 |


Многомерные массивы. Работа с массивами и класс Arrays. Практика. Конвертор дня года в месяц и число. Кодовые точки Unicode и русские символы в исходных кодах и программах Java. JDK 1.6.
|
|
|
|
Многомерные массивы.
Вопрос: А если написать вот так?

Ответ: d11 – это двумерный массив, а k11 – одномерный массив. Если вы своих коллег особо не любите, то можете быть очень оригинальными. Попробуй догадаться и понять!
Работа с массивами и класс Arrays.
Пример:
| Текст программы: предполагается чтение размера массива с клавиатуры public class MaxArr { public static void main(String[] args) throws Exception { int n, i, a[]; n = Xterm. inputInt(" Введите длину массива n -> " ); a = new int[n]; for (i=0; i< n; i++) a[i] = Xterm. inputInt(" Введите a[" + i + " ] -> " ); int max = a[0]; for (i=1; i< n; i++) if (a[i] > max) max = a[i]; Xterm. println(" Максимальный элемент массива = " + max); } } |

|
Единственно, если возникнет вопрос, а как отсортировать массив, то тут я вам помогу. Смотрите. У вас любой массив. Возьмем для примера наш массив d1 + точка. И если вы будете думать, что здесь есть какие-то замечательные методы, которые уже для нас написаны и позволят что-то делать с массивом, то нет. Здесь нет ничего. Единственное, что здесь есть – это length (число элементов).

