 |


зависимостями по методу наименьших квадратов
|
|
|
|
случайной величины
1.1. Цель и задачи
Цель – изучить методику статистической обработки одномерной выборки случайной величины.
Задачи – освоить основные понятия (случайная величина, выборка, характеристики случайной величины), методику формулировки и проверки статистических гипотез, изучить требования к выборке и методику проверки их соблюдения, научиться определять достоверные статистические характеристики случайной величины.
1.2. Основные понятия и определения
Случайная величина — это переменная, которая принимает в результате опыта одно значение из множества исходов, причём появление того или иного значения этой величины до её измерения нельзя точно предсказать.
Все возможные значения случайной величины называют генеральной совокупностью. Если мы проведем n повторных измерений случайной величины Х, то есть получим n конкретных различных численных значений  , то этот результат эксперимента можно считать выборкой объема n из гипотетической генеральной совокупности результатов единичных измерений. Оценивая характеристики выборки, мы можем иметь представление о свойствах генеральной совокупности.
, то этот результат эксперимента можно считать выборкой объема n из гипотетической генеральной совокупности результатов единичных измерений. Оценивая характеристики выборки, мы можем иметь представление о свойствах генеральной совокупности.
Репрезентативная выборка – точно (достоверно) отражает свойства генеральной совокупности.Чтобы выборка правильно отражала основные свойства, присущие генеральной совокупности, она должна быть случайной, т.е. все объекты генеральной совокупности должны иметь равные шансы попасть в выборку. Для этого выборки формируются с помощью специальных методик. Репрезентативная выборка должна быть достаточной по объему для обеспечения необходимой точности определяемых показателей (характеристик).
|
|
|
Достоверная выборка не должна содержать грубые ошибки (промахи, не характерные значения реализации случайной величины).
Доверительная вероятность – вероятность того, что значение рассчитываемых оценочных характеристик для генеральной совокупности попадет в доверительный интервал. Чем больше доверительная вероятность, тем больше должен быть доверительный интервал.
Для оценки случайной величины используют характеристики положения и рассеивания.
Характеристики положения: математическое ожидание, мода и медиана.
М атематическое ожидание - число, вокруг которого сосредоточены значения случайной величины представляет абсциссу центра тяжести плоской фигуры, ограниченной кривой распределения и осью абсцисс. Математическое ожидание случайной величины x обозначается M(x). М атематическое ожидание непрерывной случайной величины Х равно  , а математическое ожидание дискретной случайной величины равно
, а математическое ожидание дискретной случайной величины равно  .
.
Модой дискретной случайной величины, обозначаемой Мо, называется ее наиболее вероятное значение, а модой непрерывной случайной величины – значение, при котором плотность вероятности максимальна.
Медианой непрерывной случайной величины Х называется такое ее значение Ме, для которого одинаково вероятно, окажется ли случайная величина меньше или больше Ме, т.е. Р(Х < Ме) = Р(X > Ме).
Характеристики рассеивания: дисперсия, среднее квадратическое отклонение и коэффициент вариации.
Дисперсия случайной величины характеризует степень разброса случайной величины около ее математического ожидания и представляет собой математическое ожидание квадрата ее отклонения: 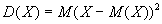 . Дисперсия случайной величины как характеристика разброса имеет одну неудобную особенность: ее размерность (из определения) равна квадрату размерности случайной величины
. Дисперсия случайной величины как характеристика разброса имеет одну неудобную особенность: ее размерность (из определения) равна квадрату размерности случайной величины 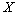 .
.
Средним квадратическим отклонением случайной величины называется арифметический корень из дисперсии, т.е.  .
.
|
|
|
Коэффициент вариации V[X] ‑ отношение стандартного отклонения σ[X] к математическому ожиданию M[X], выраженное в процентах или в долях (в расчетах).
Для оценки приведенных выше истинных характеристик случайной величины используют некоторые оценочные функции этих величин  , которые называются статистиками (или характеристиками). Значения статистик зависят от объема выборки и свойств случайной величины.
, которые называются статистиками (или характеристиками). Значения статистик зависят от объема выборки и свойств случайной величины.
