. Типы адресов.
Основную (оперативную) память компьютерной системы можно рассматривать как большой массив слов или байтов, каждый из которых имеет свой адрес. Память - это хранилище данных с быстрым доступом, совместно используемое процессором и устройствами ввода-вывода.
Следует иметь в виду важную особенность основной памяти. В компьютерных архитектурах имеется два различных способа нумерации байтов в слове. По традиции будем представлять себе память как линейный массив, расположенный "слева направо", такой, что адреса слов, находящихся левее, меньше, чем адреса слов, находящихся правее. Каждое слово делится на байты, имеющие в слове свои номера – 0, 1 и т.д.. Например, в 64-разрядных системах в слове 8 байтов, с номерами от 0 до 7, в более старых 16-разрядных (x86) – два байта, с номерами 0 и 1. Если нумерация байтов в слове начинается слева, т.е. начиная со старших битов, то такую архитектуру принято называть big endian, если же справа, т.е. начиная с младших битов, то little endian. Например, при big endian – архитектуре 32-разрядного процессора байты двух соседних слов памяти нумеруются так: 0, 1, 2, 3, 0, 1, 2, 3. При little endian же архитектуре нумерация будет иной: 3, 2, 1, 0, 3, 2, 1, 0. Представим теперь, что мы хотим рассматривать эти же два слова как массив байтов длиной 8 и записать туда байт за байтом символы строки: "ЭТОТЕКСТ" (всего – 8 символов). Такая операция при обеих архитектурах будет выполнена одинаково, т.е. последовательные байты получат именно эти значения. Затем рассмотрим результат снова, но уже как последовательность их двух слов. Каково будет содержимое этих слов? При big endian – архитектуре сюрпризов не будет: первое слово – " ЭТОТ", второе "ЕКСТ". Однако при little endian – архитектуре результат будет совсем иным: первое слово – "ТОТЭ", второе – " ТСКЕ"! Не забудем, что при обработке целого слова в little endian – архитектуре байты как бы "переставляются" в обратном порядке. Разумеется, это неудобно. С подобной проблемой автор столкнулся при переносе написанного им компилятора с архитектуры SPARC (big endian) на архитектуру Intel x86 (little endian), используя типы byte и word на Турбо-Паскале. Подобная операция типична для системных программ, например, таблица идентификаторов в компиляторе должна содержать как символы идентификатора (последовательность байтов), так и другую информацию о нем (длину, ссылки в различные таблицы и т.д.). Поэтому при little endian – архитектуре приходится хранить и обрабатывать байтовые массивы и массивы слов отдельно, и нельзя изменять точку зрения на одну и ту же область памяти и рассматривать ее то как массив байтов, то как массив слов.
Пример little endian – архитектуры – x86. Пример big endian – архитектуры – SPARC. При программировании на языках высокого уровня разработчику, как правило, не приходится учитывать это различие. Однако если при реализации распределения памяти требуется одну и ту же область памяти рассматривать то как массив слов, то как массив байтов, то для little endian – архитектур могут быть "сюрпризы", связанные с тем, что при записи в память как в массив слов байты как бы переставляются.
Основная память – это неустойчивое (volatile) устройство памяти. Ее содержимое теряется при сбое системы или при выключении питания. Для организации устойчивой памяти используются другие, более медленные технологии.
ОС отвечает за следующие действия, связанные с управлением памятью:
- Отслеживание того, какие части памяти в данный момент используются и какими процессами. Как правило, ОС организует для каждого процесса свою виртуальную память – расширение основной памяти путем хранения ее образа на диске и организации подкачки в основную память фрагментов (страниц или сегментов) виртуальной памяти процесса и ее откачки по мере необходимости.
- Стратегия загрузки процессов в основную память, по мере ее освобождения. При активизации процесса и его запуске или продолжении его выполнения процесс должен быть загружен в основную память, что и осуществляется операционной системой. При этом, возможно, какие-либо не активные в данный момент процессы приходится откачивать на диск.
- Выделение и освобождение памяти по мере необходимости. ОС обслуживает запросы вида "выделить область основной памяти длиной n байтов" и "освободить область памяти, начинающуюся с заданного адреса, длиной m байтов". Длина участков выделяемой и освобождаемой памяти может быть различной. ОС хранит список занятой и свободной памяти. При интенсивном использовании памяти может возникнуть ее фрагментация – дробление на мелкие свободные части, вследствие того, что при запросах на выделение памяти длина найденного сегмента оказывается немного больше, чем требуется, и остаток сохраняется в списке свободной памяти как область небольшого размера (подчас всего 1 – 2 слова). В курсе рассмотрены различные стратегии управления памятью и борьбы с фрагментацией. При исчерпании основной памяти ОС выполняет сборку мусора – поиск не используемых фрагментов, на которые потеряны ссылки, и уплотнение (компактировку) памяти – сдвиг всех используемых фрагментов по меньшим адресам, с корректировкой всех адресов.
Типы адресов
Для идентификации переменных и команд используются символьные имена (метки), виртуальные адреса и физические адреса (рисунок 2.7).
Символьные имена присваивает пользователь при написании программы на алгоритмическом языке или ассемблере.
Виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Так как во время трансляции в общем случае не известно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Каждый процесс имеет собственное виртуальное адресное пространство. Максимальный размер виртуального адресного пространства ограничивается разрядностью адреса, присущей данной архитектуре компьютера, и, как правило, не совпадает с объемом физической памяти, имеющимся в компьютере.

Рис. 2.7. Типы адресов
Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами. В первом случае замену виртуальных адресов на физические делает специальная системная программа - перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной транслятором об адресно-зависимых константах программы, выполняет загрузку программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, при этом операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку памяти. Вместе с тем использование перемещающего загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае - каждый раз при обращении по данному адресу.
В некоторых случаях (обычно в специализированных системах), когда заранее точно известно, в какой области оперативной памяти будет выполняться программа, транслятор выдает исполняемый код сразу в физических адресах.
44. Методы распределения памяти без использования дискового пространства.
Все методы управления памятью могут быть разделены на два класса: методы, которые используют перемещение процессов между оперативной памятью и диском, и методы, которые не делают этого (рисунок 2.8). Начнем с последнего, более простого класса методов.

Рис. 2.8. Классификация методов распределения памяти
|
|
|
