 |


Методики создания компилятора
|
|
|
|
Написание компилятора может потребоваться в самых разнообразных условиях - для различных языков, целевых платформ, с различными требованиями к работе компилятора и т.д. Например, одна из типичных проблем написания компилятора связана с тем, что на целевой платформе могут отсутствовать подходящие средства для разработки. Именно так обычно обстоят дела при создании новой компьютерной архитектуры: на начальном этапе жизни компьютера системные программисты не имеют никаких средств разработки, кроме системы команд самого компьютера (на этом этапе даже ассемблер может отсутствовать). Бывают и такие случаи, когда компилятор создается для еще не существующей целевой платформы.
Таким образом, цели и условия написания компиляторов могут очень сильно варьироваться от одного проекта к другому. Поэтому существует целый ряд методик разработки компиляторов; мы остановимся на наиболее распространенных из них:
- прямой, в котором целевым языком и языком реализации является язык ассемблера
- метод раскрутки
- использование кросс-трансляторов
- использование виртуальных машин
- компиляция "на лету"
Метод раскрутки

Компилятор - это весьма большая и сложная программа; на написание и отладку компилятора на языке ассемблера можно истратить слишком много времени. Для того, чтобы как-то справиться с этой проблемой, был придуман метод раскрутки, суть которого заключается в следующем.
Пусть есть компилятор  , где P - некоторый язык более высокого уровня, чем язык ассемблера. Тогда напишем
, где P - некоторый язык более высокого уровня, чем язык ассемблера. Тогда напишем  , а затем применим компилятор
, а затем применим компилятор  к компилятору
к компилятору  , т.е. получим
, т.е. получим  . Такая схема проиллюстрирована с помощью Т-диаграмм на слайде и называется раскруткой (bootstrapping 1) ); компилятор как бы "раскручивается" с помощью компилятора .
. Такая схема проиллюстрирована с помощью Т-диаграмм на слайде и называется раскруткой (bootstrapping 1) ); компилятор как бы "раскручивается" с помощью компилятора .
|
|
|
Описанная схема может быть использована при написании компилятора некоторого языка на нем самом. Пусть у нас есть компилятор некоторого подмножества S языка L в язык A, написанный на языке A,  . Тогда мы можем написать
. Тогда мы можем написать  и получим новый компилятор
и получим новый компилятор  . Мы используем это подмножество S для того, чтобы написать компилятор языка L в язык A,
. Мы используем это подмножество S для того, чтобы написать компилятор языка L в язык A,  . Если теперь мы применим компилятор к программе
. Если теперь мы применим компилятор к программе  , то получим
, то получим 
Впервые такая схема была применена в 1960 году при реализации языка Neliac. В 1971 году Вирт написал с использованием раскрутки транслятор языка Pascal, причем самый первый компилятор был оттранслирован вручную. Количество шагов раскрутки было больше 1, т.е. была построена последовательность языков  и построена последовательность компиляторов:
и построена последовательность компиляторов:  .
.
Раскрутку можно использовать и в следующей ситуации. Пусть у нас есть недостаточно эффективный компилятор  . Можно написать более эффективный компилятор , а затем применить раскрутку.
. Можно написать более эффективный компилятор , а затем применить раскрутку.
Кросс-транслятор
Пусть у нас есть два компьютера: компьютер M с языком ассемблера A и компьютер 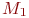 с языком ассемблера
с языком ассемблера  . Кроме того, предположим, что имеется компилятор
. Кроме того, предположим, что имеется компилятор  , а сам компьютер M по каким-то причинам не доступен либо пока еще не существует компилятор . Нас интересует компилятор . В такой ситуации мы можем использовать в качестве инструментальной машины и написать компилятор , который принято называть кросс-транслятором (cross-compiler). Как только машина M станет доступной, мы сможем перенести на M и "раскрутить" его с помощью . Понятно, что это решение достаточно трудоемко, поскольку могут возникнуть проблемы при переносе, например, из-за различий операционных систем.
, а сам компьютер M по каким-то причинам не доступен либо пока еще не существует компилятор . Нас интересует компилятор . В такой ситуации мы можем использовать в качестве инструментальной машины и написать компилятор , который принято называть кросс-транслятором (cross-compiler). Как только машина M станет доступной, мы сможем перенести на M и "раскрутить" его с помощью . Понятно, что это решение достаточно трудоемко, поскольку могут возникнуть проблемы при переносе, например, из-за различий операционных систем.
Под переносимой (portable) программой понимается программа, которая может без перетрансляции выполняться на нескольких (по меньшей мере, на двух) платформах. В связи с этим возникает вопрос о переносимости объектных программ, создаваемых компилятором. Компиляторы, созданные по методикам, рассмотренным выше, порождают непереносимые (non-portable) объектные программы. Поскольку компилятор, в конечном итоге, является программой, то мы можем говорить и о переносимых компиляторах. Одним из способов получения переносимых объектных программ является генерация объектной программы на языке более высокого уровня, чем язык ассемблера. Такие компиляторы иногда называют конвертерами (converter).
|
|
|
52. Фазы компиляции.
Фазы компиляции
Процесс создания компилятора можно свести к решению нескольких задач, которые принято называть фазами компиляции (compilation phases). Обычно компилятор состоит из следующих фаз:
- лексический анализ
- синтаксический анализ
- видозависимый анализ
- оптимизация
- генерация кода.
Сформулируем основные цели каждой из фаз компиляции. Мы продемонстрируем преобразования, которым подвергается исходная программа на перечисленных фазах компиляции, на небольшом примере - мы рассмотрим оператор присваивания position = initial + rate * 60, причем предположим, что все переменные вещественные.
Лексический анализ