Математическое ожидание М [X] оценивается выборочным средним
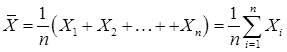 . (1.1)
. (1.1)
Дисперсия D[X] оценивается выборочной дисперсией
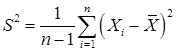 . (1.2)
. (1.2)
Оценочный коэффициент вариации вычисляется по формуле
 , (1.3)
, (1.3)
где S – оценочное значение среднего квадратического отклонения 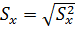 .
.
1.3. Задание
Для сформированной на компьютере выборки объемом (N=25) выполнить проверки соблюдения требований к выборке:
- проверить наличие грубых ошибок в выборке;
- проверить соблюдение требований о случайном характере выборки;
- проверить соблюдения требований о достаточности выборки;
- определить оценочные статистические характеристики случайной величины.
1.4. Рекомендации по выполнению задания
1. С помощью специальной программы в среде MathCAD (рис.1.1) смоделируем N=25 значений случайной величины. Варианты индивидуального задания задаются преподавателем или задаются параметры рассеивания условной случайной величины (табл. 1.1.)
| Моделирование условной выборки |
| Для вывода данных набрать команду X= |




Рис. 1.1 Программа моделирования условной выборки
2. Найдем статистические характеристики для полученной выборки
Выборочное среднее:
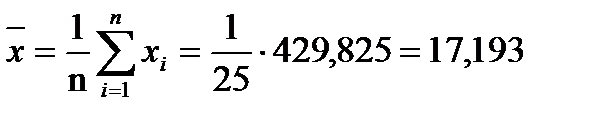 . (1.4)
. (1.4)
Выборочная дисперсия:
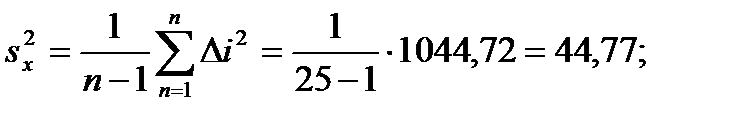 . (1.5)
. (1.5)
Среднее квадратическое отклонение:
 . (1.6)
. (1.6)
Таблица 1.1.
Данные для моделирования выборки на компьютере
| Вариант | Параметры | Вариант | Параметры | Вариант | Параметры | |||
| a | b | a | b | a | b | |||
| 1.75 | ||||||||
| 1.5 | 2.5 | |||||||
| 2.25 | ||||||||
| 2.5 | 3.5 | 2.75 | ||||||
| 3.2 |
3. Исключение грубых ошибок
Смоделированную на компьютере выборку представим в виде вариационного ряда, т.е. ряда упорядоченного по мере возрастания (колонка 3). Проанализируем наибольшее значение Хmax= 29,114 и наименьшее значение - Xmin=0,117. Если эти значения выделяются из приведенной совокупности, то их моно считать грубыми ошибками и исключить из выборки.
|
|
|
Проверку этого утверждения относительно Хmax= 29,114 выполним в следующем порядке:
3.1. Сформулируем основную и альтернативную статистические гипотезы:
H0: Хmax является грубой ошибкой;
H1: Хmax не является грубой ошибки.
3.2. Выбираем статистический критерий, который представляет собой отношение удаления подозреваемой величины Хmax= 29,114 от среднего значения  к среднему квадратическому отклонению и находим расчетное значение
к среднему квадратическому отклонению и находим расчетное значение
 (1.7)
(1.7)
3.3. Определяем критическое значение статистического критерия таблица 1 (приложения)
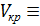 Vα=0.05; n=25 = 2,717.
Vα=0.05; n=25 = 2,717.
3.4. Сравниваем расчетное значение с критическим: так как Vp < Vкр, то Хmax не является грубой ошибкой, справедлива гипотеза H1.