Вопрос: А вон тот список ниже?
Ответ: Это то, что от Object унаследовано. Это мы будем разбирать, это все впереди. Это общее для всех ссылочных типов.
Вопрос: Тогда где моя сортировка?
Ответ: Не здесь. Массив – это Array, и все вспомогательные методы находятся в классе Arrays. Точно также есть Collection, а есть Collections. Там все вспомогательные элементы. Вы пишете Arrays, бинарный поиск и т. д.
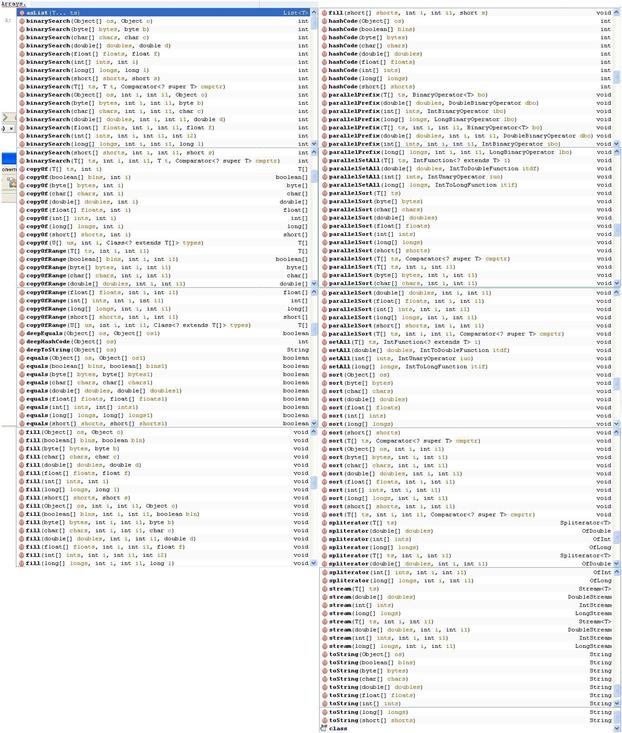
Вы спросите, и как она сортирует? Быстрой сортировкой (quick sort).
Практика
Конвертор дня года в месяц и число
Кодовые точки Unicode и русские символы в исходных кодах и программах Java. JDK 1. 6.
Достаточно много разработчиков ПО в действительности не имеют до конца четкого представления о наборах символов, кодировок, Unicode и сопутствующих материалах. Даже в настоящее время многими программами часто игнорируются встречающиеся преобразования символов, даже программами, которые, казалось бы, разработаны с помощью дружественных к Unicode Java технологиях. Зачастую беспечно используется для символов 8 битов, что делает невозможным разработку хороших многоязычных web-приложений. Данная статья является объединением рядов статей по вопросам кодировки Unicode, однако основополагающей стала переработанная статья Джоэла Сполски The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (08. 10. 2003).
|
|
|
История создания различных видов кодировок
Весь тот материал, который говорит о том, что " простой текст = ASCII = символы из 8 бит", является не корректным. Единственными символами, которые могли отображаться корректно при любых обстоятельствах, это были английские буквы без диакритических знаков с кодами от 32 до 127. Для этих символов существует код, названный ASCII, который был в состоянии представить все символы. Буква " A" имела бы код 65, пробелом был бы код 32, и т. п. Данные символы могли быть удобно сохранены в 7 битах. Большинство компьютеров в те дни использовало 8-битовые регистры, и таким образом вы не только могли хранить любой возможный символ ASCII, но еще и имели целый бит экономии, который, если у вас была такая блажь, вы могли использовать в ваших собственных целях. Коды меньше 32 назывались непечатными и использовались для управляющих символов, например, символ 7 заставлял ваш компьютер издать сигнал динамика, а символ 12 являлся символом конца страницы, заставляя принтер прокрутить текущий лист бумаги и загрузить новый.
Поскольку байты имеют восемь битов, то многие думали: " мы можем использовать коды 128-255 в наших собственных целях". Неприятность была в том, что для очень многих эта идея пришла почти одновременно, но у всех были свои собственные идеи относительно того, что должно размещаться на месте с кодами от 128 до 255. У IBM-PC было нечто, что стало известным как набор символов OEM, в котором было немного диакритических символов для европейских языков и набор символов для рисования линий: горизонтальные полоски, вертикальные полоски, уголки, крестики, и т. д. И вы могли использовать эти символы для того, чтобы делать элегантные кнопки и рисовать линии на экране, которые вы все еще можете увидеть на некоторых старых компьютерах. Например, на некоторых PC символ с кодом 130 показывался как e, но на компьютерах, проданных в Израиле, это была еврейская буква Gimel (? ). Если бы американцы посылали свои resume (резюме) в Израиль, они прибывали бы как r? sum?. Во многих случаях, как, например, в случае русского языка, было много различных идей относительно того, что делать с верхними 128 символами, и поэтому вы не могли даже надежно обмениваться русскоязычными документами.
|
|
|
В конечном счете, разнообразие кодировок OEM было сведено в стандарт ANSI. Стандарт ANSI, оговаривал, какие символы располагались ниже 128, эта область в основном оставалась той же, что и в ASCII, но было много различных способов обращаться с символами от 128 и выше в зависимости от того, где вы жили. Эти различные системы назвали кодовыми страницами. Так, например, в Израиле DOS использовал кодовую страницу с номером 862, в то время как греческие пользователи использовали страницу с номером 737. Они были одними и теми же ниже 128, но отличались от 128, где и находились все эти символы. Национальные версии MS-DOS поддерживали множество этих кодовых страниц, обращаясь со всеми языками, начиная с английского и заканчивая исландским, и было даже несколько " многоязычных" кодовых страниц, которые могли сделать Эсперанто и Галисийский (прим. пер.: галисийский язык относится к романской группе языков, распространён в Испании, носителей 4 млн. чел) на одном и том же компьютере! Но получить, скажем, иврит и греческий на одном и том же компьютере было абсолютно невозможно, если только вы не написали вашу собственную программу, которая показывала все, используя графику с побитовым отображением, потому что для еврейского и греческого требовались различные кодовые страницы с различными интерпретациями старших чисел.
|
|
|
Тем временем в Азии, принимая во внимание тот факт, что азиатские алфавиты имеют тысячи букв, которые никогда бы не смогли уместиться в 8 битов, эта проблема решалась запутанной системой DBCS, " двухбайтовый набор символов" (double byte character set), в котором некоторые символы сохранялись в одном байте, а другие занимали два. Было очень легко передвигаться по строке вперед, но абсолютно невозможно передвигаться назад. Программисты не могли использовать для перемещения вперед и назад s++ и s--, и вместо этого должны были вызывать специальные функции, которые знали, как иметь дело с этим беспорядком.
Тем не менее, большинство людей закрывало глаза на то, что байт был символом и символ был 8 битами и, пока вам не приходилось перемещать строку с одного компьютера на другой, или если вы не говорили больше, чем на одном языке, это работало. Но, конечно, как только массово стал использоваться Интернет, стало весьма обычным делом переносить строки с одного компьютера на другой. Хаос в этом вопросе был преодолен с помощью Unicode.
|
|
|
