 |


Основные методы класса String.
|
|
|
|
Основные методы класса String.
Чтобы вы просто задумались над тем насколько это понятие Юникод (UTF-16) сложное, мы возьмем для себя один тестовый пример. У меня огромное количество методов, которые позволяют со строками делать все что захочешь: и сравнивать, и складывать, находить в строке, какую-то подстроку, и разделять, и объединять, заменять и т. д. А мы возьмем самый простой вариант: размер строки (length).
length определяет длину строки.
А теперь вопрос: Какая единица измерения length?
Ответ: Вот у меня строка «abc». Я спрошу s1. length(). Что мне вернут? Ответ: 3. Единица измерения не в символах, и не в байтах. Длина строки – это количество кодовых точек.
Вопрос: А что такое кодовая точка?
Ответ: С этого и начинается изучение UTF-16.
Вопрос: Зачем сделали кодировку UTF-16?
Ответ: Для того чтобы каждый национальный алфавит получил свой набор кодов, чтобы я мог написать документ на многих языках. Потому что однобайтовая кодировка ASCII позволяет мне написать документ только на двух языках (один из них – латинский алфавит), у вас может быть французско-английский вариант.
Вопрос: А если я хочу французско-русско-английский?
Ответ: Нельзя. А в UTF-16 можно, потому что там каждый национальный алфавит получает свой набор кодов. Французский – отдельно, английский – отдельно, русский – отдельно и т. д.
Все национальные алфавиты. И все национальные алфавиты съели порядка 40000 кодов, а там 2 байта (или 65000 кодов).
Вопрос: Кто остался?
Ответ: Иероглифы. Сколько иероглифов в китайском, в японском? Много? По крайней мере, тот остаток в 25000 кодов из 65000 нам не хватит, потому что их порядка от 50000 до 100000 иероглифов. Так что 25000 – это копейки. Ничто туда не влезит. Так вот авторы Юникода в эти оставшиеся 25000 вбили абсолютно все символы, которые есть во всех книгах земного шара, начиная от клинописи и заканчивая придуманными языками. Даже еще осталось место. Если хотите пример придуманного языка – рунное письмо из Властелина Колец, клигонский.
|
|
|
В эти 25000 вбили полмиллиона символов. Вы спросите, а как? Легко. Что такое 25000? Если выдавать каждому код, то 25000 кодов и будет. А они сделали следующее. Берут иероглиф, и ему выдают не один байт, а два. Ему выдают два байта в сочетании со следующими двумя байтами. Из этого диапазона 25000 я беру первые два байта, и их первые два байта беру в сочетании, которые там дальше идут. Сколько у меня будет? 25000 я выдам. Потом я беру следующие два байта и в сочетании с оставшимися, следующие два байта и в сочетании с оставшимися. И получается резко увеличившийся диапазон.
Вопрос: Почему кодировка называется «двухбайтная»?
Ответ: Потому что в основе лежит двухбайтный код. Кодовая точка – это и есть двухбайтный код. Если это национальный алфавит, каждому символу национального алфавита дается один код, а иероглифу два кода. И если у меня будет строка «abc» -у меня три кодовых точки, а если у меня будет три иероглифа – то длина будет равна 6, потому что на каждый иероглиф две кодовых точки.
И если вы начнете с этим разбираться, то я рекомендую заглянуть в класс Character. Там вы столько увидите методов, которые позволяют определить это код, это первая часть кода и т. д.
Вот эта вся механика – работа с Unicode – она прописана на уровне класса Character, ну и в String тоже можно кое что увидеть.
И вы можете определить кодовую точку до, после, количество кодовых точек.
Вопрос: Для чего это все нужно?
Ответ: Ну мало ли. Может быть вы будете писать свой собственный конвектор из одной кодировки в другую.
Вопрос: Что есть хорошего в классе String? Что есть плохого в классе String?
|
|
|
Ответ:
Хорошее: Есть на все случаи жизни готовые методы. И ни в коем случае не надо пытаться их писать самостоятельно, потому что метод trim не удаляет пробелов.

Вы спросите, ну и что? Мы не сможем написать такой метод? А вы как думаете на всех платформах, где есть Java – пробелы и пробельные символы одинаковы или у них одинаковые коды? А если нет? А если где-то на какой-то платформе отличается набор пробельных символов от другой? Когда авторы реализовывали JDK – они для каждой платформы метод trim реализовали так, как он для данной платформы был корректен.
Если вы напишете свой собственный метод, который удаляет пробельные символы, то вы для какой платформы его напишете? Для своей любимой? Тогда на всех остальных он будет работать некорректно, и вы теряете переносимость кода.
Когда мы пишем свой собственный код, мы должны всегда думать. Был вопрос: Я могу из своего кода вызывать WinApi? Можете, но этот код будет работать только на Windows, когдая использую какие-то расширенные возможности – но мы резко теряем в понятиях кроссплатформенности.
Объект класса String является неизменяемым. Будучи созданным, любой объект класса String неизменяем, т. е. изменить, добавить, убавить, преобразовать нельзя. Вы спросите, а эти методы что делают? Они каждый раз создают новый объект. И опять же, в той же самой документации, где-то в самом начале это должно быть написано. Immutable string. Вы спросите «зачем»? Для скорости. Так что будьте аккуратны, потому что если вы начнете писать программу, которая постоянно меняет, манипулирует, изменяет строку, то это будет новые и новые и новые объекты и т. д. И значит огромное количество сборки мусора, которое можно было при другом алгоритме избежать.
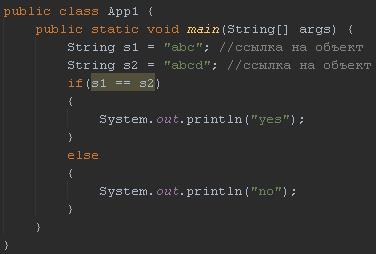
| run: no СБОРКА УСПЕШНО ЗАВЕРШЕНА (общее время: 2 секунды) |

| run: yes СБОРКА УСПЕШНО ЗАВЕРШЕНА (общее время: 0 секунд) |
Во втором случае компилятор видит, что вы пытаетесь создать две одинаковых строки. Он говорит зачем? Она же неизменяемая. Он создаст одну и установит все ссылки на нее. Оптимизация и скорости и памяти. Объекты класса String не изменяемы.
|
|
|