| Таблица 1.2. Расчетная таблица. | |||||||
| № п/п | Выборочные значения | d i = x i+1-xi | di 
| ∆i= xi- 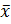
| ∆ i
| ||
| в порядке появления | в порядке возрастания | ||||||
| 10,723 | 0,117 | -5,66 | 32,01 | -6,47 | 41,86 | ||
| 16,381 | 10,353 | -4,06 | 16,50 | -0,81 | 0,66 | ||
| 20,4435 | 10,723 | 4,56 | 20,80 | 3,25 | 10,57 | ||
| 15,883 | 10,807 | -1,80 | 3,25 | -1,31 | 1,72 | ||
| 17,685 | 11,264 | -6,09 | 37,08 | 0,49 | 0,24 | ||
| 23,774 | 11,908 | 2,24 | 5,04 | 6,58 | 43,31 | ||
| 21,53 | 12,276 | -1,31 | 1,70 | 4,34 | 18,81 | ||
| 22,835 | 12,956 | 10,93 | 119,40 | 5,64 | 31,83 | ||
| 11,908 | 13,511 | 0,64 | 0,41 | -5,29 | 27,93 | ||
| 11,264 | 13,854 | -1,01 | 1,02 | -5,93 | 35,15 | ||
| 12,276 | 15,883 | -4,87 | 23,75 | -4,92 | 24,18 | ||
| 17,149 | 16,381 | 6,34 | 40,22 | -0,04 | 0,00 | ||
| 10,807 | 17,149 | 10,69 | 114,28 | -6,39 | 40,78 | ||
| 0,117 | 17,185 | -28,82 | 830,36 | -17,08 | 291,59 | ||
| 28,933 | 17,685 | 3,40 | 11,53 | 11,74 | 137,83 | ||
| 25,538 | 20,443 | 4,54 | 20,58 | 8,35 | 69,64 | ||
| 21,001 | 21,001 | 8,05 | 64,72 | 3,81 | 14,50 | ||
| 12,956 | 21,53 | -0,56 | 0,31 | -4,24 | 17,95 | ||
| 13,511 | 21,944 | -0,34 | 0,12 | -3,68 | 13,56 | ||
| 13,854 | 22,662 | -8,09 | 65,45 | -3,34 | 11,15 | ||
| 21,944 | 22,835 | 4,76 | 22,65 | 4,75 | 22,57 | ||
| 17,185 | 23,774 | -11,93 | 142,30 | -0,01 | 0,00 | ||
| 29,114 | 25,538 | 18,76 | 351,98 | 11,92 | 142,11 | ||
| 10,353 | 28,933 | -12,31 | 151,51 | -6,84 | 46,79 | ||
| 22,662 | 29,662 | ||||||
| ∑xi=429,825 | ∑di2=2076,96 | ∑Δi2=1044,72 | |||||
Проверяем, является ли Xmin грубой ошибкой.
|
|
|
H0: Xmin является грубой ошибкой
H1: Xmin не является грубой ошибки
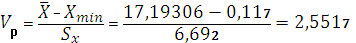 .
.
Так как Vp < Vкр, то Хmin так же не является грубой ошибкой.
4. Проверка случайности выборки
Проверку гипотезы о случайности выборки проведем на основе метода разностей. Сформируем новую случайную величину  как разницу между предшествующим и последующим значением (в порядке получения)
как разницу между предшествующим и последующим значением (в порядке получения)
3.1 Сформулируем гипотезу:
H0: выборка случайна;
H1: выборка неслучайна.
3.2. В качестве критерия возьмем отношение двух характеристик рассеивания
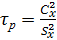 , (1.8)
, (1.8)
где 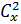 – характеристика рассеивания случайной величины, подсчитанное по методу разностей.
– характеристика рассеивания случайной величины, подсчитанное по методу разностей.
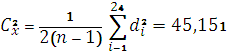 . (1.9)
. (1.9)
Расчетное значение критерия получим
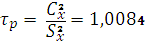 . (1.10)
. (1.10)
3.3. Критическое значение выбранного критерия для объема выборки n ≤ 20  находим по таблице 2 (приложения).
находим по таблице 2 (приложения).
Для выборки объемом больше n> 20 τ распределено по нормальному закону распределения с параметрами
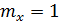 ;
;  . (1.11)
. (1.11)
В этом случае 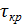 определяется из условия
определяется из условия
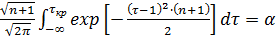 . (1.12)
. (1.12)
Для n=25, α=0,05 находим параметр нормирования ЗНР  по таблице 10 (приложения1) соответствующий уровню доверительной вероятности 0,95, получим
по таблице 10 (приложения1) соответствующий уровню доверительной вероятности 0,95, получим  , для 0,05
, для 0,05 
Искомое значение будет равно  . Значение
. Значение 
 подсчитываем по формуле (1.11)
подсчитываем по формуле (1.11)  . Тогда
. Тогда
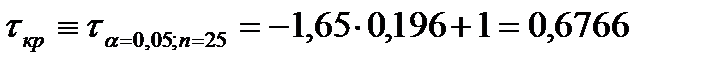 (1.13)
(1.13)
3.4. Вывод: так как 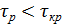 , то выборка случайна.