Входом компилятора служит программа на исходном языке программирования. С точки зрения компилятора это просто последовательность символов. Задача первой фазы компиляции, лексического анализатора (lexical analysis), заключается в разборе входной цепочки и выделении некоторых более "крупных" единиц, лексем, которые удобнее для последующего разбора. Примерами лексем являются основные ключевые слова, идентификаторы, константные значения (числа, строки, логические) и т.п.
На этапе лексического анализа обычно также выполняются такие действия, как удаление комментариев и обработка директив условной компиляции.
Для отображения некоторых лексем достаточно всего одного числа (это может быть, например, номер ключевого слова согласно внутренней нумерации компилятора), в то время как для записи других лексем может потребоваться пара, состоящая из номера лексического класса и ссылки в таблицу внешних представлений. Хорошая модель лексического анализатора - конечный преобразователь.
Лексический анализ будет подробно рассмотрен в лекции 5.
|
|
|
Синтаксический анализ

Синтаксический анализатор (syntax analyzer, parser) получает на вход результат работы лексического анализатора и разбирает его в соответствии с некоторой грамматикой. Эта грамматика аналогична грамматике, используемой при описании входного языка. Однако грамматика входного языка обычно не уточняет, какие конструкции следует считать лексемами.
Синтаксический анализ является одной из наиболее формализованных и хорошо изученных фаз компиляции. Лекции 4 посвящена математическому аппарату, используемому при описании языков и создании синтаксических анализаторов. Различные методы построения синтаксических анализаторов будут рассмотрены в лекции 6, лекции 7 и лекции 8.
После синтаксического анализа можно считать, что исходная программа преобразована в некоторое промежуточное представление. Некоторые распространенные формы промежуточного представления программы будут рассмотрены в лекции 9. Пока же мы остановимся на одной форме промежуточного представления, которая будет использована в нашем курсе, - на дереве разбора программы (иногда его также называют синтаксическим деревом). В дереве разбора программы внутренние узлы соответствуют операциям, а листья представляют операнды.
Видозависимый анализ

Видозависимый анализ (type checking), иногда также называемый семантическим анализом (semantic analysis), обычно заключается в проверке правильности типов данных, используемых в программе. Кроме того, на этом этапе компилятор должен также проверить, соблюдаются ли определенные контекстные условия входного языка. В современных языках программирования одним из примеров контекстных условий может служить обязательность описания переменных: для каждого использующего вхождения идентификатора должно существовать единственное определяющее вхождение. Другой пример контекстного условия: число и атрибуты фактических параметров вызова процедуры должны быть согласованы с определением этой процедуры.
|
|
|
Такие контекстные условия не всегда могут быть проверены во время синтаксического анализа и потому обычно выделяются в отдельную фазу. Эта фаза компиляции подробно обсуждается в лекции 9.
Оптимизация кода

Основная цель фазы оптимизации (code optimization) заключается в преобразовании промежуточного представления программы в целях повышения эффективности результирующей объектной программы. Отметим, что существуют различные критерии эффективности, например, скорость исполнения или объем памяти, требуемый программе. Очевидно, что все преобразования, осуществляемые на фазе оптимизации, должны приводить к программе, эквивалентной исходной.
Некоторые оптимизации тривиальны, другие требуют достаточно сложного анализа программы. В лекции 11 и лекции 12 мы рассмотрим анализ потоков управления программы и анализ потоков данных. Затем в лекции 13 мы рассмотрим сам этап оптимизации программ и рассмотрим наиболее распространенные оптимизации:
- константные вычисления
- уменьшение силы операций
- выделение общих подвыражений
- чистка циклов и т.д.
Генерация кода

Наконец, по оптимизированной версии промежуточного представления генерируется объектная программа. Эту задачу решает фаза генерации кода (code generator). В лекции 14 мы изучим основные свойства целевой платформы.NET и рассмотрим процесс генерации кода для этой платформы. Влекции 15
мы рассмотрим более сложные алгоритмы генерации, использующие методику восходящего переписывания деревьев (BURS). Во многих случаях такой подход может значительно улучшить качество порождаемого кода.Помимо собственно генерации кода, на этом этапе необходимо решить множество сопутствующих проблем, например:
- распределение памяти, т.е. отображение имен исходной программы в адреса памяти
- распределение регистров, т.е. определение для каждой точки программы множества переменных, которые должны быть размещены в регистрах
- выбор такой последовательности записи значений в регистры, которая избавила бы от необходимости частой выгрузки значений из регистров, а затем повторной загрузки
|
|
|
