 |


Unicode префикс \u и русские символы в исходных кодах
|
|
|
|
В языке Java для записи символов в формате Unicode существует специальный префикс \u, а следующие за ним четыре шестнадцатиричные цифры задают сам символ. Например, \u2122 – это символ торговой марки (™). Такая форма записи выражает символ любого алфавита с помощью цифр и префикса – символов, которые содержатся в стабильном диапазоне кодов от 0 до 127, который не затрагивается при перекодировке исходного кода. И, теоретически, в приложении или аплете на языке Java можно использовать любой символ в формате Unicode, однако будет ли он отображаться корректно на экране дисплея и, будет ли он отображаться вообще, зависит от многих факторов. Для аплетов имеет значение тип браузера, а для программ и аплетов имеет значение тип операционной системы и кодировка, в которой написан исходный код программы.
Например, на компьютерах, работающих под управлением американской версии системы Windows, с помощью языка Java невозможно отобразить японские иероглифы из-за вопроса интернационализации.
В качестве второго примера можно привести вполне частую ошибку программистов. Многие думают, что задание русских символов в Unicode формате с помощью префикса \u в исходном коде программы может решить проблему вывода русских символов при любых обстоятельствах. Ведь виртуальная машина Java переводит исходный код программы в Unicode. Однако прежде чем осуществить перевод в Unicode виртуальная машина должна знать, в какой кодировке написан исходный код вашей программы. Ведь вы можете написать программу и в кодировке Cp866 (DOS) и в Сp1251 (Windows), что типично для данной ситуации. В том случае, если вы не указали кодировки, виртуальная машина Java считывает ваш файл с исходным кодом программы в той кодировке, которая указана в системном свойстве file. encoding.
|
|
|
Однако вернемся к параметрам по умолчанию, и будем считать что file. encoding=Сp1251, а вывод на консоль производится в Cp866. Вот именно в этом случае выходит следующая ситуация: допустим у вас есть файл в кодировке Сp1251:
Файл MsgDemo1. java
public class MsgDemo1 { public static void main(String[] args) { String s = " \u043A\u043E" + " \u0434\u0438\u0440\u043E\u0432" + " \u043A\u0430"; System. out. println(s); } }И вы ожидаете, что на консоль выведется слово “кодировка”, однако получаете:
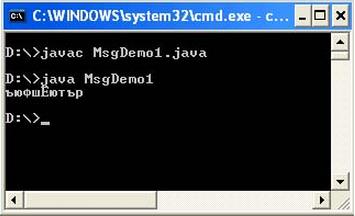
Дело в том, что коды с префиксом \u, перечисленные в программе действительно кодируют нужные кириллические символы в кодовой таблице Unicode, однако они рассчитаны на то, что исходный код вашей программы будет считан в кодировке Cp866 (DOS). По умолчанию, же в системных свойствах указана кодировка Сp1251 (file. encoding=Сp1251). Естественно, первое и неправильное, что приходит на ум – поменять кодировку файла с исходным кодом программы в текстовом редакторе. Но это ни к чему не приведет. Виртуальная машина Java все равно будет считывать ваш файл в кодировке Сp1251, а коды \u рассчитаны на Cp866.
Из этой ситуации есть три выхода. Первый вариант – использовать ключ -encoding на этапе компиляции и –Dfile. encoding на этапе запуска программы. В этом случае вы принудительно указываете виртуальной машине Java, чтобы она считывала файл с исходным кодом в заданной кодировке и выводила в заданной кодировке.

Как видно из вывода на консоли, при компиляции должен задаваться дополнительный параметр –encoding Cp866, а при запуске должен задаваться параметр –Dfile. encoding=Cp866.
Второй вариант заключается в том, чтобы перекодировать символы в самой программе. Он предназначен для восстановления верных кодов букв, если они были неверно проинтерпретированы. Суть метода проста: из полученных неверных символов, используя соответствующую кодовую страницу, восстанавливается исходный массив байтов. Затем из этого массива байтов, используя уже корректную страницу, получаются нормальные коды символов.
|
|
|
Для преобразования потока байт byte[] в строку String и обратно, в классе String есть следующие возможности: конструкторString(byte[] bytes, String enc), который получает на вход поток байт с указанием их кодировки; если кодировку опустить, то она будет принята кодировка по умолчанию из системного свойства file. encoding. Метод getBytes(String enc) возвращает поток байт, записанных в указанной кодировке; кодировку также можно опустить и будет принята кодировка по умолчанию из системного свойства file. encoding.
Пример:
Файл MsgDemo2. java
import java. io. UnsupportedEncodingException; public class MsgDemo2{ public static void main(String[] args) throws UnsupportedEncodingException { String str = " \u043A\u043E" + " \u0434\u0438\u0440\u043E\u0432" + " \u043A\u0430"; byte[] b = str. getBytes(" Cp866" ); String str2 = new String(b, " Cp1251" ); System. out. println(str2); }}Результат вывода программы:
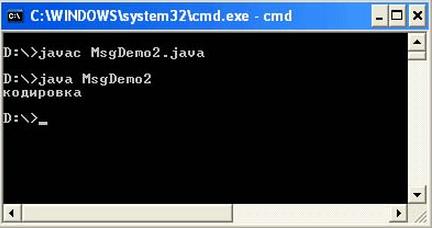
Этот способ является менее гибким в том случае, если вы ориентируетесь на то, что кодировка в системном свойстве file. encoding не изменится. Однако этот способ может стать самым гибким, если проводить опрос системного свойства file. encoding, и подставлять полученное значение кодировки при формировании строк в вашей программе. При использовании данного способа следует внимательно относиться к тому, что не все страницы выполняют однозначное преобразование byte < -> char.
Третий способ заключается в том, чтобы подобрать корректные Unicode коды для вывода слова “кодировка” из расчета, что файл будет считываться в кодировке по умолчанию – Cp1251. Для этих целей существует специальная утилита native2ascii.
Эта утилита входит в состав Sun JDK и предназначена для преобразования исходных текстов к ASCII-виду. При запуске без параметров, работает со стандартным входом (stdin), а не выводит подсказку по ключам, как остальные утилиты. Это приводит к тому, что многие и не догадываются о необходимости указания параметров (кроме, тех, кто заглянул в документацию). Между тем этой утилите для правильной работы необходимо, как минимум, указать используемую кодировку с помощью ключа -encoding. Если этого не сделать, то будет использована кодировка по умолчанию (file. encoding), что может несколько расходится с ожидаемой. В результате, получив неверные кода букв (из-за неверной кодировки), можно потратить много времени на поиск ошибок в абсолютно верном коде.
|
|
|
Следующий скриншот показывает различие в последовательностях Unicode кодов для одного и того же слова, если исходный файл будет считываться в кодировке Cp866 и в кодировке Cp1251.

Таким образом, если вы принудительно не указываете кодировки для виртуальной машины Java при компиляции и при запуске, а кодировкой по умолчанию (file. encoding) является Cp1251, то исходный код программы должен выглядеть следующим образом:
Файл MsgDemo3. java
public class MsgDemo3 { public static void main(String[] args) { String s = " \u0404\u00AE" + " \u00A4\u0401\u0430\u00AE\u045E" + " \u0404\u00A0"; System. out. println(s); } }
Использовав третий способ, можно сделать вывод: если кодировка файла с исходным кодом в редакторе совпала с кодировкой в системе, то сообщение “кодировка” появится в нормальном виде.
|
|
|