, то выборка случайна.
5. Проверка достаточности выборки
4.1.Рассчитаем значения оценочное значение среднего (1) для первых 3, 5, 10 и 25 значений и построим график зависимости среднего от объема выборки
| Объем выборки | ||||
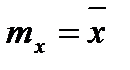
| 13,85 | 16,22 | 17,24 | 17,19 |
n
Рис. 1.2 Зависимость среднего от объема выборки n
Из графика видно, что среднее зависит от анализируемой величины и от объема выборки. Для достаточной выборки должно выполняться условие
 , (1.14)
, (1.14)
где Iдов – доверительный интервал для нахождения среднего значения; mx – математическое ожидание среднего значения; α – доверительная вероятность (в расчетах принимаем α=0,95).
Для соблюдения условия (1.14) должно выполняться условие
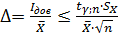 , (1.15)
, (1.15)
где Δ – относительная погрешность определения среднего; 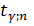 - коэффициент Стьюдента (таблица, приложения 1),
- коэффициент Стьюдента (таблица, приложения 1), 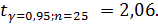
Значение относительной погрешности задается методикой испытаний или измерений (в расчетах принимаем Δ=10% или 0,1).
4.2. Минимально необходимый объем подсчитываем из условия равенства (1.15)
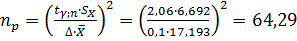 . (1.16)
. (1.16)
Полученное расчетное значение округляем до большего целого значения np =65.
Сравниваем полученное значение минимально необходимого числа опытов с объемом выборки и делаем вывод о достаточности имеющейся выборки. В нашем примере np =65 >N=25, следовательно выборка не достаточная по объему. В этом случае, необходимо провести дополнительную серию опытов.
|
|
|
4.3. Определение минимально необходимого числа измерений при разработке методики исследования.
В практической работе исследователя чаще всего встречается задача обоснования необходимого числа измерений при разработке рабочей методики испытаний. На этом этапе выборочных значений не имеем. Значения величин по формуле (1.16) найти не можем, так как каждое из них зависит от искомого объема выборки.
При выполнении задания необходимо самостоятельно разобраться и объяснить, как поступить в этом случае?
Контрольные вопросы:
1. Дать определение случайной величины и привести примеры из своей практики.
2. Как будут изменяться статистические характеристики случайной величины при увеличении и выборки?
3. Объяснить порядок проверки статистических гипотез.
4. Объяснить понятие статистического критерия.
5. Как сравнить два исследуемых идентичных процесса с разными средними и дисперсиями одного признака?
2. Статистическая обработка выборки большого объема
2.1.Основные понятия и определения
По мере увеличения объема выборки увеличивается риск ввода ошибочных данных. В практической статистике выборки более 30-40 значений относят к выборкам большого объема. Для определения статистических характеристик выборку в этом случае преобразуем в форму представления случайной величины в виде ряда распределения.
Ряд распределения – это таблица, ставящая в соответствие значения случайной величины и вероятности их появления.
| xi | x1 | x2 | …… | xn |
| pi | p1 | p2 | ……. | pn |
В статистике ряд распределения — представляет собой упорядоченное распределение единиц изучаемой совокупности по группам, разделяемым по определенному варьирующему признаку. В зависимости от признака, положенного в основу образования ряда распределения различают атрибутивные и вариационные ряды распределения.
Атрибутивными — называют ряды распределения, построенные по качественными признакам.
Сгруппированные данные в порядке возрастания или убывания значений количественного признака называются вариационным рядом. Количественный признак может иметь дискретные (целочисленные) значения или непрерывные значения. Непрерывные значения признака могут быть разбиты на интервалы и оценены частотой попадания выборочных значений в тот или иной интервал.
Ряд распределения характеризуется двумя элементами: вариантой (Х) и частотой (f). Варианта – это отдельное значение признака отдельной единицы или группы совокупности. Число, показывающее, сколько раз встречается то или иное значение признака, называется частотой. Сумма всех частот должна быть равна численности единиц всей совокупности. Если частота выражена относительным числом, то она называется частостью (опытной вероятностью).
2.2. Задание
Для анализа методики статистической обработки выборки большого объема необходимо определить по данным из 1-ого задания:
- преобразовать выборку объемом n = 25 (взять из 1-ой работы) в ряд распределения;
- определить статистические характеристики;
- сравнить значения статистических характеристик, полученных в 1-ом и 2-ом задании.
2.3.Выполнение задания
1. Задаемся числом интервалов m и разбиваем весь диапазон изменения случайной величины от min до max на равные участки. Процедура не формализованная. Существует достаточно много эмпирических соотношений. В частности в ряде учебников приводится формула Стерджесса 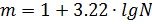 ; есть практические рекомендации: при n< 40-50 число интервалов выбирают в пределах 5…8, а для большего числа – 8…12. В нашем примере для выбора числа интервалов воспользуемся соотношением
; есть практические рекомендации: при n< 40-50 число интервалов выбирают в пределах 5…8, а для большего числа – 8…12. В нашем примере для выбора числа интервалов воспользуемся соотношением 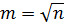 . Принимаем
. Принимаем  .
.
2. Подсчитаем ширину интервала
 . (2.1)
. (2.1)
3. Определим левые и правые границы для каждого интервала и заполним расчетную таблицу (столбцы 2 и 3). Левая граница первого интервала равна Xmin=0,117, правая граница будет равна Xmin+d. Для второго интервала левая граница будет равна правой границе первого интервала, правая граница равна Xmin+2d. Правая граница последнего интервала будет равна Xmax.
Таблица 2.1.
Преобразование выборки в ряд распределения
| № | Граница | 
| ni | pi | |
| левая | правая | ||||
| 0,117 | 5,9164 | 3,0167 | 0,04 | ||
| 5,9164 | 11,7158 | 8,8161 | 0,16 | ||
| 11,7158 | 17,5152 | 14,6155 | 0,36 | ||
| 15,5152 | 23,3146 | 20,4149 | 0,28 | ||
| 23,3146 | 29,114 | 26,2143 | 0,16 |
4. Определим середины интервалов  и запишем их в 4 столбец таблицы. Примем допущение 1 – случайная величина может принимать любое значение в пределах интервала, но в расчетах их будем относить к середине интервала.
и запишем их в 4 столбец таблицы. Примем допущение 1 – случайная величина может принимать любое значение в пределах интервала, но в расчетах их будем относить к середине интервала.
5. Подсчитаем число значений выборки, попадающие в каждый интервал ni. Значения запишем в 5 столбец таблицы и проверим условие: 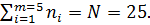
6. Определим опытные вероятности 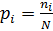 и записываем их значения в 6 столбец таблицы. Проверим условие нормирования, так как события представляют полную группу, то сумма опытных вероятностей должна равняться 1, т.е.
и записываем их значения в 6 столбец таблицы. Проверим условие нормирования, так как события представляют полную группу, то сумма опытных вероятностей должна равняться 1, т.е. 
Принимаем допущение 2 – вероятность попадания случайной величины в интервал различна для левой и правой границы, а в расчетах примем постоянной или распределенной по закону равномерной плотности. С учетом принятых допущений 1 и 2 получили ряд распределения.
7. Определим среднее значение
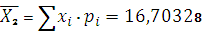 . (2.2)
. (2.2)
8. Определим дисперсию
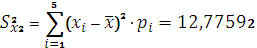 . (2.3)
. (2.3)
9. Сравним значения средних значений, полученных в первом и втором задании
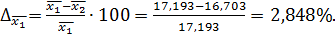 (2.4)
(2.4)
10. Сравним значения дисперсий, полученных в первом и втором задании
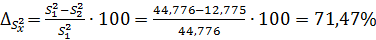 . (2.5)
. (2.5)
Анализ полученных данных показывает удовлетворительную разницу меду средними значениями 2,85%, а для дисперсии разницу существенная – 71,47%. В этом случае необходимо проводить дополнительные опыты. Если провести дополнительные опыты невозможно, используют поправку Шепарда  . Для приближения оценочной дисперсии
. Для приближения оценочной дисперсии  к истинному значению при ограниченном числе опытных данных к дисперсии прибавляют поправку Шепарда.
к истинному значению при ограниченном числе опытных данных к дисперсии прибавляют поправку Шепарда.
 . (2.6)
. (2.6)
Для уменьшения относительной погрешности можно попробовать увеличить число интервалов и (или) провести дополнительные опыты.
11. Опытные данные в графическом виде представляют в виде гистограммы и опытной функцией плотности распределения (многоугольник распределения, полигон распределения) (рис. 2.1).
Гистограмма - столбчатая диаграмма, высота столбиков которой соответствует частоте или относительной частоте (частости, опытной вероятности) попадания данных в каждый из интервалов.
Для построения гистограммы на горизонтальной оси в выбранном масштабе отметим границы соответствующих интервалов. На вертикальной оси выбирают масштаб в соответствии с максимальным значением опытной вероятности.
Строят столбчатую диаграмму, затем середины столбчатой диаграммы соединяют отрезками ломаной прямой и получают полигон распределения (рис. 2.1). Полигон представляет собой опытную функцию плотности распределения.
12. Опытная функция распределения (кумулята) показана на рис. 2.2. График накопленных относительных частот представляет собой опытную функцию распределения. Для его построения по горизонтальной оси, как и для гистограммы, отмечают границы интервалов, а по вертикальной оси (ординате) в интервале (0,1) откладывают накопленные частоты из условия:  . Так задаваясь x =5,9, вероятность будет равна p1=0,04; при
. Так задаваясь x =5,9, вероятность будет равна p1=0,04; при

Рис. 2.1. Гистограмма распределения и опытная функция плотности распределения
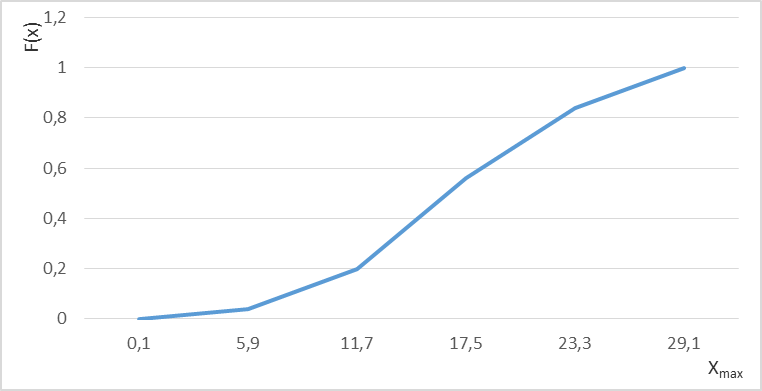
Рис. 2.2. Опытная функция распределения (кумулята)
x =11,7, ордината будет равна p1+p2, так для всех других значений границ интервалов.
Контрольные вопросы:
1. В какой форме представлена случайная величина?
2. Какие причины могут вызвать большую относительную погрешность определения оценочной дисперсии?
3. Как будут изменяться частости (опытные вероятности) при увеличении числа измерений?
4. Как будут изменяться частости (опытные вероятности) при увеличении числа интервалов?
5. Как будет изменяться полигон распределения при увеличении числа измерений?
3. Выбор закона распределения случайной величины
3.1. Цель и задачи
Цель – изучить методику выбора закона распределения для описания одномерной выборки случайной величины.
Задачи – освоить основные понятия (закон распределения, функция распределения, функция плотности распределения, вероятность согласия), методику выбора закона распределения, изучить свойства функции распределения, научиться определять критические значения критериев согласия Пирсона и Колмогорова и вероятность согласия опытных данных определенному закону распределения.
3.2. Основные понятия и определения
Закон распределения – математическая зависимость, связывающая значения случайной величины и вероятности ее определения 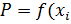 ). По характеру этой зависимости классифицируют теоретические законы распределения (закон нормального распределения; логарифмически нормальный, Вейбулла и другие).
). По характеру этой зависимости классифицируют теоретические законы распределения (закон нормального распределения; логарифмически нормальный, Вейбулла и другие).
Закон распределения используется для сглаживания статистических данных. Задача сглаживания заключается в том, чтобы подобрать теоретическую плавную кривую распределения, с той или иной точки зрения наилучшим образом описывающую данное статистическое распределение. Как правило, принципиальный вид теоретической кривой выбирается заранее из соображений, связанных с существом задачи, а в некоторых случаях просто с внешним видом статистического распределения.
Функцией распределения – называется функция F(X), описывающая вероятности появления значений случайной величины P(X≤x) меньше наперед заданного числа равной α.
 . (3.1)
. (3.1)
Функция распределения  любой случайной величины обладает следующими свойствами:
любой случайной величины обладает следующими свойствами:
1.  — функция неубывающая;
— функция неубывающая;
2. 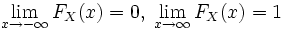 ;
;
3. непрерывна справа.
Функция плотности распределения случайной величины f(x) представляет собой первую производную функции распределения F(X)
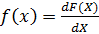 . ` (3.2)
. ` (3.2)
Близость опытных данных к функции распределения оценивается вероятностью согласия.
3.3. Задание
Для имеющихся данных (задание 2, таблица 2.1)
- проверить гипотезу о возможности использования закона нормального распределения (ЗНР) для сглаживания опытных данных по критерию Пирсона (χ2);
- проверить гипотезу о возможности использования закона нормального распределения для сглаживания опытных данных по критерию Колмогорова (l);
- определить по одному из критериев вероятность согласия опытных данных и теоретической функции распределения с опытными параметрами.
3.4. Порядок выполнения
1. Для ряда распределения формулируем гипотезу:
Н0: случайная величина Х подчинена закону нормального распределения)
Н1: случайная величина Х не подчинена закону нормального распределения.
2. Проверяем гипотезу по критерию Пирсона (χ2). Из таблицы 2.1 перенести значения середин интервалов Xi и опытные вероятности pi в таблицу 3.1. Накладываем теоретическую функцию плотности распределения на полигон распределения. Для этого вычислим параметр нормирования ti (3.3) для нормированного закона нормального распределения и запишем в столбец 4 таблицы 3.1. Параметры закона распределения a =  , b=
, b= 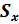 (среднее и среднее квадратическое берутся из задания 1)
(среднее и среднее квадратическое берутся из задания 1)
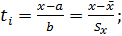 (3.3)
(3.3)
Определим значения теоретической функции плотности распределения для закона нормального распределения для середин интервалов  по значению ti (таблица 9, приложение 1).
по значению ti (таблица 9, приложение 1).
Подсчитаем расчетное значение критерия Пирсона
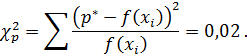
Расчетное значение критерия Пирсона является мерой расхождения теоретической функции плотности распределения для нормального закона распределения с опытными параметрами и опытной функцией распределения (полигоном распределения).
Таблица 3.1.
Расчетная таблица для критерия Пирсона
| № | Хi | Pi | ti | f(xi) | 
|
| 3,0167 | 0,04 | -2,118 | 0,04217 | 0,0001 | |
| 8,8161 | 0,16 | -1,252 | 0,18266 | 0,0028 | |
| 14,6155 | 0,36 | -0,385 | 0,37115 | 0,0003 | |
| 20,4149 | 0,28 | 0,481 | 0,35553 | 0,0160 | |
| 26,2143 | 0,16 | 1,35 | 0,16039 | 0,0004 |
Найдем критическое значение критерия Пирсона по таблице 4 (приложение 1) для уровня доверительной вероятности 0,95 (ошибка 0,05) и k=m -1=5-1=4.
Сравниваем расчетное значение критерия Пирсона с критическим значением и делаем вывод. Если 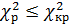 , то принимаем гипотезу о том, что случайная величина подчинена нормальному закону распределения, в противном случае отвергаем эту гипотезу.
, то принимаем гипотезу о том, что случайная величина подчинена нормальному закону распределения, в противном случае отвергаем эту гипотезу.
3. Проверка гипотезы по критерию Колмогорова А.Н. (λр). Накладываем теоретическую функцию распределения с опытными параметрами на опытную функцию (рис. 2.2). Для этого подсчитываем значения опытной функции распределения, соответствующее серединам интервалов 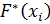
 ;
;
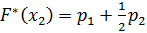 ;
;
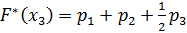 ;
;
 ;
;
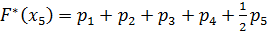 .
.
Полученные значения запишем в столбец 5 таблицы 3.2.
Определим значения теоретической функции распределения нормального закона распределения  и запишем в столбец 6 таблицы 3.2. Для этого по значениям
и запишем в столбец 6 таблицы 3.2. Для этого по значениям 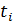 находим значения
находим значения  по таблице 10 (приложение 1). Необходимо учитывать особенность приведенной таблицы: при t < 0; F(x) = 0,5 – Ф(t), при t > 0; F(x) = 0,5 + Ф(t).
по таблице 10 (приложение 1). Необходимо учитывать особенность приведенной таблицы: при t < 0; F(x) = 0,5 – Ф(t), при t > 0; F(x) = 0,5 + Ф(t).
Таблица 3.2
Расчетная таблица для критерия Колмогорова
| № | Хi | Pi | ti | F*(xi) | Ft(xi) | Di = | F*- Ft | |
| 3,0167 | 0,04 | -2,118 | 0,02 | 0,0174 | 0,0026 | |
| 8,8161 | 0,16 | -1,252 | 0,12 | 0,1057 | 0,0143 | |
| 14,6155 | 0,36 | -0,385 | 0,38 | 0,3483 | 0,0317 | |
| 20,4149 | 0,28 | 0,481 | 0,7 | 0,6844 | 0,0156 | |
| 26,2143 | 0,16 | 1,35 | 0,92 | 0,9115 | 0,0085 |
Находим разницу между опытными и теоретическими значениями функции распределения по абсолютной величине
 (3.4)
(3.4)
Выбираем максимальное значение 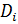 и определяем расчетное значение критерия Колмогорова А.Н.
и определяем расчетное значение критерия Колмогорова А.Н.
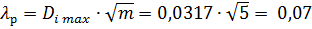 . (3.5)
. (3.5)
По таблице 5 (приложение 1) находим λкр = 0,52 или вероятность согласия 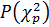 =1. Так как
=1. Так как 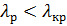 , следовательно, расхождение между теоретическими и опытными значениями не превышает допустимого значения значит принимаем гипотезу о том, что случайная величина подчинена нормальному закону распределения.
, следовательно, расхождение между теоретическими и опытными значениями не превышает допустимого значения значит принимаем гипотезу о том, что случайная величина подчинена нормальному закону распределения.
Контрольные вопросы:
1. Что оценивает расчетное значение критерия Пирсона?
2. Что оценивает расчетное значение критерия Колмогорова?
3. С какой вероятность делается вывод о справедливости проверяемой гипотезы?
4. Как определить вероятность согласия опытных данных и теоретического закона распределения?
5. Как выбрать лучший закон распределения для имеющихся опытных данных?
4. Оценка статистической взаимосвязи двух
случайных величин
5.1. Цель и задачи
Цель – изучить методику статистической оценки системы случайных величин.
Задачи – освоить основные понятия (система случайных величин, эллипс рассеивания, ковариация и корреляционный момент, коэффициент парной и множественной корреляции), методику оценки статистической взаимосвязи двух случайных величин, изучить виды взаимосвязи случайных величин, научиться определять коэффициент парной корреляции и оценивать его значимость.
5.2. Основные понятия и определения
В экспериментальных исследованиях, связанных с сельскохозяйственными объектами (растениями, животными, технологическими процессами) применительно к одному и тому же объекту рассматривают две и более связей.
Связь – совокупность зависимостей свойств одного элемента от свойств других элементов системы. Установить связь между двумя элементами – это значит выявить наличие зависимостей их свойств. Связи, взаимодействующие на основе законов природы, называют функциональными  . Для них характерно для любого x однозначное соотношение другой переменной y.
. Для них характерно для любого x однозначное соотношение другой переменной y.
На практике чаще всего встречаются такие соотношения между переменными, когда каждому значению признака x соответствует ни одно, а множество возможных значений признака y. Такие связи в отличие от функциональных связей, называются стохастическими (вероятностными) или корреляционными. При изучении таких связей возникают два основных вопроса – о тесноте связи и форме связи.
Для измерения тесноты связи используют специальный статистический метод, называемый корреляцией.
Для анализа линейной корреляции между x
